程序员备忘录

我是一名独立 blogger,有一个维护了很久的博客:峰间的云,里面有技术内容,也有非技术的内容,加上博客天然的按时间倒排序的特点,导致技术文章的组织缺少条理性,不方便汇总和回顾。因此,有了当前这个以类似书本的方式按章节撰写的博客。我将这本“书”叫做《程序员备忘录》。这本书记录了WEB程序员常用的知识点,方便温故知新,自我成长,书里有很多是自己的学习笔记,也有不少是对网上优质内容的“拿来主义”。
你可以通过以下方式阅读本书:
- 网页版。
- 安卓客户端。
- Windows客户端:绿色免安装,下载后点击直接运行。
意见与讨论请到这里提交:https://github.com/Yakima-Teng/memo/issues。
保护你的眼睛
本书提供单页HTML版本:https://www.orzzone.com/memo/single。读者可以直接利用浏览器的打印功能打印成 PDF 电子书放到水墨屏电纸书阅读器中阅读。以减少对眼睛的伤害。
版权说明
参考的书籍/文章已标注在正文当中或列于书本末处,但可能少列了。若您发现文字和图片有侵犯到您的权益,请务必联系我。
本书中引用的他人文章版权归原作者/平台所有,本人自己写的部分版权归本人所有。
本书仅用于个人私下学习。谢绝商用。
联系方式可在作者个人主页中找到:峰间的云。
目录
前端知识
因为本书的目标读者并非零基础,所以本章不会对基础语法、特性进行详细讲解。本章的目的主要是帮助大家迅速回忆基础知识,看是否有明显的缺漏需要补齐。对于本章,推荐的学习方式是:
- 快速浏览。
- 碰到某个关键词感觉比较模糊时,利用搜索引擎搜一下详细内容进行了解。
基础教程
网上有很多写得很好的教程:
JavaScript
JavaScript数据类型
- 基本数据类型(primitive data type):共 7 个,分别是:Undefined、Null、Boolean、Number、String、Symbol、BigInt。
- 对象数据类型
参考:BigInt
BigInt
bigint 是基础数据类型。通过在整数末尾添加 n,或者通过调用 BigInt(传入整数或字符串),可以创建一个 bigint 类型的值。
const previouslyMaxSafeInteger = 9007199254740991n;
// 十进制
const alsoHuge = BigInt(9007199254740991);
// 9007199254740991n
// 十进制
const hugeString = BigInt("9007199254740991");
// 9007199254740991n
// 十六进制
const hugeHex = BigInt("0x1fffffffffffff");
// 9007199254740991n
// 八进制
const hugeOctal = BigInt("0o377777777777777777");
// 9007199254740991n
// 二进制
const hugeBin = BigInt(
"0b11111111111111111111111111111111111111111111111111111",
);
// 9007199254740991n注意:
- 因为类型不同,
10n === 10的值为false(10n == 10的值为true)。 bigint值不支持用Math对象的原生方法进行处理。typeof 1n === "bigint";为true。typeof Object(1n) === "object";为true。
call、apply 和 bind
call:func.call(obj, param1, param2)将func函数应用于obj对象上,此时func函数内部的this指向obj对象。
apply:与call类似,只是所有要传入的数据都是以数组的形式放到第二个参数里的,如func.apply(obj, [arg1, arg2])。一个经典用法是来求数组中的最大数:Math.max.apply(null, [1, 3, 5]),另一个经典用法是用数组方法去处理非数组对象:[].slice.call(arguments, 1)。
bind:与call类似,但不会立即执行,而是生成了一个新函数,新函数的this指向的是我们传入的obj。
关于第一个参数
call、apply、bind的第一个参数,如果传了 null 或者 undefined 会被替换为全局对象(浏览器环境下的话就是 window 对象),如果传的是其他基础类型(比如1、'a'、false 等)则会被转换成基础类型对应的对象。
function test (...args) {
console.log(this)
console.log(args)
}
console.log('call')
test.call('a', 1, true, 'example', [], { a: 1 })
console.log('apply')
test.apply(false, [1, true, 'example', [], { a: 1 }])
console.log('bind')
/**
* 注意这里我们直接对 `bind` 生成的函数进行调用
* 并且在这个调用中也传入了几个新参数
*/
test.bind(0, 1, true, 'example', [], { a: 1 })(
'hello', 'world'
)执行结果见下图:
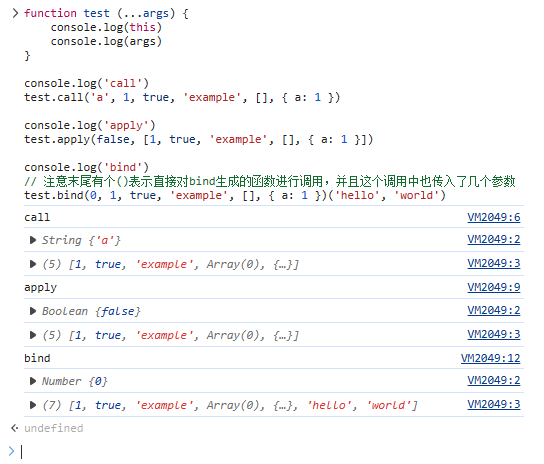
实现 bind
core-js 的实现
core-js 库中 bind 的实现见:https://github.com/zloirock/core-js/blob/master/packages/core-js/internals/function-bind.js
我们自己实现一个,注意:
- 调用
bind后生成的是一个新函数(新函数名为newFn)。 - 调用
bind时传的第二个及后续参数会和调用新函数newFn时传入的参数合并作为入参。 - 调用
bind时会指定newFn中的this指向。
Function.prototype.myBind = function () {
// 这里的 `this` 就是被 `bind` 处理前的函数
const func = this
let obj = arguments[0]
// 如果 `obj` 是 `undefined` 或 `null`,则替换成全局对象
if (typeof obj === 'undefined' || obj === null) {
obj = globalThis
}
// 如果不是对象类型,比如是 `false`、`1` 等,则包装成对象
if (typeof obj !== 'object') {
obj = new Object(obj)
}
let args = [].slice.call(arguments, 1)
return function () {
args = args.concat(Array.from(arguments))
const uniqueKey = Symbol('避免污染对象上的其他属性')
/**
* 使用 `symbol`作为 key,
* 可以避免影响其他人添加的可能同名的 key
*/
obj[uniqueKey] = func
const result = obj[uniqueKey](...args)
// 删除临时添加的属性,避免污染对象
delete obj[uniqueKey]
return result
}
}
function test (...args) {
console.log(this)
console.log(args)
console.log(arguments)
}
test.bind(0, 1, true, 'example', [], { a: 1 })(
'hello', 'world'
)
test.myBind(0, 1, true, 'example', [], { a: 1 })(
'hello', 'world'
)实现结果如下:
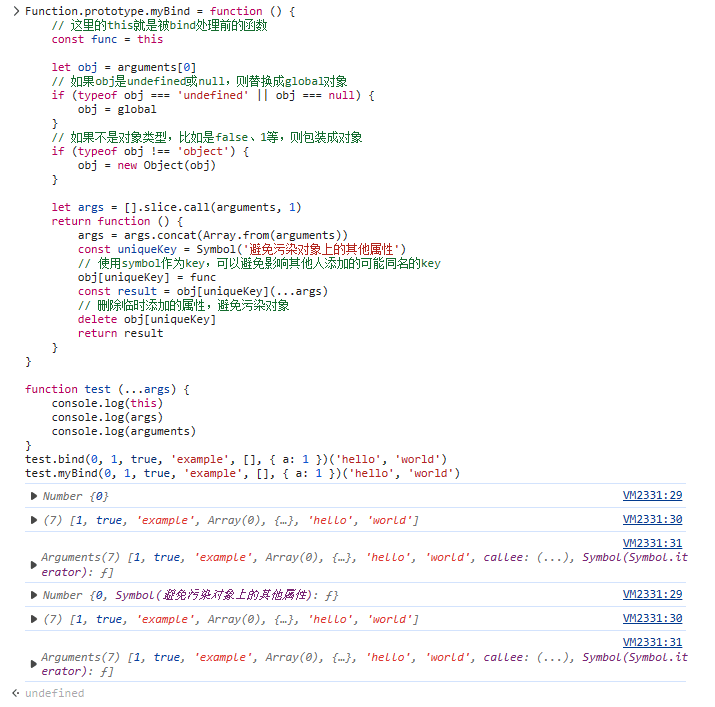
forEach、for-of、for-in 循环
// `forEach` 循环无法通过 `break` 或 `return` 语句进行中断
arr.forEach(function (elem) {
console.log(elem)
})
/**
* for-in循环实际上是为循环对象的可枚举(enumerable)属性而设计的,
* 也能循环数组,不过不建议,因为key变成了数字
*/
const obj = { a: 1, b: 2, c: 3 }
for (const p in obj) {
console.log(`obj.${p} = ${obj[p]}`)
}
// 上面的代码依次输出内容如下:
// obj.a = 1
// obj.b = 2
// obj.c = 3
/**
* for-of能循环很多东西,
* 包括字符串、数组、map、set、DOM collection等等
* (但是不能遍历对象,因为对象不是iterable可迭代的)
*/
const iterable = [1, 2, 3]
for (const value of iterable) {
console.log(value)
}基本上 for in 用于大部分常见的由 key-value 对构成的对象上以遍历对象内容。但是 for in 在遍历数组对象时并不方便,这时候用 for of 会很方便。
IIFE(Immediately-Invoked Function Expression)与分号
如果习惯写完一条语句后不加分号的写法,碰到需要写 IIFE(自执行函数)的时候容易踩到下面的坑:
const a = 1
(function () {})()上述代码会报错,因为第一行的 1 会和第二行一起被程序解析成 const a = 1(function () {})(),然后报错:Uncaught TypeError: 1 is not a function。
这时候可以这样写:
const a = 1
void function () {}()
// 或
const a = 1
void (function () {})()
// 或者下面这种方式,但据说会多一次逻辑运算
const a = 1
!function () {}()JS中除了使用 new 关键字还有什么方法可以创建对象?
可以通过 Object.create(proto, [, propertiesObject]) 实现。详见:Object.create()。
Object.create() 静态方法以一个现有对象作为原型,创建一个新对象。
const person = {
isHuman: false,
printIntroduction: function () {
console.log(
`I am ${this.name}. Am I human? ${this.isHuman}`
);
},
};
const me = Object.create(person);
// `name` 是 `me` 的属性,不是 `person` 的属性
me.name = 'Matthew';
// 继承过来的属性值可以被重写
me.isHuman = true;
// 打印内容: "I am Matthew. Am I human? true"
me.printIntroduction();用 Object.create() 实现类式继承
// Shape —— 父类
function Shape() {
this.x = 0;
this.y = 0;
}
// 父类方法
Shape.prototype.move = function (x, y) {
this.x += x;
this.y += y;
console.info("Shape moved.");
};
// Rectangle —— 子类
function Rectangle() {
Shape.call(this); // 调用父类构造函数。
}
// 子类继承父类
Rectangle.prototype = Object.create(Shape.prototype, {
/**
* 如果不将 `Rectangle.prototype.constructor`
* 设置为 `Rectangle`,
* 它将采用 `Shape`(父类)的 `prototype.constructor`。
* 为避免这种情况,
* 我们将 `prototype.constructor` 设置为 `Rectangle`(子类)。
*/
constructor: {
value: Rectangle,
enumerable: false,
writable: true,
configurable: true,
},
});
const rect = new Rectangle();
// true
console.log(
"rect 是 Rectangle 类的实例吗?",
rect instanceof Rectangle
);
// true
console.log(
"rect 是 Shape 类的实例吗?",
rect instanceof Shape
);
// 打印 'Shape moved.'
rect.move(1, 1);使用 Object.create() 的 propertyObject 参数
Object.create() 方法允许对对象创建过程进行精细的控制。实际上,字面量初始化对象语法可视为 Object.create() 的一种语法糖。使用 Object.create(),我们可以创建具有指定原型和某些属性的对象。请注意,第二个参数将键映射到属性描述符,这意味着你还可以控制每个属性的可枚举性、可配置性等,而这在 {} 字面量初始化对象语法中是做不到的。
o = {};
// 等价于:
o = Object.create(Object.prototype);
o = Object.create(Object.prototype, {
// foo 是一个常规数据属性
foo: {
writable: true,
configurable: true,
value: "hello",
},
// bar 是一个访问器属性
bar: {
configurable: false,
get() {
return 10;
},
set(value) {
console.log("Setting `o.bar` to", value);
},
},
});
/**
* 创建一个新对象
* 它的原型是一个新的空对象
* 并添加一个名为 'p',值为 42 的属性。
*/
o = Object.create({}, { p: { value: 42 } });使用 Object.create(),我们可以创建一个原型为 null 的对象。在字面量初始化对象语法中,相当于将 __proto__ 键赋值为 null。
o = Object.create(null);
// 等价于:
o = { __proto__: null };你可以使用 Object.create() 来模仿 new 运算符的行为。
function Constructor() {}
o = new Constructor();
// 等价于:
o = Object.create(Constructor.prototype);当然,如果 Constructor 函数中有实际的初始化代码,那么 Object.create() 方法就无法模仿它。
生成器函数与 yield 语句
function* hello (name) {
yield `hello ${name}!`
yield 'I am glad to meet you!'
if (0.6 > 0.5) {
yield `It is a good day!`
}
yield 'See you later!'
}
// Generator函数执行后会返回一个迭代器,通过调用next方法依次yield相应的值
const iterator = hello('Yakima')
iterator.next() // 返回{value: "hello Yakima!", done: false}
iterator.next() // 返回{value: "I am glad to meet you!", done: false}
iterator.next() // 返回{value: "It is a good day!", done: false}
iterator.next() // 返回{value: "See you later!", done: false}
iterator.next() // 返回{value: undefined, done: true}
iterator.next() // 返回{value: undefined, done: true}生成器函数(Generator)与常见的函数的差异:
- 通常的函数以
function开始,而生成器函数以function*开始; - 在生成器函数内部,
yield是一个关键字,和return有点像。不同点在于,所有函数(包括生成器函数)都只能return一次,而在生成器函数中可以yield任意次。yield表达式暂停了生成器函数的执行,然后可以从暂停的地方恢复执行。
常见的函数不能暂停执行,而生成器函数可以,这是两者最大的区别。
扩展运算符进行对象拷贝时是浅拷贝
在Babeljs.io Try it out上转义的结果是:
function _typeof(o) {
"@babel/helpers - typeof";
return _typeof = "function" == typeof Symbol && "symbol" == typeof Symbol.iterator
? function (o) {
return typeof o;
}
: function (o) {
return (
o
&& "function" == typeof Symbol
&& o.constructor === Symbol
&& o !== Symbol.prototype
)
? "symbol"
: typeof o;
},
_typeof(o);
}
function ownKeys(e, r) {
var t = Object.keys(e);
if (Object.getOwnPropertySymbols) {
var o = Object.getOwnPropertySymbols(e);
r && (o = o.filter(function (r) {
return Object.getOwnPropertyDescriptor(e, r).enumerable;
})), t.push.apply(t, o);
}
return t;
}
function _objectSpread(e) {
for (var r = 1; r < arguments.length; r++) {
var t = null != arguments[r] ? arguments[r] : {};
r % 2
? ownKeys(Object(t), !0).forEach(function (r) {
_defineProperty(e, r, t[r]);
})
: Object.getOwnPropertyDescriptors
? Object.defineProperties(e, Object.getOwnPropertyDescriptors(t))
: ownKeys(Object(t)).forEach(function (r) {
Object.defineProperty(e, r, Object.getOwnPropertyDescriptor(t, r));
});
}
return e;
}
function _defineProperty(obj, key, value) {
key = _toPropertyKey(key);
if (key in obj) {
Object.defineProperty(obj, key, {
value: value,
enumerable: true,
configurable: true,
writable: true
});
} else {
obj[key] = value;
}
return obj;
}
function _toPropertyKey(t) {
var i = _toPrimitive(t, "string");
return "symbol" == _typeof(i) ? i : String(i);
}
function _toPrimitive(t, r) {
if ("object" != _typeof(t) || !t) return t;
var e = t[Symbol.toPrimitive];
if (void 0 !== e) {
var i = e.call(t, r || "default");
if ("object" != _typeof(i)) return i;
throw new TypeError("@@toPrimitive must return a primitive value.");
}
return ("string" === r ? String : Number)(t);
}
var a = {
a: 1,
b: {
c: 3
},
c: 5
};
var d = _objectSpread({}, a);常用的异步处理方法
回调函数、事件监听、发布/订阅、Promise对象。
require, import
本文参考了以下文章:
一段时间以来,CommonJS 模块化方案一直是 Node.js 生态中的默认模块化方案。从 Node.js v8.5.0 开始,引入了 ES(ECMAScript) 模块化方案。这两种方案在执行时有一些差异。
- ES 模块化方案是 ECMAScript 语言的官方正式模块化方案,也是大多数浏览器原生支持的方案。使用
import和export来导入、导出模块。 - Node.js 默认采用 CommonJS 模块化方案。使用
require和module.exports/exports.<keyName>来导入和导出模块。 require()函数可以在程序的任何地方被调用,import则在文件头部被调用。- 一般用
require()引入的文件名使用 .js 作为文件名后缀,用import引入的文件名使用 .mjs 作为文件名后缀。(不绝对) require()得到的内容可以视作一个对象,里面有我们需要的属性或者方法。require()得到的是原始内容的一个拷贝(如果是对象的话就是浅拷贝),也就是重新又自己声明了一份变量,比如在b.js文件中声明了const { a } = require(./a.js)后在a.js文件中修改a的值也不会影响b.js中的a的值,两个文件中的a是不一样的。import则不会重新声明变量,在上面所述的场景中,a.js和b.js文件中的a一直都是同一个变量,值也始终相同。
require 引入 外部模块
require 除了支持通过传入一个本地文件路径来引用本地模块,也支持通过传入一个 web 地址来引入外部模块,比如这样:
const myVar = require('http://web-module.location');JS 中的 new
直接使用 {} 花括号可以很方便地创建一个对象,但是当我们想要创建很多对象时,如果还采用直接使用 {} 的方式就需要写很多冗余代码。JavaScript 提供了 new 关键字,我们可以对构造函数使用 new 操作符来创建一类相似的对象。
构造函数
构造函数在技术上是常规函数。不过有两个约定:
- 它们的命名通常以大写字母开头(语法上并未限制,但这是普遍的共识、约定)。
- 它们只能由
new操作符来执行(如果直接调用,这时它就不是构造函数了,而是常规函数)。
function User(name) {
this.name = name;
this.isAdmin = false;
}
const user = new User("Jack");
console.log(user.name); // Jack
console.log(user.isAdmin); // false当一个函数被使用 new 操作符执行时,它会经历以下步骤:
- 一个新的空对象被创建并赋值给
this。 - 函数体执行。通常它会修改
this对象,比如为其添加新的属性。 - 返回
this对象。
换句话说,执行 new User(...) 时,做的就是类似下面的事情:
function User(name) {
// this = {};(隐式创建)
// 添加属性到 this
this.name = name;
this.isAdmin = false;
// return this;(隐式返回)
}故 const user = new User("Jack") 可等价为以下代码:
const user = {
name: "Jack",
isAdmin: false
};现在,如果我们想创建其他用户,我们可以调用 new User("Ann")、new User("Alice") 等。代码量比每次都使用 {} 字面量的方式去创建要少,而且更易阅读。
这就是构造器的主要目的 —— 实现可重用的对象创建代码。
提示
从技术上讲,任何函数(除了箭头函数,它没有自己的 this)都可以用作构造器。即可以通过 new 来运行。“首字母大写”是一个共同的约定,以明确表示一个函数将被使用 new 来运行。
new.target
在一个函数内部,我们可以使用 new.target 属性来检查它是否被使用 new 关键字进行调用了。
常规调用时,它为 undefined。使用 new 调用时,则等于该函数:
function User() {
console.log(new.target);
console.log(new.target === User);
}
// 直接调用(不使用 `new` 关键字):
User(); // undefined, false
// 使用 `new` 关键字调用
new User(); // function User { ... }, true我们也可以让常规调用和使用 new 关键字调用做相同的工作,像这样:
function User(name) {
if (!new.target) {
return new User(name);
}
this.name = name;
}
const john = User("John");
console.log(john.name);这种方法有时被用在库中以使语法更加灵活。这样其他人在调用函数时,无论是否使用了 new,程序都能如期工作。
不过,到处都使用它并不是一件好事,因为省略了 new 使得很难直观地知道代码在干啥。而通过使用 new 关键字,我们都知道代码正在创建一个新对象。
构造函数的 return
通常,构造器函数内没有 return 语句。它们的任务是将所有必要的东西写入 this,并自动返回 this。
但是,如果构造器函数内有 return 语句,那么:
- 如果
return返回的是一个对象(不含null),则返回这个对象,而不是this。 - 如果
return返回的是一个原始类型(包括null),则忽略return语句,继续返回this。
换句话说,带有对象的 return 语句返回该对象,其他情况下都返回 this。
例如,这里 return 通过返回一个对象覆盖了 this:
function BigUser() {
this.name = "小明";
return { name: "小王" };
}
console.log(new BigUser().name); // 小王这里有一个 return 为 undefined 的例子(或者我们可以在它之后放置一个原始类型,结果是一样的):
function SmallUser() {
this.name = "小小王";
return;
}
console.log(new SmallUser().name); // 小小王通常构造器函数里都是没有 return 语句的,这里只做了解即可。
省略括号
顺便说一下,如果没有参数,我们可以省略 new 后的括号:
const user = new User;
// 等同于
const user = new User();这里省略括号不是一种好风格,但是语法规范上是允许的。
构造器中的方法
使用构造函数来创建对象有很大的灵活性。构造函数可能有一些函数入参,这些参数定义了如何构造对象。
当然,我们不仅可以在 this 上添加属性,还可以添加方法。
function User(name) {
this.name = name;
this.sayHi = function () {
console.log(`我的名字是: ${this.name}`);
};
}
const user = new User("李白");
user.sayHi(); // 我的名字是李白手写一个 new
问题描述
由于 new 是 JavaScript 中的关键字,我们不可能另外实现一个自己的关键字。所以这里要求我们实现一个函数 myNew,要求:myNew(Person, '李白') 等价于 new Person('李白')。
具体实现
function myNew() {
// 1、创建一个空对象
const obj = {}
// 获取构造方法(并将其从 `arguments` 中移出)
const constructor = [].shift.call(arguments)
// 2、将新对象的原型指向构造方法的 `prototype` 对象上
obj.__proto__ = constructor.prototype
/**
* 3、获取到构造方法的返回值
* 如果原先构造方法有返回值,且是对象,
* 那么原始的 `new` 会把这个对象返回出去
* (基本类型会忽略)
*
* 原始 `arguments` 的第一个参数已经在前面被 `shift` 了,
* 所以剩下的参数全都是构造方法需要的值
*/
const ret = constructor.apply(obj, arguments)
// `(ret || obj)` 是为了判断 `null`,当为 `null` 时,也返回新对象
return typeof ret === 'object' ? (ret || obj) : obj
}使用
function Person(name, age) {
this.name = name
this.age = age
}
const p = myNew(Person, 'cheny', 28)
// true
console.log(p instanceof Person);JavaScript 中的 this
普通函数的 this 指向
这里说的“普通函数”指箭头函数以外的函数。
在绝大多数情况下,函数的调用方式决定了 this 的值(运行时绑定)。
写出下面代码的执行结果:
// 当前位于全局作用域下
function testObject () {
alert(this)
}
testObject()上题的答案:在chrome中会弹出 [object Window]。
this 关键字是函数运行时自动生成的一个内部独享对象,只能在函数内部使用,总指向调用它的对象。
根据不同的使用场合,this 有不同的值,主要分以下几种情况:
- 默认绑定。
- 隐式绑定。
new绑定。- 显示绑定。
默认绑定
全局环境中定义 person 函数,内部使用 this 关键字。
var name = 'Jenny';
function person() {
return this.name;
}
// Jenny
console.log(person());上述代码输出 Jenny,原因是调用函数的对象在游览器中为 window,因此 this 指向 window,所以输出 Jenny。
注意:
严格模式下,不能将全局对象用于默认绑定,this 会绑定到 undefined,只有函数运行在非严格模式下,默认绑定才能绑定到全局对象。
隐式绑定
函数还可以作为某个对象的方法调用,这时 this 就指这个上级对象。
function test() {
console.log(this.x);
}
const obj = {};
obj.x = 1;
obj.m = test;
obj.m(); // 1下面这段代码中包含多级对象,注意 this 指向的只是它上一级的对象 b (由于 b 内部并没有属性 a 的定义,所以输出 undefined。)。
const o = {
a: 10,
b: {
fn: function() {
console.log(this.a); // undefined
}
}
}
o.b.fn();再举一种特殊情况:
const o = {
a: 10,
b: {
a: 12,
fn: function() {
console.log(this.a); // undefined
console.log(this); // window
}
}
}
const j = o.b.fn;
j();在上面的例子中,this 指向的是 window,这里的大家需要记住,this 永远指向的是最后调用它的对象,虽然fn 是对象 b 的方法,但是 fn 赋值给 j 时并没有执行,所以最终指向 window。
new 绑定
通过构建函数 new 关键字生成一个实例对象时,this 指向这个实例对象。
function Test() {
this.x = 1;
}
const obj = new Test();
obj.x // 1上述代码之所以会输出 1,是因为 new 关键字改变了 this 的指向。
这里再列举一些特殊情况:
new 过程遇到 return 一个对象(不包括 null),此时 this 指向返回的对象:
function fn() {
this.user = 'xxx';
return {};
}
const a = new fn();
console.log(a.user); // undefined如果 return 一个基础类型的值(包括 null),则 this 指向实例对象:
function fn() {
this.user = 'xxx';
return 1;
}
const a = new fn;
console.log(a.user); // xxx注意的是 null 虽然也是对象,但是此时 this 仍然指向实例对象:
function fn() {
this.user = 'xxx';
return null;
}
const a = new fn;
console.log(a.user); // xxx显示修改
apply、call、bind是函数的几个方法,作用是改变函数的调用对象。它的第一个参数就表示改变后的调用这个函数的对象。因此,这时 this 指的就是这第一个参数。
const x = 0;
function test() {
console.log(this.x);
}
const obj = {};
obj.x = 1;
obj.m = test;
obj.m.apply(obj) // 1匿名函数的 this
匿名函数里的 this 指向 window。
// 等价于 `window.name = 'The Window'`
var name = "The Window";
var object = {
name : "My Object",
getNameFunc : function() {
return function() {
return this.name;
};
}
};
// 输出为 `The Window`
alert(object.getNameFunc()());箭头函数的 this 指向
大部分情况下,this 总是指向调用该函数的对象。但对箭头函数而言却不是这样的,箭头函数里的 this 是根据外层(函数或者全局)作用域(词法作用域)来决定的。
箭头函数体内的 this 对象,就是定义该函数时所在的作用域指向的对象,而不是使用时所在的作用域指向的对象。
下面是普通函数的列子:
// 其实是window.name = 'window'
var name = 'window';
var A = {
name: 'A',
sayHello: function() {
console.log(this.name)
}
}
// 输出 `A`
A.sayHello();
var B = {
name: 'B'
}
// 输出 `B`
A.sayHello.call(B);
/**
* 不传参数指向全局 `window` 对象,
* 输出 `window.name` 也就是 `'window'`
*/
A.sayHello.call();从上面可以看到,sayHello 这个方法是定义在 A 对象中的,但是当我们使用 call 方法,把其指向 B 对象后,最后输出了 B;可以得出,sayHello 的 this 只跟使用时的调用对象有关。
改造一下:
var name = 'window';
var A = {
name: 'A',
sayHello: () => {
console.log(this.name)
}
}
// 还是以为输出 `A`? 错啦,其实输出的是 `window`
A.sayHello();我相信在这里,大部分同学都会出错,以为 sayHello 是绑定在 A 上的,但其实它绑定在 window 上的,那到底是为什么呢?
一开始,我重点标注了该函数所在的作用域指向的对象,作用域是指函数内部,这里的箭头函数(也就是 sayHello)所在的作用域其实是最外层的 js 环境,因为没有其他函数包裹;然后最外层的 js 环境指向的对象是 window 对象,所以这里的 this 指向的是 window 对象。
那如何改造成永远绑定A呢:
var name = 'window';
var A = {
name: 'A',
sayHello: function() {
var s = () => console.log(this.name)
// 返回箭头函数 `s`
return s
}
}
var sayHello = A.sayHello();
// 输出 `A`
sayHello();
var B = {
name: 'B'
}
// 输出 `A`
sayHello.call(B);
// 输出 `A`
sayHello.call();OK,这样就做到了永远指向 A 对象了,我们再根据该函数所在的作用域指向的对象来分析一下:
- 该函数所在的作用域:箭头函数
s所在的作用域是sayHello,因为sayHello是一个函数。 - 作用域指向的对象:
A.sayHello指向的对象是A。
最后是使用箭头函数其他几点需要注意的地方
- 不可以当作构造函数,也就是说,不可以使用
new命令,否则会抛出一个错误。 - 不可以使用
arguments对象,该对象在函数体内不存在。可以用...rest入参代替((...rest) => { console.log(rest); })。 - 不可以使用
yield命令,因此箭头函数不能用作 生成器(Generator)函数。
再来看一个例子:
var fullname = 'a'
var obj = {
fullname: 'b',
prop: {
fullname: 'c',
getFullname: () => {
return this.fullname;
}
}
}
// 打印 'a'
console.log(obj.prop.getFullname())
var test = obj.prop.getFullname
// 打印 'a'
console.log(test())var fullname = 'a'
function hello () {
var fullname = 'd'
var obj = {
fullname: 'b',
prop: {
fullname: 'c',
getFullname: () => {
return this.fullname;
}
}
}
// 打印 'a'
console.log(obj.prop.getFullname())
var test = obj.prop.getFullname
// 打印 'a'
console.log(test())
}
hello()var fullname = 'a'
function hello () {
var fullname = 'd'
var obj = {
fullname: 'b',
prop: {
fullname: 'c',
getFullname: () => {
return this.fullname;
}
}
}
// 打印 undefined
console.log(obj.prop.getFullname())
var test = obj.prop.getFullname
// 打印 undefined
console.log(test())
}
const d = new hello()var fullname = 'a'
function hello () {
this.fullname = 'f'
var fullname = 'd'
var obj = {
fullname: 'b',
prop: {
fullname: 'c',
getFullname: () => {
return this.fullname;
}
}
}
// 打印 'f'
console.log(obj.prop.getFullname())
var test = obj.prop.getFullname
// 打印 'f'
console.log(test())
}
const d = new hello()看一个普通函数的例子:
const obj = {
count: 10,
doSomethingLater() {
setTimeout(function () {
// 这是一个匿名函数,是在 window 作用域下执行的
this.count++;
console.log(this.count);
}, 300);
},
};
// 打印 `NaN`,因为 window 对象上没有 `count` 属性
obj.doSomethingLater();如果改成箭头函数:
const obj = {
count: 10,
doSomethingLater() {
// 该方法将 `this` 绑定到 `obj` 上下文中
setTimeout(() => {
/**
* 由于箭头函数内部不会自己绑定 `this`,
* `setTimeout` 函数也没有创建 `this` 绑定,
* 所以外部的 `obj` 上下文会被用作 `this`
*/
this.count++;
console.log(this.count);
}, 300);
},
};
// 打印 `11`
obj.doSomethingLater();- 参考:
JavaScript 中常用函数的实现
判断 JavaScript 全局变量是否存在
if (typeof localStorage !== 'undefined') {
// 此时访问localStorage不会出现引用错误
}或者
// 浏览器端全局处 `window`/`this`/`self` 三者彼此全等
if ('localStorage' in self) {
// 此时访问 `localStorage` 绝对不会出现引用错误
}注意二者的区别:
var a // 或 var a = undefined
'a' in self // true
typeof a // 'undefined'- 在全局作用域下定义
var a = undefined或者var a相当于是给window对象添加了a属性,但是未赋值,即window.a === undefined为true。 typeof a就是返回其变量类型,未赋值或者声明类型为undefined的变量,其类型就是undefined
const、let 与 var
全局作用域下通过 const 或 let 定义一个变量时,并不会在 window 上挂载该对象,这是与 var 表现不同之处。
判断 2 个对象是否相等(不是相同)
前提假设
不是只根据引用地址来判断,只要两个对象的键完全一致且同名键对应的值也“相等”,就认为这两个对象是相等的,比如分开创建的 { a: 1 } 和 { a: 1 },被认为是相等的两个对象。
具体实现
function isObjectEqual (obj1, obj2) {
if (typeof obj1 !== 'object' || typeof obj2 !== 'object') {
return obj1 === obj2
}
// 如果两个对象指向的是同一个引用地址,则为相同对象
if (obj1 === obj2) {
return true
}
const keys1 = Object.keys(obj1)
const keys2 = Object.keys(obj2)
if (keys1.length !== keys2.length) {
return false
}
if (keys1.length === 0) {
return true
}
for (let i = 0, len = keys1.length; i < len; i++) {
const key = keys1[i]
if (!isObjectEqual(obj1[key], obj2[key])) {
return false
}
}
return true
}实现 assign
function assign () {
const args = Array.from(arguments)
const target = args.shift()
if (!target || typeof target !== 'object') {
throw new TypeError('入参错误')
}
const objects = args.filter((obj) => typeof obj === 'object')
objects.forEach((obj) => {
for (const key in obj) {
if (obj.hasOwnProperty(key)) {
target[key] = obj[key]
}
}
})
return target
}merge 合并 2 个对象的可枚举属性
合并对象的可枚举的属性/方法到指定对象
/**
* 判断是否是非空对象
* @param val {any}
* @returns {boolean}
*/
function isObject(val) {
return (
typeof val !== 'null' &&
({}).toString.call(val).slice(8, -1).toLowerCase() === 'object'
)
}
function merge(target, obj) {
for (const p in obj) {
if (!obj.hasOwnProperty(p)) {
return
}
if (isObject(target[p]) && isObject(obj[p])) {
merge(target[p], obj[p])
return
}
target[p] = obj[p]
}
return target
}快速填充数字数组
假设你需要一个数组,数据长度为100,数组元素依次为0、1、2、3、4...98、99。该如何实现呢?直接写个for循环当然是可以的。不过这里有更方便的方法。
Array.from(Array(100).keys())或者
[...Array(100).keys()]如果你想要直接从 1 开始到 100,可以用 Array.from 方法实现(下面这种传参方法不太常见,第二个参数是一个 map function,可以对第一个参数传进去的类数组对象或者可迭代对象进行处理):
Array.from的语法如下:
Array.from(arrayLike)
Array.from(arrayLike, mapFn)
Array.from(arrayLike, mapFn, thisArg)所以,可以这么写:
Array.from({ length: 100 }, (_, i) => i + 1)注意,上面的例子里可以认为 { length: 100 } 是一个类数组。
[原创]不使用内置函数处理时间戳
要求
实现一个函数,该函数入参为一个时间戳,返回 YYYY:MM:DD HH:mm:ss 格式的字符串。不允许使用 Date 对象的内置方法。
已知:
- 时间戳是指格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒(北京时间 1970 年 01 月 01 日 08 时 00 分 00 秒)起至现在的总秒数。
- 普通闰年:公历年份是 4 的倍数,且不是 100 的倍数的,为闰年(如 2004 年、2020 年等就是闰年)。
- 世纪闰年:公历年份是整百数的,必须是400的倍数才是闰年(如 1900 年不是闰年,2000 年是闰年)。
- 1、3、5、7、8、10、12 月每月 31 天。
- 4、6、9、11 月每月 30 天。
实现
function toDateStr (ts) {
// 1 天的毫秒数
const tsDay = 24 * 60 * 60 * 1000
// 1 小时的毫秒数
const tsHour = 60 * 60 * 1000
// 1 分钟的毫秒数
const tsMin = 60 * 1000
// 1 秒的毫秒数
const tsSecond = 1000
let remaining = ts
// 天数
const days = Math.floor(remaining / tsDay)
remaining -= days * tsDay
// 小时数
const hours = Math.floor(remaining / tsHour)
remaining -= hours * tsHour
// 分钟数
const mins = Math.floor(remaining / tsMin)
remaining -= mins * tsMin
// 秒数
const seconds = Math.floor(remaining / tsSecond)
// 将天数转换成年和月
let years = 1970
let months = 0
let daysInLastMonth = 0
// 统计过的天数
let numOfDays = 0
while (numOfDays < days) {
// 2 月份
let daysInFebruary = 28
if (years % 400 === 0) {
daysInFebruary = 29
}
if (years % 100 !== 0 && years % 4 === 0) {
daysInFebruary = 29
}
// 各个月份的天数
const arrMonthAndDays = [
31, daysInFebruary, 31, 30, 31,
30, 31, 31, 30, 31,
30, 31,
]
for (const daysInMonth of arrMonthAndDays) {
/**
* 注意这里是小于,不是小于等于,
* 因为是从 1970 年 1 月【1 日】开始计算的,
* 过 30 天就是 1 月 31 日,过 31 天已经是 2 月份了
*/
if (days - numOfDays < daysInMonth) {
daysInLastMonth = days - numOfDays
numOfDays += days - numOfDays
break
}
months++
numOfDays += daysInMonth
}
if (numOfDays < days) {
// 下一个年份
years++
months = 0
}
}
/**
* 因为时间戳是从 1970 年 1 月 1 日开始计时的,
* 所以误差 1 天实际对应的是 2 号,
* 所以我们最终算出来的误差天数需要加 1
*/
return [
`${years}:${months + 1}:${daysInLastMonth + 1}`,
`${hours}:${mins}:${seconds}`
].join( )
}[原创]三行代码实现函数柯里化
实现一个函数,用于将目标函数柯里化
柯里化之前的效果:
// 柯里化之前
function add(a, b, c, d, e) {
console.log(a + b + c + d + e)
}
add(1, 2, 3, 4, 5)实现一个柯里化函数 curry,使得下面 curryAdd(1)(2)(3)(4)(5) 的计算结果与上方 add(1, 2, 3, 4, 5) 一致:
function curry() {}
const curryAdd = curry(add)
console.log(curryAdd(1)(2)(3)(4)(5)) // 输出:15实现方案
判断当前传入函数的参数个数 (args.length) 是否大于等于原函数所需参数个数 (fn.length) :
- 如果是,则执行当前函数;
- 如果否,则返回一个新函数,用于继续接收更多的参数。
注意,这里我们的原函数是指如下这个函数(fn.length为 5,因为有 a、b、c、d、e 一共 5 个参数):
function add(a, b, c, d, e) {
console.log(a + b + c + d + e)
}实现方案如下:
function curry(fn, ...args) {
// 函数的参数个数可以直接通过函数的 `.length` 属性来访问
return args.length === fn.length
? fn(...args)
: (...newArgs) => curry(fn, ...args, ...newArgs)
}
// 使用
function add(a, b, c, d, e) {
console.log(a + b + c + d + e)
}
const curryAdd = curry(add)
console.log(curryAdd(1)(2)(3)(4)(5)) // 输出:15Closure 闭包
闭包(closure)指有权访问另一个函数作用域中变量的函数。
闭包的作用:
- 延伸变量作用域范围,读取函数内部的变量。
- 让这些变量的值始终保持在内存中。
闭包案例1
function fn1() {
var num = 10;
function fn2() {
console.log(num);
}
fn2();
}
//输出结果:10
fn1();fn2 的作用域当中访问到了 fn1 函数中的 num 这个局部变量。
闭包案例2
另一个例子:
function fn() {
var num = 10;
return function() {
console.log(num);
}
}
var f = fn();
// 上面这步类似于
// var f = function() {
// console.log(num);
// }
//输出结果:10
f();在上例中我们做到了在 fn() 函数外面访问 fn() 中的局部变量 num。闭包延伸了变量作用域范围,读取了函数内部的变量。
闭包案例3
const fn = function() {
let sum = 0
return function(){
sum++
console.log(sum);
}
}
/**
* `fn()` 进行 `sum` 变量申明并且返回一个匿名函数,
* 第二个 `()` 意思是执行这个匿名函数
*/
fn()() // 1
fn()() // 1我这里直接简单解释一下,执行 fn()() 后,fn()() 已经执行完毕,没有其他资源在引用 fn,此时内存回收机制会认为 fn 不需要了,就会在内存中释放它。
那如何不被回收呢?
const fn = function() {
let sum = 0
return function(){
sum++
console.log(sum);
}
}
fn1 = fn()
// 1
fn1()
// 2
fn1()
// 3
fn1()这种情况下,fn1 一直在引用 fn(),此时内存就不会被释放,就能实现值的累加。那么问题又来了,这样的函数如果太多,就会造成内存泄漏。
内存泄漏了怎么办呢?我们可以手动释放一下。
const fn = function() {
let sum = 0
return function(){
sum++
console.log(sum);
}
}
fn1 = fn()
// 1
fn1()
// 2
fn1()
// 3
fn1()
// `fn1` 的引用 `fn` 被手动释放了
fn1 = null
// `num` 再次归零
fn1 = fn()
// 1
fn1()事件循环
微任务和宏任务
除了广义的同步任务和异步任务,我们可以分的更加精细一点:
- macro task(宏任务):包括整体代码脚本、
setTimeout、setInterval。 - micro task(微任务):
Promise、process.nextTick、MutationObserver。
不同类型的任务会进入到不同的 事件队列(event queue)。相同类型的任务会进入相同的事件队列。比如 setTimeout 和 setInterval 会进入相同的事件队列。
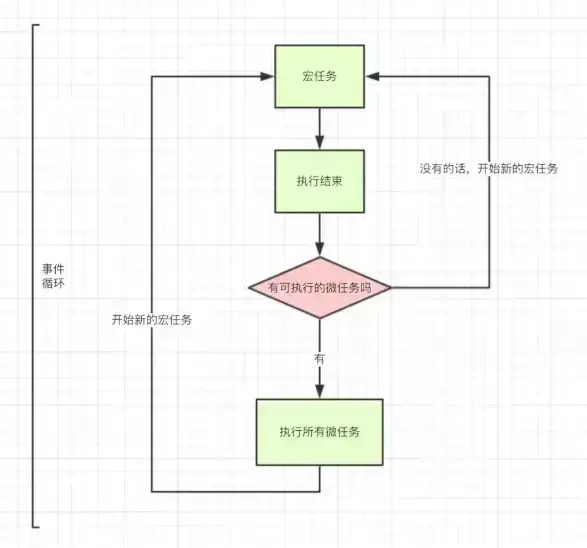
先看一个例子:
setTimeout(function() {
console.log('setTimeout');
}, 0)
new Promise(function(resolve) {
console.log('promise');
resolve(true)
console.log('after resolve')
}).then(function() {
console.log('then');
})
console.log('console');
// promise
// after resolve
// console
// then
// setTimeout- 首先会遇到
setTimeout,将其放到宏任务 event queue 里面。 - 然后回到 promise,
new Promise会立即执行,then会分发到微任务。 - 遇到
console立即执行。 - 整体宏任务执行完成,接下来判断是否有微任务,刚刚放到微任务里面的
then,执行。 - 至此第一轮事件结束,进行第二轮,刚刚我们放在 event queue 的
setTimeout函数内的语句进入到宏任务,立即执行。 - 结束。
为何要区分微任务和宏任务
区分微任务和宏任务是为了将异步队列任务划分优先级,通俗的理解就是为了插队。
一个事件队列(Event Loop)中,microtask 是在 macrotask 之后被调用的,microtask 会在下一个 Event Loop 之前执行完,并且会将 microtask 执行当中新注册的 microtask 一并调用执行完,然后才开始下一次 Event Loop,所以如果有新的 Macrotask 就需要一直等待,等到上一个 Event Loop 当中 Microtask 被清空为止。由此可见,我们可以在下一次 Event Loop 之前进行插队。
如果不区分 Microtask 和 Macrotask,那就无法在下一次 Event Loop 之前进行插队,其中新注册的任务得等到下一个 Macrotask 完成之后才能进行,这中间可能你需要的状态就无法在下一个 Macrotask 前得到同步。
一个利用任务执行顺序(宏任务 => 微任务 => 浏览器渲染)的案例:
<html>
<head>
<style>
div {
padding: 0;
margin: 0;
display: inline-block;
widtH: 100px;
height: 100px;
background: blue;
}
#microTaskDom {
margin-left: 10px;
}
</style>
</head>
<body>
<div id="taskDom"></div>
<div id="microTaskDom"></div>
<script>
window.onload = () => {
setTimeout(() => {
taskDom.style.background = 'red'
setTimeout(() => {
/**
* 使用 `setTimeout` 立马修改背景色,
* 会闪现一次红色背景
*/
taskDom.style.background = 'black'
}, 0);
microTaskDom.style.background = 'red'
Promise.resolve().then(() => {
/**
* 使用 `Promise` 不会闪现红色背景。
* 因为微任务会在渲染之前完成对背景色的修改,
* 等到渲染时就只需要渲染黑色
*/
microTaskDom.style.background = 'black'
})
}, 1000);
}
</script>
</body>
</html>由此我们可以联想到一个的应用场景:使用主流的 MVVM 或类似框架每次修改数据后,并不是马上就会同步触发视图更新的。我们自己开发渲染库的话,可以在业务开发者多次进行数据修改和页面 DOM 渲染之间,做一个数据改动的汇总的操作,然后根据实际最终得到的变更差异,去渲染 DOM 更新页面视图。如果每次修改数据都同步去更新 DOM,那 DOM 更新的频率就太高了。
- TODO:上面说的可能不对,因为渲染库也可以在所有修改数据动作结束之后,走同步方法做数据改动的汇总操作,然后再去渲染 DOM。
setTimeout 的时间误差
在使用 setTimeout 的时候,经常会发现设定的时间与自己设定的时间有差异。
如果改成下面这段会发现执行时间远远超过预定的时间:
setTimeout(() => {
task()
},3000)
sleep(10000000)这是为何?
我们来看一下是怎么执行的:
task()进入到event table里面注册计时。- 然后主线程执行
sleep函数,但是非常慢。计时任然在继续。 - 3 秒到了。
task()进入event queue,但是主线程依旧没有走完。 - 终于过了 10000000ms 之后主线程走完了,
task()进入到主线程。 - 所以
task()被调用前的真实延迟时间是远远大于 3 秒的。
setTimeout 第二个参数最小值
HTML5标准规定了 setTimeout() 中第二个参数如果传入小于 0 的值会被修改为 0,如果 setTimeout 或者 setInterval 嵌套层级超过 5 层,并且第二个参数传入的数值小于 4,那这个数值会被设置为 4。(本段参考了https://html.spec.whatwg.org/multipage/timers-and-user-prompts.html#dom-settimeout)
如果第二个参数如果传入 0,就表示要尽快调用回调函数,更准确地说 —— 就是要在下一个事件循环(event cycle)中调用回调函数。(本段参考了setTimeout() global function)
promise 和 process.nextTick
process.nextTick(callback) 类似 Node.js 版的 setTimeout,在事件循环的下一次循环中调用 callback 回调函数。
几个例子
例1
setTimeout(() => {
console.log(1)
}, 0)
new Promise((resolve) => {
resolve()
}).then(() => {
console.log(2)
})上面的执行结果是2,1。
从规范上来讲,setTimeout有一个4ms的最短时间,也就是说不管你设定多少,反正最少都要间隔4ms(不是精确时间间隔)才运行里面的回调。 而Promise的异步没有这个问题。
从具体实现上来说,这两个的异步队列不一样,Promise所在的那个异步队列优先级要高一些。
例2
(function () {
setTimeout(() => {
console.log(4)
}, 0)
new Promise((resolve) => {
console.log(1)
for (let i = 0; i < 10000; i++) {
i === 9999 && resolve(null)
}
console.log(2)
}).then(() => {
console.log(5)
})
console.log(3)
})()执行结果1,2,3,5,4。为什么执行这样的结果?
- 创建Promise实例是同步执行的。所以先输出1,2,3,这三行代码都是同步执行。
- promise.then和setTimeout都是异步执行,会先执行谁呢?
setTimeout 异步会放到异步队列中等待执行。promise.then 异步会放到 microtask queue 中。microtask 队列中的内容经常是为了需要直接在当前脚本执行完后立即发生的事,所以当同步脚本执行完之后,就调用 microtask 队列中的内容,然后把异步队列中的 setTimeout 的回调函数放入执行栈中执行,所以最终结果是先执行 promise.then 异步,然后再执行 setTimeout 中的异步回调。
这是由于:
Promise 的回调函数属于异步任务,会在同步任务之后执行。但是,Promise 的回调函数不是正常的异步任务,而是微任务(microtask)。它们的区别在于,正常任务追加到下一轮事件循环,微任务追加到本轮事件循环。这意味着,微任务的执行时间一定早于正常任务。
注意:目前 microtask 队列中常用的就是 promise.then。
例3
setTimeout(() => {
console.log(7)
}, 0)
new Promise((resolve, reject) => {
console.log(3);
resolve();
console.log(4);
}).then(() => {
console.log(6)
})
console.log(5)执行结果3,4,5,6,7。
例4
console.log(1)
const promise = new Promise((resolve, reject) => {
console.log(2)
setTimeout(() => {
resolve(3)
reject(4)
}, 0)
})
promise.then((data) => {
console.log(data)
}).catch((err) => {
console.log('6')
console.log(err)
})
promise.then((data) => {
console.log(data)
}).catch((err) => {
console.log('7')
console.log(err)
})
console.log(5)上面这段代码会输出:1、2、5、3、3。
promise 的 resolve、reject
这里需要注意,promise 被 resolve 后再触发 reject 是无效的,不会触发 promise.catch 回调。
Vue3 的 nextTick()
A utility for waiting for the next DOM update flush.
When you mutate reactive state in Vue, the resulting DOM updates are not applied synchronously. Instead, Vue buffers them until the "next tick" to ensure that each component updates only once no matter how many state changes you have made.
nextTick() can be used immediately after a state change to wait for the DOM updates to complete. You can either pass a callback as an argument, or await the returned Promise.
<script setup>
import { ref, nextTick } from 'vue'
const count = ref(0)
async function increment() {
count.value++
// DOM not yet updated
console.log(document.getElementById('counter').textContent) // 0
await nextTick()
// DOM is now updated
console.log(document.getElementById('counter').textContent) // 1
}
</script>
<template>
<button id="counter" @click="increment">{{ count }}</button>
</template>实现原理
原理部分参考了:面试官:Vue中的$nextTick有什么作用?。
export function nextTick(cb?: Function, ctx?: Object) {
let _resolve;
// cb 回调函数会经统一处理压入 callbacks 数组
callbacks.push(() => {
if (cb) {
// 给 cb 回调函数执行加上了 try-catch 错误处理
try {
cb.call(ctx);
} catch (e) {
handleError(e, ctx, 'nextTick');
}
} else if (_resolve) {
_resolve(ctx);
}
});
// 执行异步延迟函数 timerFunc
if (!pending) {
pending = true;
timerFunc();
}
// 当 nextTick 没有传入函数参数的时候,返回一个 Promise 化的调用
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve;
});
}
}上例中,timerFunc 函数会根据当前环境支持什么方法则确定调用哪个,分别有:Promise.then、MutationObserver、setImmediate、setTimeout。
JavaScript 函数与变量声明提升
函数作用域与变量提升
for 循环的例子:
// 打印:4、5、6
for (var i = 0; i < 3; i++) {
setTimeout(() => console.log(++i), 0)
}
// 打印:1、2、3
for (let i = 0; i < 3; i++) {
setTimeout(() => console.log(++i), 0)
}变量声明在函数内部提升至顶部的例子:
var foo = 1;
function bar () {
if (!foo) {
var foo = 10;
}
alert(foo);
}
// 会 alert 10
bar();变量声明提升在作用域最顶部,其次是函数声明,最后是赋值语句:
var a = 1;
function b () {
a = 10;
return;
function a() {}
}
b();
// 会 alert 1
alert(a);function a () {
var b = 1;
function b () {};
console.log(b);
}
// 输出 1
a();function a () {
var b;
function b () {};
console.log(typeof b);
}
// 输出 'function'
a();function a () {
function b () {};
var b;
console.log(typeof b);
}
// 也是输出 'function'
a();function a () {
function b () {};
var b = 2;
console.log(b);
}
// 输出 2
a();例子1
var msg = 'String A'
function test () {
// 弹出 `undefined`
alert(msg)
var msg = 'String A'
// 弹出 'String A'
alert(msg)
}
test()
// 上面的代码等价于下面的写法:
var msg = 'String A'
function test () {
var msg
alert(msg)
msg = 'String A'
alert(msg)
}来一个复杂的例子:
写出下面代码 a、b、c 三行的输出分别是什么?
// mark A
function fun (n, o) {
console.log(o)
return {
// mark B
fun: function (m) {
// mark C
return fun(m, n)
}
}
}
var a = fun(0); a.fun(1); a.fun(2); a.fun(3);
var b = fun(0).fun(1).fun(2).fun(3);
var c = fun(0).fun(1); c.fun(2); c.fun(3);
// 答案:
// undefined, 0, 0, 0
// undefined, 0, 1, 2
// undefined, 0, 1, 1首先,可以分析得到的结论:标记 A 下面的 fun 函数和标记 C 下面 return 的 fun 是同一个函数,标记 B 下面的 fun 属性对应的函数不同于标记 A 和标记 C 下方的函数。下文为了行文方便,将各个标记处下方的函数方便叫做 A、B、C 函数。
a 行的分析:
a = fun(0):即a = fun (0) {console.log(undefined) return { // ... } },故输出undefined;a.fun(1):相当于给 B 函数传了一个参数 1,返回了C函数传参(1, 0)执行后的结果,即 A 函数传参(1, 0)后执行的结果,故输出 0;a.fun(2)和a.fun(2)同上,因为一开始a = fun(0)已经将n的值定为 0 了,后面console.log出来的就都是0了;
b 行的分析:
fun(0):毫无疑问输出undefined;fun(0).fun(1):参考 a 行的分析,可知这里输出的是 0;fun(0).fun(1).fun(2):类似的,输出 1;fun(0).fun(1).fun(2).fun(3):类似的,输出 2;
c 行的分析:
fun(0).fun(1):参见上面的分析,输出undefined、0;c.fun(2)、c.fun(3):参见之前的分析,输出 1、1。
Promise的实现
简单版Promise
class SimplePromise {
/**
* pending 初始状态,既不是成功,也不是失败状态。
* 等待 resolve 或者 reject 调用更新状态。
*/
static pending = 'pending'
/**
* fulfilled 意味着操作成功完成。
* 状态从 pending 转换为 fulfilled,只能由 resolve 方法完成转换
*/
static fulfilled = 'fulfilled'
/**
* rejected 意味着操作失败。
* 状态从 pending 转换为 rejected,只能由 reject 方法完成转换
*/
static rejected = 'rejected'
callbacks = []
constructor(executor) {
// 初始化状态为pending
this.status = SimplePromise.pending
// 存储 this._resolve 即操作成功 返回的值
this.value = undefined
// 存储 this._reject 即操作失败 返回的值
this.reason = undefined
/**
* 存储 `then` 中传入的参数
* 至于为什么是数组呢?
* 因为同一个 Promise 的 `then` 方法可以调用多次。
* 比如:
* ```javascript
* const p = new Promise(
* (resolve, reject) => resolve('3')
* );
* p.then(console.log);
* p.then(console.log);
* ```
* 上面后面的两句 `p.then(console.log)` 都会打印 '3',
* 都是基于 p 的结果 3 进行处理的(两个 `p.then` 互相无关)
*/
this.callbacks = [];
// 这里绑定 this 是为了防止执行时 this 的指向被改
executor(
this._resolve.bind(this),
this._reject.bind(this)
);
}
// onFulfilled 是成功时执行的函数
// onRejected 是失败时执行的函数
then(onFulfilled, onRejected) {
// 这里可以理解为在注册事件
// 也就是将需要执行的回调函数存储起来
this.callbacks.push({
onFulfilled,
onRejected,
});
}
_resolve(value) {
this.value = value
// 将状态设置为成功
this.status = SimplePromise.fulfilled
// 通知事件执行
this.callbacks.forEach((cb) => this._handler(cb))
}
_reject(reason) {
this.reason = reason
// 将状态设置为失败
this.status = SimplePromise.rejected
// 通知事件执行
this.callbacks.forEach((cb) => this._handler(cb))
}
_handler(callback) {
const { onFulfilled, onRejected } = callback;
if (
this.status === SimplePromise.fulfilled &&
onFulfilled
) {
// 传入存储的值
onFulfilled(this.value);
}
if (
this.status === SimplePromise.rejected &&
onRejected
) {
// 传入存储的错误信息
onRejected(this.reason);
}
}
}支持链式调用的 Promise
要求下面打印出来1、3
const p = new ChainablePromise((resolve) => {
resolve(1)
})
p
.then((val) => {
console.log(val)
return 3
}, (reason) => {
console.log(reason)
})
.then((val) => {
console.log(val)
}, (reason) => {
console.log(reason)
})实现方式
class ChainablePromise {
static pending = 'pending';
static fulfilled = 'fulfilled';
static rejected = 'rejected';
constructor(executor) {
// 初始化状态为pending
this.status = ChainablePromise.pending;
// 存储 this._resolve 即操作成功 返回的值
this.value = undefined;
// 存储 this._reject 即操作失败 返回的值
this.reason = undefined;
/**
* 存储 then 中传入的参数
* 至于为什么是数组呢?
* 因为同一个 Promise 的 then 方法可以调用多次
*/
this.callbacks = [];
executor(
this._resolve.bind(this),
this._reject.bind(this)
);
}
/**
* onFulfilled 是成功时执行的函数
* onRejected 是失败时执行的函数
*/
then(onFulfilled, onRejected) {
// 返回一个新的Promise
return new ChainablePromise((
nextResolve,
nextReject
) => {
/**
* 这里之所以把下一个 Promise 的 resolve 函数
* + 和 reject 函数也存在 callback 中
* 是为了将 onFulfilled 的执行结果
* 通过 nextResolve 传入到下一个 Promise
* + 作为它的 value 值
*/
this._handler({
nextResolve,
nextReject,
onFulfilled,
onRejected
});
});
}
_resolve(value) {
/**
* 处理 onFulfilled 执行结果是一个 Promise 时的情况
* 这里可能理解起来有点困难
* 当 value instaneof ChainablePromise 时,
* 说明当前 Promise 肯定不会是第一个 Promise
* 而是后续 then 方法返回的 Promise(第二个 Promise)
*
* 我们要获取的是 value 中的 value 值
* (
* 有点绕,value 是个 promise 时,
* 那么内部存有个 value 的变量
* )
*
* 怎样将 value 的 value 值获取到呢,
* 可以将传递一个函数作为 value.then 的 onFulfilled 参数
*
* 那么在 value 的内部则会执行这个函数,
* 我们只需要将当前 Promise 的 value 值
* + 赋值为 value 的 value 即可
*/
if (value instanceof ChainablePromise) {
value.then(
this._resolve.bind(this),
this._reject.bind(this)
);
return;
}
this.value = value;
// 将状态设置为成功
this.status = ChainablePromise.fulfilled;
// 通知事件执行
this.callbacks.forEach(cb => this._handler(cb));
}
_reject(reason) {
if (reason instanceof ChainablePromise) {
reason.then(
this._resolve.bind(this),
this._reject.bind(this)
);
return;
}
this.reason = reason;
// 将状态设置为失败
this.status = ChainablePromise.rejected;
this.callbacks.forEach(cb => this._handler(cb));
}
_handler(callback) {
const {
onFulfilled,
onRejected,
nextResolve,
nextReject
} = callback;
if (this.status === ChainablePromise.pending) {
this.callbacks.push(callback);
return;
}
if (this.status === ChainablePromise.fulfilled) {
// 传入存储的值
// 未传入 onFulfilled 时,传入 value
const nextValue = onFulfilled
? onFulfilled(this.value)
: this.value;
nextResolve(nextValue);
return;
}
if (this.status === ChainablePromise.rejected) {
// 传入存储的错误信息
// 同样的处理
const nextReason = onRejected
? onRejected(this.reason)
: this.reason;
nextReject(nextReason);
}
}
}
const p = new ChainablePromise((resolve) => {
resolve(1)
})
p
.then((val) => {
console.log(val)
return 3
}, (reason) => {
console.log(reason)
})
.then((val) => {
console.log(val)
}, (reason) => {
console.log(reason)
})JS原型与原型链
普通对象、函数对象、原型对象
普通对象和函数对象
JS中,对象分普通对象和函数对象,Object、Function是JS自带的函数对象。凡是通过new Function()创建的对象都是函数对象,其他的都是普通对象。
typeof Object // "function", 函数对象
typeof Function // "function", 函数对象
function f1 () {}
var f2 = function () {}
var f3 = new Function('str', 'console.log(str)')
var o1 = new f1()
var o2 = {}
var o3 = new Object()
typeof f1 // "function", 函数对象
typeof f2 // "function", 函数对象
typeof f3 // "function", 函数对象
typeof o1 // "object", 普通对象
typeof o2 // "object", 普通对象
typeof o3 // "object", 普通对象原型对象
每当定义一个对象(函数)时,对象中都会包含一些预定义的属性。
其中,函数对象会有一个 prototype 属性,就是我们所说的原型对象(普通对象没有 prototype,但有 __proto__ 属性;函数对象同时含有 prototype 和 __proto__ 属性)。
原型对象其实就是普通对象(Function.prototype 除外,它是函数对象,但同时它又没有 prototype 属性)。
function f1 () {}
// Object{} with two properties: `constructor` and `__proto__`
console.log(f1.prototype)
// "object"
typeof f1.prototype
// 'function'
typeof Object.__proto__
// 特例,没必要记住,平常根本用不到
typeof Function.prototype // "function"
typeof Function.prototype.prototype // "undefined"
typeof Object.prototype // "object"原型对象的主要作用是用于继承:
var Person = function (name) {
this.name = name
}
Person.prototype.getName = function () {
return this.name
}
var yakima = new Person('yakima')
yakima.getName() // "yakima"
// true
console.log(yakima.__proto__ === Person.prototype)原型链
上面提到原型对象的主要作用是用于继承,其具体的实现就是通过原型链实现的。创建对象(不论是普通对象还是函数对象)时,都有一个叫做__proto__的内置属性,用于指向创建它的函数对象的原型对象(即函数对象的prototype属性)
// true,对象的内置__proto__对象指向创建该对象的函数对象的prototype
yakima.__proto__ === Person.prototype
// true
Person.prototype.__proto__ === Object.prototype
// 继续,Object.prototype对象也有__proto__属性,但它比较特殊,为null
Object.prototype.__proto__ === null // true
typeof null // "object"这个由__proto__串起来的直到Object.prototype.__proto__ ==> null对象的链称为原型链。
- yakima的
__proto__属性指向Person.prototype对象; - Person.prototype对象的
__proto__属性指向Object.prototype对象; - Object.prototype对象的
__proto__属性指向null对象;
原型和原型链是JS实现继承的一种模型。
看个例子
var Animal = function () {}
var Dog = function () {}
Animal.price = 2000
Dog.prototype = Animal
var tidy = new Dog()
console.log(Dog.price) // undefined
console.log(tidy.price) // 2000对上例的分析:
- Dog自身没有price属性,沿着
__proto__属性往上找,因为Dog赋值时的Dog = function () {}其实使用new Function ()创建的Dog,所以,Dog.__proto__==>Function.prototype,Function.prototype.__proto__===>Object.prototype,而Object.prototype.__proto__==> null。很明显,整条链上都找不到price属性,只能返回undefined了; - tidy自身没有price属性,沿着
__proto__属性往上找,因为tidy对象是Dog函数对象的实例,tidy.__proto__==>Dog.prototype==> Animal,从而tidy.price获取到了Animal.price的值。
constructor
原型对象中都有个 constructor 属性,用来引用它的函数对象。这是一种循环引用。
Person.prototype.constructor === Person // true
Function.prototype.constructor === Function // true
Object.prototype.constructor === Object // trueCSS
三栏布局
要求
分为左、中、右三部分,高度均为屏幕高度,左边部分宽度为200px,另外两部分等分剩下的页面宽度。
实现
<html>
<head></head>
<body>
<div class="container">
<aside class="left">Left</aside>
<div class="wrapper">
<article class="middle">Middle</article>
<article class="right">Right</article>
</div>
</div>
</body>
</html>.clearfix() {
&:after {
content: '';
clear: both;
display: block;
height: 0;
opacity: 0;
visibility: hidden;
}
}
html, body, div, aside, article {
margin: 0;
padding: 0;
}
html, body, .container, .left, .wrapper, .middle, .right {
height: 100%;
}
.container {
padding-left: 200px;
.clearfix();
.left {
float: left;
width: 200px;
margin-left: -200px;
background-color: skyblue;
}
.wrapper {
float: left;
width: 100%;
.middle, .right {
float: left;
width: 50%;
}
.middle {
background-color: gray;
}
.right {
background-color: yellow;
}
}
}input 框加入 disabled 属性后字体颜色变淡
input[disabled] {
opacity: 1;
}z-index
建议使用CSS预处理器语言的情况下,对所有涉及z-index的属性的值放在一个文件中统一进行管理。这个主意是从饿了么前端团队代码风格指南中看到的。另外补充一下,应该将同一条直系链里同一层级的元素的z-index分类到一起进行管理。因为不同层级或者非直系链里的同一层级的元素是无法直接根据z-index来判断元素前后排列顺序的。
图片在父元素中水平、垂直居中
方案 1:(flex 布局)
.parent {
display: flex;
align-items: center;
justify-content: center;
}方法 2(使用 absolute 绝对定位)
.parent {
position: relative;
display: block;
.img {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
}方法 3(使用 table-cell)
.parent {
display: table-cell;
// width要写得大一点,以撑满容器之外部容器的宽度
width: 3000px;
text-align: center;
vertical-align: middle;
.img {
display: inline-block;
vertical-align: middle;
}
}方法 4(如果父元素的高度为已知的定值,使用 line-height 实现)
.parent {
display: block;
text-align: center;
height: 300px;
line-height: 300px;
.img {
display: inline-block;
}
}方法5(写死间距)
.parent {
display: block;
.img {
display: block;
height: 100px;
margin: 150px auto 0;
}
}方案6(写死定位)
.parent {
position: relative;
display: block;
width: 600px;
height: 400px;
.img {
position: absolute;
width: 100px;
height: 300px;
top: 50px;
left: 250px;
}
}方案7(撑开外部容器)
.parent {
// 包围内部元素
display: inline-block;
.img {
// 用来撑开父元素
padding: 30px 20px;
}
}方案8(作为背景图)
.parent {
display: block;
height: 300px;
background:
transparent url('./example.png') scroll no-repeat center center;
background-size: 100px 200px;
}弹性盒(Flexible Box)模型
justify-content:
flex-start:默认值,伸缩项目向一行的起始位置靠齐;flex-end:伸缩项目向一行的结束位置靠齐;center:项伸缩项目向一行的中间位置靠齐;space-between:伸缩项目会平均地分布在行里。第一个伸缩项目一行中的最开始位置,最后一个伸缩项目在一行中最终点位置;space-around:伸缩项目会平均地分布在行里,两端保留一半的空间;initial:设置该属性为它的默认值;inherit:从父元素继承该属性。
align-items:
stretch:默认值,项目被拉伸以适应容器;center:项目位于容器的中心;flex-start:项目位于容器的开头;flex-end:项目位于容器的结尾;baseline:项目位于容器的基线上;initial:设置该属性为它的默认值;inherit:从父元素继承该属性。
弹性盒实现竖向九宫格
要求
使用 flexbox 布局将 9 个格子排列成 3*3 的九宫格,且第一列排完才排第二列。

<html>
<head></head>
<body>
<section class="boxes-wrapper">
<div class="box">1</div>
<div class="box">2</div>
<div class="box">3</div>
<div class="box">4</div>
<div class="box">5</div>
<div class="box">6</div>
<div class="box">7</div>
<div class="box">8</div>
<div class="box">9</div>
</section>
</body>
</html>实现
body {
margin: 0;
}
.boxes-wrapper {
display: flex;
flex-direction: column;
align-items: flex-start;
justify-content: flex-start;
flex-wrap: wrap;
gap: 10px;
width: 320px;
height: 320px;
.box {
background-color: aqua;
width: 100px;
height: 100px;
text-align: center;
line-height: 100px;
}
}清除浮动的原理
清除浮动使用 clear: left/right/both。业界常用的 .clearfix 也是这么做的,只不过是把该样式写进了父元素的 :after 伪元素中,并加了 opacity: 0; display: block; height: 0; visibility: hidden; 等使伪元素不可见。
不清除浮动但包围浮动元素的方法有:
为浮动元素的父元素添加 overflow: hidden、或将父元素也浮动起来等使父元素形成 BFC(Block Formatting Context) 的方式,但这些方式在应用上没有 .clearfix 这种方式理想。
简述 position 属性各个值的区别
fixed:类似 absolute,但是是相对浏览器窗口而非网页页面进行定位。
absolute:相对最近的 position 值非 static 的外层元素进行定位。
relative:相对自身在文档流中的原始位置进行定位。
static:position 默认值,即元素本身在文档流中的默认位置(忽略 top、bottom、left、right 和 z-index 声明)。
inherit:继承父元素 position 属性的值。
边距塌陷及其修复
竖直方向上相接触的 margin-top、margin-bottom 会塌陷:
- 若二者均为正值,或均为负值,取其绝对值大者;
- 若二者中一正一负,则取二者之和。
高性能动画
CSS 动画会比 JS 动画的性能更好,JS 动画的优势主要在于:
- 更具定制性(毕竟 JS 比 CSS 更可编程);
- 更易实现对低端浏览器的兼容。
当然,大部分业务中,主要还是使用 CSS 动画的,对低端浏览器进行降级就可以了(保证页面可读可操作就可以了,不建议增加老旧设备的性能负担)。
几个注意点:
- 利用
transform: translate3d(x, y, z);可借助 3D 变形开启 GPU 加速(这会消耗更多内存与功耗,确有性能问题时再考虑)。 - 若动画开始时有闪烁,可尝试:
backface-visibility: hidden; perspective: 1000;。 - 尽可能少用
box-shadows和gradients这两页面性能杀手。 - CSS 动画属性可能会触发整个页面的重排(reflow/relayout)、重绘(repaint)和重组(recomposite)。其中 paint 通常是最花费性能的,尽可能避免使用触发 paint 的 CSS 动画属性。所以要尽可能通过修改
translate代替修改top/left/bottom/right来实现动画效果,可以减少页面重绘(repaint),前者只触发页面的重组,而后者会额外触发页面的重排和重绘。 - 尽量让动画元素脱离文档流(document flow)中,以减少重排(reflow)。
- 操作 DOM 的 js 语句能连着写尽量连着写,这样可借助浏览器的优化策略,将可触发重排的操作放于一个队列中,然后一次性进行一次重排;如果操作 DOM 的语句中间被其他诸如赋值语句之类的间断了,页面可能就会发生多次重排了。
HTML
HTML 页面的渲染
本文参考:html+CSS+js解析全过程。
主流程
从浏览器请求html文件,到屏幕上出现渲染的实际像素等,可以分为以下部分:
- 构建 DOM Tree
- 构建 CSSOM Tree
- 合成 Render Tree
- layout 回流:主要涉及到字体大小、元素长宽等 CSS 属性,计算元素的相对位置
- repaint 重绘:颜色等 CSS 属性,显示在屏幕上
解析HTML文件的细节
- 解析 DOM 元素
- 遇 script,DOM 解析暂停
- 包含 JS 代码
- 外联:加载 JS
- 执行 JS(该 JS 代码在 CSS 前,则不受 CSSOM 的阻塞)
- 遇 link CSS
- 加载 CSS 文件,不阻塞 DOM 解析
- 遇到 script:JS 加载,等待 CSSOM Tree 构建完成后再运行
- 防止 JS 代码执行时 获取旧的 CSS 属性
- 遇到 script:JS 加载,等待 CSSOM Tree 构建完成后再运行
- 构建 CSSOM Tree,DOM 继续解析
- 若有 JS,则运行
- 构建 DOM Tree
- 渲染
DOMContentLoaded 与 load 事件
- DOMContentLoaded 事件:在完成 DOM 解析完成,JS 执行完毕后触发。大多数浏览器也会等到 CSS 文件加载并解析完成。
- load 事件:所有外部资源与文件下载完毕后触发。
关于阻塞/非阻塞
- 内联 JS 会阻塞 DOM 的解析。
- 内联 CSS 会阻塞 DOM 解析。
- 外联 CSS 加载不阻塞 DOM 解析,阻塞 DOM 渲染。
- 外联 CSS 加载阻塞后续 script 内的 JS 代码执行(不阻塞前面的)
- JS 文件的普通加载与执行(非 async defer)会阻塞 DOM 的解析
- 因此实际上,后面有 script 的外联 CSS 会阻塞DOM的解析
- <script defer> 不会阻塞 DOM 的解析
- <script async> 加载不阻塞,执行阻塞
- iframe 内的 image 等资源不阻塞 DOM 解析
其他注意事项
- DOM Tree 增量构建,而 CSSOM Tree 非渐进。
常用 meta 标签
<!-- 设定页面使用的字符集 -->
<meta charset="utf-8">
<meta
http-equiv="Content-Type"
content="text/html; charset=UTF-8"
>
<!-- 优先使用 IE 最新版本和 Chrome -->
<meta
http-equiv="X-UA-Compatible"
content="IE=edge,chrome=1"
>
<!-- 国产360浏览器默认采用高速模式渲染页面 -->
<meta name="renderer" content="webkit">
<meta
name="viewport"
content="
width=device-width,
initial-scale=1,
user-scalable=no
"
>
<!-- 禁止设备检测手机号和邮箱 -->
<meta
name="format-detection"
content="telephone=no,email=no"
>
<!-- QQ强制全屏 -->
<meta name="x5-fullscreen" content="true">
<!-- UC强制全屏 -->
<meta name="full-screen" content="yes">
<!-- uc强制竖屏 -->
<meta name="screen-orientation" content="portrait">
<!-- QQ强制竖屏 -->
<meta name="x5-orientation" content="portrait">
<!-- UC应用模式 -->
<meta name="browsermode" content="application">
<!-- QQ应用模式 -->
<meta name="x5-page-mode" content="app">
<!-- windows phone 点击无高光 -->
<meta name="msapplication-tap-highlight" content="no">
<!--
针对手持设备优化,主要是针对一些老的不识别viewport的浏览器,
比如黑莓
-->
<meta name="HandheldFriendly" content="true">
<!-- 设置 web 应用在 iOS 设备中是否启用全屏模式 -->
<meta name="apple-mobile-web-app-capable" content="yes">
<!--
设置 iOS 设备中 web 应用的状态栏样式。
只在用 `apple-apple-mobile-web-app-capable`
+ 开启全局模式后生效
-->
<meta
name="apple-mobile-web-app-status-bar-style"
content="black"
>
<!-- 启用/禁用 iOS Safari 浏览器中自动检测手机号的功能 -->
<meta name="format-detection" content="telephone=no">
<!--
用于设定禁止浏览器从本机的缓存中读取页面内容。
设定后一旦离开网页就无法从缓冲中再读取
-->
<meta http-equiv="pragma" content="no-cache">
<!-- 禁用缓存(再次访问需重新下载页面) -->
<meta http-equiv="cache-control" content="no-cache">
<!--
可以用于设定网页的到期时间。
一旦网页过期,必须到服务器上重新传输
-->
<meta http-equiv="expires" content="0">
<!-- 停留 2 秒钟后自动刷新到 URL 网址 -->
<meta
http-equiv="Refresh"
content="2;URL=http://www.example.com/"
>
<!-- 用于 SEO,其中 description 的内容应不超过 150 个字符 -->
<meta
http-equiv="keywords"
content="keyword1,keyword2,keyword3"
>
<meta
http-equiv="description"
content="This is my page"
>
<!--
强制页面在当前窗口以独立页面显示,
用来防止别人在 iframe 里调用自己的页面
-->
<meta http-equiv="Window-target" content="_top">script 标签
本文参考资料如下:
script 标签用于嵌入可执行脚本或数据,一般用于嵌入一段 JavaScript 脚本,或者指向一个 JavaScript 文件。script 标签也可用于其他语言,比如 WebGL 的 GLSL shader 编程语言脚本,或者 JSON 数据等。
用 script 标签载入数据
注意,如果用 script 标签来载入数据(而非脚本):
- 这些数据必须是以内联的方式嵌入的,并且需要通过 type 属性指定数据的格式。
- 同时需要禁止使用以下属性:
src、async、nomodule、defer、crossorigin、integrity、referrerpolicy、fetchpriority。
比如这样是可以的:
<script id="data" type="application/json">
{"a": "123"}
</script>
<script>
const jsonData = JSON.stringify(
document.querySelector('#data').textContent
)
</script>但是下面这样是不可以的:
<!-- 这样直接通过 src 属性去指向一个数据文件的方式是不可以的 -->
<script
id="data"
type="application/json"
src="https://bla.bla.com/blabla.json">
</script>模板语言
script 标签有个特点是其中的内容不会直接展现在页面上,所以有很多前端模板语言会使用 script 标签来存放 html 模板。我们可以自己写个简单的,像下面这样:
<div class="userInfo"></div>
<script id="template" type="text/template">
<div>
<div class="name">{{ userName }}</div>
<div class="address">{{ userAddress }}</div>
</div>
</script>
<script type="application/javascript">
const templateContent = document
.querySelector('#template')
.textContent
const templateData = {
userName: 'name',
address: 'address'
}
// 一般模版语言的渲染函数实际干的内容类似下面这样
document
.querySelector('.userInfo')
.innerHTML = templateContent
.replace(/\{\{ userName \}\}/m, templateData.userName)
.replate(/\{\{ address \}\}/m, templateData.address)
</script><script defer>、<script async> 脚本的下载、解析动作与 HTML 解析的时序关系
从下图可以看书,除了 <script> 会暂停 HTML 的解析,其他比如 <script defer>、<script async>、<script type="module"> 脚本的下载与 HTML 的解析都是并行不会暂停 HTML 的解析的。

<script async>:
- 只对外部脚本有效。
- 请求该脚本的网络请求是异步的,不会阻塞浏览器解析 HTML。
- 多个 async script 之间的执行顺序是不确定的,取决于谁先被下载完毕。
- 多个 async script 之间的下载开始时间与书写顺序一致,他们是可以并行下载的,下载结束的时间顺序是不确定的。
- 下载完毕后会被直接解析执行,如果此时 HTML 还未被解析完,浏览器会暂停解析 HTML,先执行 JS 脚本。
- async script 一定会在页面的 load 事件之前执行,但与 DOMContentLoaded 事件则没有确定的先后关系。
<script defer>:
- 只对外部脚本有效。
- 请求该脚本的网络请求是异步的,不会阻塞浏览器解析 HTML。
- 多个 defer script 之间的执行书序和书写顺序一致。
- 多个 async script 之间的下载开始时间与书写顺序一致,他们是可以并行下载的,下载结束的时间顺序是不确定的。
- 下载完成后 JS 脚本不会立即执行,会等到浏览器解析完 HTML 后再执行 JS 脚本。
- 赋予 defer 属性的 script 脚本会在 HTML 文档解析完成后被执行,在此之后才会触发 DOMContentLoaded 事件。
DOM
获取元素
书写原生js脚本将body下的第二个div隐藏
var oBody = document.getElementsByTagName('body')[0]
var oChildren = oBody.childNodes
var nDivCounter = 0
for (var i = 0, len = oChildren.length; i < len; i++) {
if (oChildren[i].nodeName === 'DIV') {
nDivCounter++
if (nDivCounter === 2) {
oChildren[i].style.display = 'none'
}
}
}创建元素
问题
现有:
<ul id="list" class="foo">
<li>#0</li>
<li><span>#1</span></li>
<li>#2</li>
<li>#3</li>
<li>
<ul>
<li>#4</li>
</ul>
</li>
<!-- ... -->
<li><a href="//v2ex.com">#99998</a></li>
<li>#99999</li>
<li>#100000</li>
</ul>要求:
- 为ul元素添加一个类.bar
- 删除第10个li
- 在第500个li后面添加一个li,其文字内容为“<v2ex.com />”
- 点击任意li弹框显示其为当前列表中的第几项
解答
// 还原题目真实DOM结构
var list = document.getElementById('list')
void function() {
var html = ''
for (var i = 0; i <= 10000; i++) {
if (i === 1) {
html += '<li><span>#1</span></li>'
} else if (i === 4) {
html += '<li><ul><li>#4</li></ul></li>'
} else if (i === 9998) {
html += '<li><a href="//v2ex.com">#9998</a></li>'
} else {
html += '<li>#' + i + '</li>'
}
}
list.innerHTML = html
}()
// or, list.className += ' bar'
list.classList.add('bar')
var li10 = document.querySelector('#list > li:nth-of-type(10)')
li10.parentNode.removeChild(li10)
var newItem = document.createElement('LI')
var textNode = document.createTextNode('<v2ex.com />')
newItem.appendChild(textNode)
// index for css nth-of-type is 1-based
var li501 = document.querySelector('#list > li:nth-of-type(501)')
list.insertBefore(newItem, li501)
list.addEventListener('click', function(e) {
var target = e.target || e.srcElement
if (target.id === 'list') {
alert('你点到最外层的ul上了,叫我怎么判断?')
return
}
while (target.nodeName !== 'LI') {
target = target.parentNode
}
var parentUl = target.parentNode
var children = parentUl.childNodes
var count = 0
for (var i = 0, len = children.length; i < len; i++) {
var node = children[i]
if (node.nodeName === 'LI') {
count++
}
if (node === target) {
alert('是当前第' + count + '项')
break
}
}
}, false)
// PS: if querySelector method is not available, the following can be changed.
var li10 = document.querySelector('#list > li:nth-of-type(10)')
var li501 = document.querySelector('#list > li:nth-of-type(501)')
// As below:
function getLiByIndex(index /* 0-based index */ ) {
var count = -1
for (var i = 0, len = list.childNodes.length; i < len; i++) {
if (list.childNodes[i].nodeName === 'LI') {
count++
if (count === index) {
return list.childNodes[i]
}
}
}
}
var li10 = getLiByIndex(9)
var li501 = getLiByIndex(500)事件的冒泡和捕获
JS 中事件流的三个阶段:捕获(低版本 IE 不支持)==> 目标 ==> 冒泡。
- 捕获(Capture):从外到内。
- 冒泡(Bubbling):从内到外。
如果不同层的元素使用 useCapture 不同,会先从最外层元素往目标元素寻找设定为 捕获(capture)模式的事件,到达目标元素后执行目标元素的事件后,在循原路往外寻找设定为冒泡(bubbling)模式的事件。
addEventListener
语法如下:
element.addEventListener(type, listener, useCapture)
element.addEventListener(type, listener, options)element: 要绑定事件的对象,或 HTML 节点;type:事件名称(不带“on”),如 “click”、“mouseover”;listener:要绑定的事件监听函数;useCapture:事件监听方式,只能是true或false。true,采用捕获(capture)模式;false,采用冒泡(bubbling)模式。若无特殊要求,一般是false。optionsoptions.capture:一个布尔值,表示listener会在该类型的事件捕获阶段传播到该 EventTarget 时触发。options.once:一个布尔值,表示listener在添加之后最多只调用一次。如果为true,listener会在其被调用之后自动移除。options.passive:一个布尔值,设置为true时,表示listener永远不会调用preventDefault()。如果listener仍然调用了这个函数,客户端将会忽略它并抛出一个控制台警告。
addEventListener
addEventListener() 的工作原理是将实现 EventListener 的函数或对象添加到调用它的 EventTarget 上的指定事件类型的事件侦听器列表中。如果要绑定的函数或对象已经被添加到列表中,该函数或对象不会被再次添加。
addEventListener 允许对同一个 target 同时绑定多个事件,且可以控制是在冒泡阶段还是捕获阶段触发。onclick、onmouseover 这种方式只能绑定一个事件监听回调(最后绑定的生效),且只能在冒泡阶段触发。
removeEventListener
removeEventListener 的入参和 addEventListener 一样。
警告:如果同一个事件监听器分别为“事件捕获(capture 为 true)”和“事件冒泡(capture 为 false)”各注册了一次,这两个版本的监听器需要分别移除。移除捕获监听器不会影响非捕获版本的相同监听器,反之亦然。
使用 passive 改善滚屏性能
将 passive 设为 true 可以启用性能优化,并可大幅改善应用性能(副作用是不能 preventDefault 了),正如下面这个例子:
/* 检测浏览器是否支持该特性 */
let passiveIfSupported = false;
try {
window.addEventListener(
"test",
null,
Object.defineProperty({}, "passive", {
get() {
passiveIfSupported = { passive: true };
},
}),
);
} catch (err) {}
window.addEventListener(
"scroll",
(event) => {
/* do something */
// 不能使用 event.preventDefault();
},
passiveIfSupported,
);根据规范,addEventListener() 的 passive 默认值始终为 false。然而,这会导致触摸事件和滚轮事件(如 wheel、mousewheel、touchstart、touchmove)的事件监听器在浏览器尝试滚动页面时可能会阻塞浏览器主线程——这可能会大大降低浏览器处理页面滚动时的性能。
事件代理/委托
事件代理/委托,是靠事件的冒泡机制实现的(所以,对于一些不具有冒泡特性的事件,比如focus、blur,就没有事件代理/委托这种说法了)。
优缺点
优点有:
- 可以大量节省内存占用,减少事件注册,比如在table上代理所有td的click事件就非常棒;
- 可以实现当新增子孙节点时无需再次对其绑定事件,对于动态内容部分尤为合适。
缺点有:
- 如果把所有事件都代理到一个比较顶层的 DOM 节点上的话,比较容易出现误判,给不需要执行逻辑的节点执行了逻辑。比如把页面中所有事件都绑定到 document 上进行委托,就不是很合适;
- 事件逐级冒泡到外层 DOM 上再执行肯定没有直接执行快。
实现
// 只考虑IE 9&+
function delegate(element, targetSelector, type, handler) {
element.addEventListener(type, function(e) {
var targets = Array.prototype.slice.call(
element.querySelectorAll(targetSelector)
)
var target = e.target
if (targets.indexOf(target) !== -1) {
return handler.apply(target, arguments)
}
})
}阻止事件传播和默认行为
阻止事件的默认行为
e = e || window.event
e.preventDefault()阻止事件传播
e = e || window.event
e.stopPropagation()stopImmediatePropagation
stopImmediatePropagation 方法可阻止同元素或外层元素上相同事件上绑定的其他监听器函数被触发。
触发顺序
如果同类型事件的几个监听器函数被绑定到了同一个对象上,且它们处于相同的阶段(冒泡、捕获),它们会按照添加的顺序被触发。
stopPropagation 和 stopImmediatePropagation的区别
- stopPropagation will prevent any parent handlers from being executed;
- stopImmediatePropagation will prevent any parent handlers and also any other handlers from executing.
事件的几种 target
target
触发事件的对象,也就是用户实际操作(比如点击)的对象。
获取事件对象和目标对象:
function (e) {
e = e ? e : window.event
var target = e.target || e.srcElement
// do some things here
}currentTarget
绑定事件的对象。对应的就是element.addEventListener(eventName, handler, options)里的element。
currentTarget 和 target的比较
- target指向事件直接作用的对象,而currentTarget指向绑定该事件的对象;
- 当处于捕获或冒泡阶段时,两者指向不一致;当处于目标阶段时,两者指向一致。
<html>
<body>
<div id="a">
<div id="b">
<div id="c">
<div id="d">最里层</div>
</div>
</div>
</div>
<script>
const a = document.querySelector('#a')
const b = document.querySelector('#b')
const c = document.querySelector('#c')
const d = document.querySelector('#d')
const getHandler = (elem, useCapture) => {
return (e) => {
const target = e.target
const currentTarget = e.currentTarget
const payload = {
elemId: elem.id,
useCapture,
targetId: target.id,
currentTargetId: currentTarget.id,
}
console.log(JSON.stringify(payload))
}
}
d.addEventListener('click', () => {
console.log('冒泡 d1')
}, { capture: false })
const elems = [a, b, c, d]
elems.forEach((elem) => {
elem.addEventListener('click', getHandler(elem, false), { capture: false })
elem.addEventListener('click', getHandler(elem, true), { capture: true })
})
d.addEventListener('click', () => {
console.log('捕获 d2')
}, { capture: true })
d.addEventListener('click', () => {
console.log('捕获 d3')
}, { capture: true })
d.addEventListener('click', () => {
console.log('冒泡 d4')
}, { capture: false })
</script>
</body>
</html>点击#d元素,控制台打印内容如下:
{"elemId":"a","useCapture":true,"targetId":"d","currentTargetId":"a"}
{"elemId":"b","useCapture":true,"targetId":"d","currentTargetId":"b"}
{"elemId":"c","useCapture":true,"targetId":"d","currentTargetId":"c"}
{"elemId":"d","useCapture":true,"targetId":"d","currentTargetId":"d"}
捕获 d2
捕获 d3
冒泡 d1
{"elemId":"d","useCapture":false,"targetId":"d","currentTargetId":"d"}
冒泡 d4
{"elemId":"c","useCapture":false,"targetId":"d","currentTargetId":"c"}
{"elemId":"b","useCapture":false,"targetId":"d","currentTargetId":"b"}
{"elemId":"a","useCapture":false,"targetId":"d","currentTargetId":"a"}可以看到:
- 捕获阶段:先由外至内按捕获的顺序触发了事件回调。
- 目标阶段:其实就是先捕获后冒泡,在此前提下各自按注册的先后顺序执行。
- 冒泡阶段:最后由内而外按冒泡的顺序又触发了对应的事件回调。
innerHTML、innerText 和 textContent
本文参考资料如下:
这几个元素都是 DOM 对象的属性,可以用来读取、更新 HTML 中元素的内容。
读取内容
假设现在有如下 HTML 代码片段:
<nav>
<a>Home</a>
<a>About</a>
<a>Contact</a>
<a style="display: none">Pricing</a>
</nav>通过 document.querySelector('nav').innerHTML 获取到的内容如下:
<a>Home</a>
<a>About</a>
<a>Contact</a>
<a style="display: none">Pricing</a>通过 document.querySelector('nav').innerText 获取到的内容如下(内容为渲染到屏幕上的内容,会忽略所有 HTML 标签,也会忽略被隐藏的元素):
Home About Contact通过 document.querySelector('nav').textContent 获取到的内容如下(会忽略 HTML 标签,但不会忽略被隐藏的元素):
Home
About
Contact
Pricing设置内容
假设现有如下 HTML 代码片段:
<h2>Programming languages</h2>
<ul class="languages-list"></ul>使用 innerHTML 像下面这样更新内容,可以增加4个由 <li> 标签组成的列表:
const langListElement = document.querySelector('.languages-list')
// Setting or updating content with innerHTML
langListElement.innerHTML = `
<li>JavaScript</li>
<li>Python</li>
<li>PHP</li>
<li>Ruby</li>
`
使用 innerText 像下面这样更新内容,则会得到含有 <li> 字符(不是 HTML 标签)的 4 行文本:
const langListElement = document.querySelector('.languages-list')
langListElement.innerText = `
<li>JavaScript</li>
<li>Python</li>
<li>PHP</li>
<li>Ruby</li>
`
使用 textContent 像下面这样更新内容会直接得到一行文本(不是 4 行文本):
const langListElement = document.querySelector('.languages-list')
langListElement.textContent = `
<li>JavaScript</li>
<li>Python</li>
<li>PHP</li>
<li>Ruby</li>
`
移动端开发
响应式页面设计的原理
响应式页面设计的原理是让页面根据浏览器屏幕宽度/视口宽度自适应,较理想地呈现出页面内容。
较常见的做法是使用CSS media query, 而且通常会在meta标签中对viewport的宽度等进行设定(比如设定width: device-width)。 但即便不用这种方法,只要页面能根据屏幕宽度做出自适应的调整,那就是响应式设计。
rem布局原理
function fit () {
// 750是设计稿的宽度
const scale = $('body').width() / 750
// 开发时,以100px对应1rem进行计算
document.querySelector('html').style.fontSize = 100 * scale + 'px'
}
$(document).ready(() => {
fit()
$(window).resize(fit)
})移动端click事件延时
在移动端使用click事件会产生300ms的延迟。
问题的产生:移动端存在双击放大的问题, 所以在移动端点击事件发生时,为了判断用户的行为(到底是要双击还是要点击),浏览器通常会等待300ms, 如果300ms之内,用户没有再次点击,则判定为点击事件,否则判定为双击缩放。
为什么要解决:现代web对性能的极致追求,对用户体验的高标准,让着300ms的卡顿变得难以接受
如何解决:
1、user-scalable:no 禁止缩放——没有缩放就不存在双击,也就没有点击延迟
2、指针事件:CSS:-ms-touch-action:none 点击后浏览器不会启用缩放操作,也就不存在延迟。然而这种方法兼容性很不好。
3、FastClick库:针对这个问题所开发的轻量级库。FastClick在检测到touchend事件后,会立即触发一个模拟的click事件,并把300ms后真正的click事件阻止掉
用法:
window.addEventListener('load', function () {
// 虽然可以绑定到更具体的元素,但绑定到body上能使整个应用都受益
FastClick.attach(document.body)
})当FastClick检测到页面中使用了user-scalable:no或者touch-action:none方案时,会静默退出。
伪类:active失效
只需给document绑定touchstart或touchend事件即可, 如document.addEventListener('touchstart', function () {}, false)。
更简单的方法是直接在html中body标签上添加属性ontouchstart=""。
格式检测
不让安卓手机识别邮箱:
<meta content="email=no" name="format-detection">禁止IOS识别长串数字为电话:
<meta content="telephone=no" name="format-detection">交互限制
禁止iOS弹出各种操作窗口:-webkit-touch-callout: none;
禁止用户选中文字:-webkit-user-select: none;
input[type="date"]不支持placeholder
<input
placeholder="占位符"
type="text"
onfocus="(this.type='date')"
onblur="(this.type='text')"
>iOS部分版本Date构造函数不支持YYYY-MM-DD格式入参
iOS 部分版本的 Date 构造函数不支持规范标准中定义的 YYYY-MM-DD 格式,如 new Date('2013-11-11') 是 Invalid Date,但支持 YYYY/MM/DD 格式,可用 new Date('2013/11/11')。最通用的还是直接年月日注入传入的方式,即 new Date(year, month, date)。
类似的,对于 yyyy-mm-dd hh:mm:ss 格式的日期,可以通过类似下面的方法将其转换为 Date 对象实例(适用于所有设备):
// 将形如"yyyy-mm-dd hh:mm:ss"的日期字符串转换为日期对象(兼容IOS设备)
function longStringToDate (dateString) {
if (dateString && dateString.length === 19) {
// Attention: there is a space between regular expression
const tempArr = dateString.split(/[- :]/)
return new Date(
tempArr[0],
tempArr[1] - 1,
tempArr[2],
tempArr[3],
tempArr[4],
tempArr[5]
)
}
return 'Invalid Date'
}HTTP
HTTP协议的主要特点
- 简单快速:可以理解为每个资源的URI(统一资源定位符)都是固定的,所以在http协议处理起来比较容易
- 灵活:每个http协议的头部都有一个类型,通过一个http协议就能完成不同类型的传输,所以比较灵活
- 无连接(重):http协议连接一次之后就会断开,不会保持连接
- 无状态(重):可以理解为服务端和客户端是两种身份,单从http协议中是无法区分两次协议者的身份
HTTP报文的组成部分
请求报文:
- 请求行 --- 包含http方法,页面地址,http协议,http版本
- 请求头 --- 包含一些key:value的值,eg: host、Cache-Control,Accept,Cookie等
- 空行 --- 用来告诉服务端往下就是请求体的部分啦
- 请求体 --- 就是正常的query/body参数
响应报文:
- 状态行 --- 包含http方法,http协议,http版本,状态码
- 响应头 --- 包含一些key:value的值,eg: Content-type,Set-cookie, Cache-Control, Date, Server等
- 空行 --- 用来告诉客户端往下就是响应体的部分啦
- 响应体 --- 就是服务端返回的数据
HTTP方法
- GET -- 获取资源
- POST -- 创建一个新的资源
- PUT -- 更新资源,常用来做传输文件,更新整个资源对象
- PATCH -- 更新资源,更新部分属性,例如只更新某个用户的
nickname属性 - DELETE -- 删除资源
- HEAD -- 获取请求报文首部
- OPTIONS -- 询问支持的方法,查询针对请求URI指定的资源支持的方法,在跨域请求中,由客户端(浏览器)发送
提示
- 上述方法,只有 GET 和 POST 才能在
<form />表单中使用, - 但是现在也有很多公司使用 Only Post 的规则:接口只接收 POST 请求。
GET和POST请求的区别
- GET产生的URL地址可以被收藏,而POST不可以
- GET请求会被浏览器主动缓存,而POST不会,除非主动设置
- GET请求参数会被完整的保留在浏览器历史里,而POST的参数不会被保留
- GET请求在URL中传输参数有长度限制,而POST没有
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制
- POST比GET更安全,因为GET请求的参数直接暴露在URL上
- GET参数通过URL传输,而POST参数放在request body中
注意:上面有些说法严格来说也是不对的,因为 post 请求你可以在 url 上加 query 参数,服务端也能获取到这些参数。
两种方法除了自身的参数限制、缓存限制,通常情况下它们主要区别是:GET 不会产生副作用,而 POST 会。
常见HTTP状态码
- 1XX --- 指示信息,表示请求已接受,继续处理
- 100 Continue
- 101 Switching Protocols
- 102 Processing
- 103 Early Hints
- 2XX --- 成功,表示请求已被成功接受
- 200 --- OK,客户端请求成功
- 201 Created
- 202 Accepted
- 203 Non-Authoritative Information
- 204 No Content
- 205 Reset Content
- 206 Partial Content --- 客户端发送了一个带有Range头的GET请求,视频/音频可能会用到
- 3XX --- 重定向,要完成请求,必需进行近一步操作
- 301 Moved Permanently --- 重定向,所请求的界面转移到新的url,永久重定向
- 302 Found --- 同上301,但是是临时重定向
- 303 See Other
- 304 Not Modified --- 缓存,服务端告诉客户端有缓存可用,不用重新请求
- 307 Temporary Redirect
- 308 Permanent Redirect
- 4XX --- 客户端错误,请求有语法错误或请求无法实现
- 400 Bad Request, 客户端请求有语法错误
- 401 Unauthorized, 请求未授权
- 403 Forbidden, 禁止页面访问
- 404 Not found, 请求资源不存在
- 405 Method Not Allowed
- 5XX --- 服务端错误,服务器未能实现合法的请求
- 500 Internal Server Error, 服务器错误
- 501 Not Implemented
- 502 Bad Gateway
- 503 Server Unavailable, 请求未完成,服务器临时过载或者宕机,一段时间后可恢复正常
- 504 Gateway Timeout
持久连接
当使用Keep-alive模式(又称持久连接,连接重用 http1.1的版本才支持)时,Keep-alive功能使客户端到服务端的连接持续有效,当出现服务器的后续请求时,Keep-alive避免了建立或者重新建立连接。
管线化
在使用持久连接的情况下,某个连接上的消息传递类似于:
请求1 --> 响应1 --> 请求2 --> 响应2 --> 请求3 --> 响应3
管线化的连接消息传递是类似于:
请求1 --> 请求2 --> 请求3 --> 响应1 --> 响应2 --> 响应3
相当于客户端一次性把所有的请求打包发送给服务端,同时服务端也一次性打包将所有的返回回传回来
只有GET和HEAD请求可以进行管线化,而POST有所限制
管线化是通过持久连接完成的,且只有http/1.1版本支持
TCP三次握手四次挥手
TCP的特性
- TCP提供一种面向连接的、可靠的字节流服务
- 在一个TCP连接中,仅有两方进行彼此通信。广播和多播不能用于TCP
- TCP使用校验和、确认和重传机制来保证可靠传输
- TCP给数据分节进行排序,并使用累积确认保证数据的顺序不变和非重复
- TCP使用滑动窗口机制来实现流量控制,通过动态改变窗口的大小进行拥塞控制
注意:TCP并不能保证数据一定会被对方接收到,因为这是不可能的。TCP能够做到的是,如果有可能,就把数据递送到接收方,否则就(通过放弃重传并且中断连接这一手段)通知用户。因此准确说TCP也不是100%可靠的协议,它所能提供的是数据的可靠递送或故障的可靠通知。
三次握手与四次挥手
所谓三次握手(Three-way Handshake),是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。
三次握手的目的是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确认号,交换TCP窗口大小信息。
在socket编程中,客户端执行connect()时。将触发三次握手。
TCP 的连接的拆除需要发送四个包,因此称为四次挥手(Four-way handshake),也叫做改进的三次握手。
客户端或服务器均可主动发起挥手动作,在socket编程中,任何一方执行close()操作即可产生挥手操作。
TCP/IP的分层管理
TCP/IP最重要的一个特点就是分层管理,分别为:
- 应用层:决定向用户提供应用服务时的通信活动,http、ftp、dns 都属于这一层
- 安全层(TSL/SSL):如果是https的请求会存在这一层,http的请求则无此层,注意!
- 传输层:传输层对上层应用层提供处于网络连接中两台计算机之间的数据传输
- 网络层:网络层用来处理网络上流动的数据包,数据包是网络传输的最小数据单位
- 链路层:用来处理连接网络的硬件部分,包括控制操作系统、硬件的设备驱动等物理可见部分
HTTP缓存控制
浏览器缓存控制分为强缓存和协商缓存,协商缓存必须配合强缓存使用。
浏览器第一次跟服务器请求一个资源后,服务器在返回这个资源的同时,会根据开发者代码的要求或者浏览器的默认要求,在 response header 里加上相关字段的响应头。
浏览器在请求已经访问过的URL时,会判断是否使用缓存,判断是否使用缓存主要是判断缓存是否在有效期内。
1.1、当浏览器对某个资源的请求命中了强缓存时,利用[Expires]或者[Cache-Control]这两个 http response header 实现
[Expires]描述的是一个绝对时间,依据的是客户端的时间,用GMT格式的字符串表示,如Expires:Thu,31 Dec 2037 23:55:55 GMT,下次浏览器再次请求同一资源时,会先从客户端缓存中查找,找到这个资源后拿出它的[Expires]与当前时间做比较,如果请求时间在[Expires]规定的有效期内就能命中缓存,这样就不用再次到服务器上去缓存一遍,节省了资源。但正因为是绝对时间,如果客户端的时间被随意篡改,这个机制就失效了,所以我们需要[Cache-Control]。
[Cache-Control]描述的是一个相对时间,在进行缓存命中时都是利用浏览器时间判断。
[Expires]和[Cache-Control]这两个header可以只启用一个,也可以同时启用,同时启用时[Cache-Control]优先级高于[Expires]。
1.2、当浏览器对某个资源的请求没有命中强缓存(即缓存过期后),就会发起一个请求到服务器,验证协商缓存是否命中(即验证缓存是否有更新,虽然有效期过了,但我还能继续使用它吗?),如果命中则还是从客户端中加载。协商缓存利用的是[Last-Modified,If-Modified-Since]和[ETag,If-None-Match]这两对header来管理的。
[Last-Modified,If-Modified-Since]:原理和上面的[Expires]相同,服务器会响应一个Last-Modified字段,表示最近一次修改缓存的时间,当缓存过期后, 浏览器就会把这个时间放在If-Modified-Since去请求服务器,判断缓存是否有更新。区别是它是根据服务器时间返回的header来判断缓存是否存在,但有时候也会出现服务器上资源有变化但修改时间没有变化的情况,这种情况我们就需要[ETag,If-None-Match]。
[ETag,If-None-Match]:原理与上面相同,区别是浏览器向服务器请求一个资源,服务器在返回这个资源的同时,在response的header中加上一个Etag字段,这个字段是服务器根据当前请求的资源生成的唯一标识字符串,只有资源有变化这个串就会发生改动。当缓存过期后,浏览器会把这个字符串放在If-None-Match去请求服务器,比较字符串的值判断是否有更新,Etag的优先级比Last-Modified的更高, Etag的出现是为了解决一个缓存文件在短时间内被多次修改的问题,因为Last-Modified只能精确到秒。
[ETag,If-None-Match]这么厉害我们为什么还需要[Last-Modified,If-Modified-Since]呢?有一个例子就是,分布式系统尽量关掉ETag,因为每台机器生成的ETag不一样,[Last-Modified,If-Modified-Since]和[ETag,If-None-Match]一般都是同时启用。
304:
强缓存是不会请求服务端的,命中协商缓存的话,一般服务端会返回状态码 304。
常用场景举例:
前端 SPA 应用发布后,为了保证客户端总能直接加载最新的静态资源文件,结合 nginx.conf 对缓存做出如下配置:
server {
listen 80;
server_name localhost;
root /usr/share/app;
index index.php index.html index.htm;
location / {
try_files $uri $uri/ /index.html;
}
# 静态资源文件 缓存30天;
location ~ \.(css|js|gif|jpg|jpeg|png|bmp|swf|ttf|woff|otf|ttc|pfa)$ {
expires 30d;
}
# `html` 不缓存
location ~ \.(html|htm)$ {
add_header Cache-Control "no-store, no-cache, must-relalidate";
}
}同时为 index.html 增加缓存相关的 <meta /> 标签:
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="Pragma" content="no-cache">
<meta http-equiv="expires" content="0">303 See Other
303 状态码表示服务器要将浏览器重定向到另一个资源,这个资源的 URI 会被写在响应 Header 的 Location 字段。从语义上讲,重定向到的资源并不是你所请求的资源,而是对你所请求资源的一些描述。
303 常用于将 POST 请求重定向到 GET 请求,比如你上传了一份个人信息,服务器发回一个 303 响应,将你导向一个“上传成功”页面。
不管原请求是什么方法,重定向请求的方法都是 GET(或 HEAD,不常用)。
304 Not Modified
HTTP响应码 304 Not Modified 表明不需要传输所请求的资源。它会将请求重定向到已有的缓存资源上。
当请求是GET或者HEAD这种安全请求,会出现这种情况。
开发者本地开发时经常会看到很多304请求,它们实际就是去访问本地的缓存资源的。
Mixed Content
当用户访问一个HTTPS网页时,他们与服务端之间的连接是经过TLS加密的,相对更安全。
如果HTTPS网页中包含的部分内容触发了明文HTTP请求,就会导致部分内容未被加密,也就不安全了。这种页面称为mixed content page。
REST接口设计的5条指导规则
不要使用物理地址作为url。比如
http://www.acme.com/inventory/product003.xml应更换为http://www.acme.com/inventory/product/003。不要返回过多的数据。比如,产品列表查询接口应返回前几条产品数据,而非全部的产品列表数据。数据较多时,可以考虑分页。
接口文档应书写清晰,不要随意改动,避免影响已有的客户端。
应返回实际地址而非让客户端根据id等自行去拼接。
GET请求不应导致服务端状态的变动。
JS内存回收机制
本文参考了以下文章:
由于字符串、对象和数组没有固定大小,当他们的大小已知时,才能对他们进行动态的存储分配。JavaScript 程序每次创建字符串、数组或对象时,解释器都必须分配内存来存储那个实体。 只要像这样动态地分配了内存,最终都要释放这些内存以便他们能够被再用,否则,JavaScript 的解释器将会消耗完系统中所有可用的内存,造成系统崩溃。
在 JavaScript 中,数据类型分为基本类型和引用类型。
- 基本类型:在内存中占有固定大小的空间,值保存在栈内存(stack)中的,是按值来访问的。
- 引用类型:值的大小不固定,在栈内存(stack)中存放地址指向堆内存(heap)中的对象。是按引用访问的。
程序的内存分配
- 栈(stack):栈内存空间,只保存简单数据类型的内存,由操作系统自动分配和释放。
- 堆(heap):堆内存空间,由于大小不固定,系统无法进行自动释放,需要 JS 引擎(如 Chrome V8)来手动释放这些内存。
JavaScript 中调用栈中的数据回收
JavaScript 引擎会通过向下移动 ESP(记录当前执行状态的指针) 来销毁该函数保存在栈中的执行上下文。
JavaScript 堆中的数据回收
在 V8 中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象。
新生区通常只支持 1~8M 的容量,而老生区支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收。
- 副垃圾回收器,主要负责新生代的垃圾回收。
- 主垃圾回收器,主要负责老生代的垃圾回收。
不论什么类型的垃圾回收器,它们都有一套共同的执行流程:
- 第一步是标记空间中活动对象和非活动对象。所谓活动对象就是还在使用的对象,非活动对象就是可以进行垃圾回收的对象。
- 第二步是回收非活动对象所占据的内存。其实就是在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象。
- 第三步是做内存整理。一般来说,频繁回收对象后,内存中就会存在大量不连续空间,我们把这些不连续的内存空间称为内存碎片。当内存中出现了大量的内存碎片之后,如果需要分配较大连续内存的时候,就有可能出现内存不足的情况。所以最后一步需要整理这些内存碎片。(这步其实是可选的,因为有的垃圾回收器不会产生内存碎片).
内存碎片整理
内存回收次数多了以后,会有很多内存碎片,如果不加清理,会导致过载触发不必要的内存回收动作。清除非活动对象,前移活动对象时,对象的内存地址是汇编的,因为要通过移动把连续的空间腾出来。为了要保持活动对象的可访问,处理方式可能是记录变化前后的地址,然后在取对象内容时加上这个变化的偏移量。
全停顿
由于 JavaScript 是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。我们把这种行为叫做全停顿。
在 V8 新生代的垃圾回收中,因其空间较小,且存活对象较少,所以全停顿的影响不大,但老生代就不一样了。如果执行垃圾回收的过程中,占用主线程时间过久,主线程是不能做其他事情的。比如页面正在执行一个 JavaScript 动画,因为垃圾回收器在工作,就会导致这个动画在垃圾回收过程中无法执行,这将会造成页面的卡顿现象。
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为增量标记(Incremental Marking)算法.
使用增量标记算法,可以把一个完整的垃圾回收任务拆分为很多小的任务,这些小的任务执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样当执行上述动画效果时,就不会让用户因为垃圾回收任务而感受到页面的卡顿了。
现在各大浏览器通常用采用的垃圾回收有两种方法:标记清除、引用计数。
标记清除
这是 JavaScript 中最常用的垃圾回收方式。当变量进入执行环境时,就标记这个变量为“进入环境”。从逻辑上讲,永远不能释放进入环境的变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到他们,除非变量离开了环境。当变量离开环境时,则将其标记为“离开环境”。
引用计数
引用计数的含义是跟踪记录每个值被引用的次数。当声明了一个变量 a 并将一个引用类型值(比如 { a: 1 })赋值给该变量时,则这个值 { a: 1 } 的引用次数就是 1。 相反,如果包含对这个值的引用的变量(可以是直接引用,也可以间接引用,比如在 a 已经是上述所说的对象时, const b = a 或者 const b = { d: a } 中的 b 都是包含对这个值的引用的变量)又取得了另外一个值,则这个值 { a: 1 } 的被引用次数就减少了 1。
当这个值引用次数变成 0 时,则说明没有办法再访问这个值了,因而就可以将其所占的内存空间给收回来。
这样,垃圾收集器下次再运行时,它就会释放那些引用次数为 0 的值所占的内存。
该策略容易在循环引用时出现问题。因为计数记录的是被引用的次数,循环引用时计数并不会消除。导致无法释放内存。
如果要解决循环引用带来的内存泄露问题,我们只需要把循环引用中的变量设为 null 即可。将变量设置为 null 意味着切断变量与它此前引用的值之间的联系。当垃圾收集器下次运行时,就会删除这些值并回收他们占用的内存。
Memory Overflow 内存溢出
内存溢出一般是指执行程序时,程序会向系统申请一定大小的内存,当系统现在的实际内存少于需要的内存时,就会造成内存溢出。
内存溢出造成的结果是先前保存的数据会被覆盖或者后来的数据会没地方存。
Memory Leak 内存泄漏
不再用到的内存,没有及时释放,就叫做内存泄漏(memory leak)。内存泄漏是指程序执行时,一些变量没有及时释放,一直占用着内存。而这种占用内存的行为就叫做内存泄漏。
作为一般的用户,根本感觉不到内存泄漏的存在。真正有危害的是内存泄漏的堆积,这会最终消耗尽系统所有的内存。从这个角度来说,一次性内存泄漏并没有什么危害,因为它不会堆积。
内存泄漏如果一直堆积,最终会导致内存溢出问题。
内存泄漏发生的原因
全局变量
除了常规设置了比较大的对象在全局变量中,还可能是意外导致的全局变量,如:
function foo(arg) {
bar = "this is a hidden global variable";
}在函数中,没有使用 var/let/const 定义变量,这样实际上是定义在 window 全局对象上面,变成了 window.bar。再比如由于 this 导致的全局变量:
function foo() {
this.bar = "this is a hidden global variable";
}
foo()这种函数,在 window 作用域下被调用时,函数里面的 this 指向了 window,执行时实际上为 window.bar = "this is a hidden global variable",这样也产生了全局变量。
计时器中引用没有清除
先看如下代码:
var someData = getData();
setInterval(function() {
var node = document.getElementById('Node');
if (node) {
node.innerHTML = JSON.stringify(someData);
}
}, 1000);这里定义了一个计时器,每隔 1s 把一些数据写到 Node 节点里面。但是当这个 Node 节点被删除后,这里的逻辑其实都不需要了,可是这样写,却导致了计时器里面的回调函数无法被回收,同时,someData 里的数据也是无法被回收的。
闭包
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing) console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log(originalThing);
}
};
};
setInterval(replaceThing, 1000);当这段代码反复运行,就会看到内存占用不断上升,垃圾回收器(GC)并无法降低内存占用。
闭包与内存泄漏
内存泄露是指你「用不到」(访问不到)的变量,依然占据着内存空间,不能被再次利用起来。闭包里面的变量就是我们需要的变量,不能说是内存泄露。
闭包是一个非常强大的特性,但人们对其也有诸多误解。一种耸人听闻的说法是闭包会造成内存泄露,所以要尽量减少闭包的使用。
局部变量本来应该在函数退出的时候被解除引用,但如果局部变量被封闭在闭包形成的环境中,那么这个局部变量就能一直生存下去。从这个意义上看,闭包的确会使一些数据无法被及时销毁。使用闭包的一部分原因是我们选择主动把一些变量封闭在闭包中,因为可能在以后还需要使用这些变量,把这些变量放在闭包中和放在全局作用域,对内存方面的影响是一致的,这里并不能说成是内存泄露。如果在将来需要回收这些变量,我们可以手动把这些变量设为 null。
跟闭包和内存泄露有关系的地方是,使用闭包的同时比较容易形成循环引用,如果闭包的作用域链中保存着一些 DOM 节点,这时候就有可能造成内存泄露。但这本身并非闭包的问题,也并非 JavaScript 的问题。在基于引用计数策略的垃圾回收机制中,如果两个对象之间形成了循环引用,那么这两个对象都无法被回收,但循环引用造成的内存泄露在本质上也不是闭包造成的。
同样,如果要解决循环引用带来的内存泄露问题,我们只需要把循环引用中的变量设为 null 即可。将变量设置为 null 意味着切断变量与它此前引用的值之间的连接。当垃圾收集器下次运行时,就会删除这些值并回收它们占用的内存。
内存泄漏的识别方法
利用 Chrome 浏览器性能面板记录可视化内存泄漏
Performance 面板的时间轴能够直观实时显示JS内存使用情况、节点数量、侦听器数量等。
打开 Chrome 浏览器,调出调试面板(DevTools),点击 Performance 选项(低版本是 Timeline),勾选 Memory 复选框。一种比较好的做法是使用强制垃圾回收开始和结束记录。在记录时点击 Collect garbage 按钮 (强制垃圾回收按钮) 可以强制进行垃圾回收。所以录制顺序可以这样:开始录制前先点击垃圾回收 --> 点击开始录制 --> 点击垃圾回收 --> 点击结束录制。面板介绍如图:
录制结果如图:

首先,从图中我们可以看出不同颜色的曲线代表的含义,这里主要关注 JS 堆内存、节点数量、侦听器数量。鼠标移到曲线上,可以在左下角显示具体数据。在实际使用过程中,如果您看到这种 JS 堆大小或节点大小不断增大的模式,则可能存在内存泄漏。
使用堆快照发现已分离 DOM 树的内存泄漏
只有页面的 DOM 树或 JavaScript 代码不再引用 DOM 节点时,DOM 节点才会被作为垃圾进行回收。如果某个节点已从 DOM 树移除,但某些 JavaScript 仍然引用它,我们称此节点为“已分离”,已分离的 DOM 节点是内存泄漏的常见原因。
同理,调出调试面板,点击 Memory,然后选择 Heap Snapshot,然后点击进行录制。录制完成后,选中录制结果,在 Class filter 文本框中键入 Detached,搜索已分离的 DOM 树。以这段代码为例:
<html>
<head></head>
<body>
<button id="createBtn">增加节点</button>
<script>
function create() {
var ul = document.createElement('ul');
for (var i = 0; i < 10; i++) {
var li = document.createElement('li');
ul.appendChild(li);
}
detachedTree = ul;
}
document
.getElementById('createBtn')
.addEventListener('click', create);
</script>
</body>
</html>点击几下,然后记录。可以得到以下信息:
如上图,点开节点,可以看到下面的引用信息,上面可以看出,有个 HTMLUListElement(ul 节点)被 window.detachedTree 引用。再结合代码,原来是没有加 var/let/const 声明,导致其成了全局变量,所以 DOM 无法释放。
避免内存泄漏的方法
- 少用全局变量,避免意外产生全局变量。
- 使用闭包要及时注意,及时清楚对 DOM 元素的引用。
- 计时器里的回调没用的时候要记得销毁。
- 为了避免疏忽导致的遗忘,我们可以使用
WeakSet和WeakMap结构,它们对于值的引用都是不计入垃圾回收机制的,表示这是弱引用。举个例子:
const wm = new WeakMap();
const element = document.getElementById('example');
wm.set(element, 'some information');
// "some information"
wm.get(element)这种情况下,一旦消除对该节点的引用,它占用的内存就会被垃圾回收机制释放。WeakMap 保存的这个键值对,也会自动消失。
基本上,如果你要往对象上添加数据,又不想干扰垃圾回收机制,就可以使用 WeakMap。
Vue2
Vue2的响应式原理
所谓响应式就是首先建立响应式数据和依赖之间的关系,当这些响应式数据发生变化的时候, 可以通知那些绑定这些数据的依赖进行相关操作,可以是 DOM 更新,也可以是执行一个回调函数。
我们知道 Vue2 的对象数据是通过 Object.defineProperty 对每个属性进行监听, 当对属性进行读取的时候,就会触发 getter,对属性进行设置的时候,就会触发 setter。
/**
* 这里的函数 defineReactive 用来对 Object.defineProperty 进行封装。
*/
function defineReactive(data, key, val) {
// 依赖存储的地方
const dep = new Dep()
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get: function () {
// 在 getter 中收集依赖
dep.depend()
return val
},
set: function(newVal) {
val = newVal
// 在 setter 中触发依赖
dep.notify()
}
})
}那么是什么地方进行属性读取呢?就是在 Watcher 里面,Watcher 也就是所谓的依赖。 在 Watcher 里面读取数据的时候,会把自己设置到一个全局的变量中。
/**
* 我们所讲的依赖其实就是 Watcher,
* 我们要通知用到数据的地方,而使用这个数据的地方有很多,
* 类型也不一样,有可能是组件的,有可能是用户写的watch,
* 所以我们需要抽象出一个能集中处理这些情况的类。
*/
class Watcher {
constructor(vm, exp, cb) {
this.vm = vm
this.getter = exp
this.cb = cb
this.value = this.get()
}
get() {
Dep.target = this
let value = this.getter.call(this.vm, this.vm)
Dep.target = undefined
return value
}
update() {
const oldValue = this.value
this.value = this.get()
this.cb.call(this.vm, this.value, oldValue)
}
}在 Watcher 读取数据的时候也就触发了这个属性的监听 getter, 在 getter 里面就需要进行依赖收集,这些依赖存储的地方就叫 Dep, 在 Dep 里面就可以把全局变量中的依赖进行收集,收集完毕就会把全局依赖变量设置为空。 将来数据发生变化的时候,就去 Dep 中把相关的 Watcher 拿出来执行一遍。
/**
* 我们把依赖收集的代码封装成一个 Dep 类,它专门帮助我们管理依赖。
* 使用这个类,我们可以收集依赖、删除依赖或者向依赖发送通知等。
**/
class Dep {
constructor() {
this.subs = []
}
addSub(sub) {
this.subs.push(sub)
}
removeSub(sub) {
remove(this.subs, sub)
}
depend() {
if(Dep.target){
this.addSub(Dep.target)
}
}
notify() {
const subs = this.subs.slice()
for(let i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}
}
// 删除依赖
function remove(arr, item) {
if(arr.length) {
const index = arr.indexOf(item)
if(index > -1){
return arr.splice(index, 1)
}
}
}总的来说就是通过 Object.defineProperty 监听对象的每一个属性,当读取数据时会触发 getter,修改数据时会触发 setter。
然后我们在 getter 中进行依赖收集,当 setter 被触发的时候,就去把在 getter 中收集到的依赖拿出来进行相关操作,通常是执行一个回调函数。
我们收集依赖需要进行存储,对此 Vue2 中设置了一个 Dep 类,相当于一个管家,负责添加或删除相关的依赖和通知相关的依赖进行相关操作。
在 Vue2 中所谓的依赖就是 Watcher。 值得注意的是,只有 Watcher 触发的 getter 才会进行依赖收集,哪个 Watcher 触发了 getter,就把哪个 Watcher 收集到 Dep 中。 当响应式数据发生改变的时候,就会把收集到的 Watcher 都进行通知。
由于 Object.defineProperty 无法监听对象的变化, 所以 Vue2 中设置了一个 Observer 类来管理对象的响应式依赖,同时也会递归侦测对象中子数据的变化。
为什么 Vue2 新增响应式属性要通过额外的 API?
这是因为 Object.defineProperty 只会对属性进行监测,而不会对对象进行监测, 为了可以监测对象 Vue2 创建了一个 Observer 类。 Observer 类的作用就是把一个对象全部转换成响应式对象,包括子属性数据, 当对象新增或删除属性的时候负责通知对应的 Watcher 进行更新操作。
// 定义一个属性
function def(obj, key, val, enumerable) {
Object.defineProperty(obj, key, {
value: val,
enumerable: !!enumerable,
writable: true,
configurable: true
})
}
class Observer {
constructor(value) {
this.value = value
// 添加一个对象依赖收集的选项
this.dep = new Dep()
// 给响应式对象添加 __ob__ 属性,表明这是一个响应式对象
def(value, '__ob__', this)
if(Array.isArray(value)) {
} else {
this.walk(value)
}
}
walk(obj) {
const keys = Object.keys(obj)
// 遍历对象的属性进行响应式设置
for(let i = 0; i < keys.length; i ++) {
defineReactive(obj, keys[i], obj[keys[i]])
}
}
}vm.$set 的实现原理
function set(target, key, val) {
const ob = target.__ob__
defineReactive(ob.value, key, val)
ob.dep.notify()
return val
}当向一个响应式对象新增属性的时候,需要对这个属性重新进行响应式的设置, 即使用 defineReactive 将新增的属性转换成 getter/setter。
我们在前面讲过每一个对象是会通过 Observer 类型进行包装的, 并在 Observer 类里面创建一个属于这个对象的依赖收集存储对象 dep, 最后在新增属性的时候就通过这个依赖对象进行通知相关 Watcher 进行变化更新。
vm.$delete 的实现原理
function del(target, key) {
const ob = target.__ob__
delete target[key]
ob.dep.notify()
}我们可以看到 vm.$delete 的实现原理和 vm.$set 的实现原理是非常相似的。
通过 vm.$delete 和 vm.$set 的实现原理,我们可以更加清晰地理解到 Observer 类的作用, Observer 类就是给一个对象也进行一个监测,因为 Object.defineProperty 是无法实现对对象的监测的, 但这个监测是手动,不是自动的。 获得授权,非商业转载请注明出处。
Object.defineProperty 真的不能监听数组的变化吗?
面试官一上来可能先问你 Vue2 中数组的响应式原理是怎么样的,这个问题你也许会觉得很容易回答, Vue2 对数组的监测是通过重写数组原型上的 7 个方法来实现,然后你会说具体的实现, 接下来面试官可能会问你,为什么要改写数组原型上的 7 个方法,而不使用 Object.defineProperty, 是因为 Object.defineProperty 真的不能监听数组的变化吗?
其实 Object.defineProperty 是可以监听数组的变化的。
const arr = [1, 2, 3]
arr.forEach((val, index) => {
Object.defineProperty(arr, index, {
get() {
console.log('监听到了')
return val
},
set(newVal) {
console.log('变化了:', val, newVal)
val = newVal
}
})
})其实数组就是一个特殊的对象,它的下标就可以看作是它的 key。
所以 Object.defineProperty 也能监听数组变化,那么为什么 Vue2 弃用了这个方案呢?
这种直接通过下标获取数组元素的场景就并不少,但是即便可以通过 Object.defineProperty 对数组已有的数字下标 key 进行监听,但 Object.defineProperty 方案监听不了 push、pop、shift 等对数组进行操作的方法,而且如果数组元素较多的话,监听每个下标带来的内存占用也会比较多。
所以还是需要通过对数组原型上的那 7 个方法进行重写监听(这比对每个数组的所有下标进行监听要省内存多了)。所以为了性能考虑 Vue2 直接弃用了使用 Object.defineProperty 对数组进行监听的方案。
Vue2 中是怎么监测数组的变化的?
通过上文我们知道如果使用 Object.defineProperty 对数组进行监听, 当通过 Array 原型上的方法改变数组内容的时候是无发触发 getter/setter 的, Vue2 中是放弃了使用 Object.defineProperty 对数组进行监听的方案, 而是通过对数组原型上的 7 个方法进行重写进行监听的。
原理就是使用拦截器覆盖 Array.prototype,之后再去使用 Array 原型上的方法的时候, 其实使用的是拦截器提供的方法,在拦截器里面才真正使用原生 Array 原型上的方法去操作数组。
拦截器
// 拦截器其实就是一个和 Array.prototype 一样的对象。
const arrayProto = Array.prototype
const arrayMethods = Object.create(arrayProto)
;[
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
].forEach(function (method) {
// 缓存原始方法
const original = arrayProto[method]
Object.defineProperty(arrayMethods, method, {
value: function mutator(...args) {
// 最终还是使用原生的 Array 原型方法去操作数组
return original.apply(this, args)
},
eumerable: false,
writable: false,
configurable: true
})
})所以通过拦截器之后,我们就可以追踪到数组的变化了,然后就可以在拦截器里面进行依赖收集和触发依赖了。
接下来我们就使用拦截器覆盖那些进行了响应式处理的 Array 原型,数组也是一个对象, 通过上文我们可以知道 Vue2 是在 Observer 类里面对对象的进行响应式处理,并且给对象也进行一个依赖收集。 所以对数组的依赖处理也是在 Observer 类里面。
class Observer {
constructor(value) {
this.value = value
// 添加一个对象依赖收集的选项
this.dep = new Dep()
// 给响应式对象添加 __ob__ 属性,表明这是一个响应式对象
def(value, '__ob__', this)
// 如果是数组则通过覆盖数组的原型方法进行拦截操作
if(Array.isArray(value)) {
value.__proto__ = arrayMethods
} else {
this.walk(value)
}
}
// ...
}在这个地方 Vue2 会进行一些兼容性的处理, 如果能使用 __proto__ 就覆盖原型, 如果不能使用,则直接把那 7 个操作数组的方法直接挂载到需要被进行响应式处理的数组上, 因为当访问一个对象的方法时,只有这个对象自身不存在这个方法,才会去它的原型上查找这个方法。
数组如何收集依赖呢?
我们知道在数组进行响应式初始化的时候会在 Observer 类里面给这个数组对象的添加一个 __ob__ 的属性, 这个属性的值就是 Observer 这个类的实例对象,而这个 Observer 类里面有存在一个收集依赖的属性 dep, 所以在对数组里的内容通过那 7 个方法进行操作的时候,会触发数组的拦截器, 那么在拦截器里面就可以访问到这个数组的 Observer 类的实例对象,从而可以向这些数组的依赖发送变更通知。
// 拦截器其实就是一个和 Array.prototype 一样的对象。
const arrayProto = Array.prototype
const arrayMethods = Object.create(arrayProto)
;[
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
].forEach(function (method) {
// 缓存原始方法
const original = arrayProto[method]
Object.defineProperty(arrayMethods, method, {
value: function mutator(...args) {
// 最终还是使用原生的 Array 原型方法去操作数组
const result = original.apply(this, args)
// 获取 Observer 对象实例
const ob = this.__ob__
// 通过 Observer 对象实例上 Dep 实例对象去通知依赖进行更新
ob.dep.notify()
},
eumerable: false,
writable: false,
configurable: true
})
})因为 Vue2 的实现方法决定了在 Vue2 中对数组的一些操作无法实现响应式操作,例如:
this.list[0] = xxx由于 Vue2 放弃了 Object.defineProperty 对数组进行监听的方案,所以通过下标操作数组是无法实现响应式操作的。
又例如:
this.list.length = 0这个动作在 Vue2 中也是无法实现响应式操作的。
数组依赖的收集
其实不管是对象还是数组的依赖都是在 getter 中进行依赖收集的。
例如:
{ list: [1,2,3,4] }你要获取到 list 数组的内容,首先是通过 list 这个 key 进行获取的, 所以当通过 list 这个 key 进行获取数组内容的时候,就触发了 list 这个 key 的 getter。
在 getter 中会进行 key 的依赖收集,收集到的依赖保存在对应 key 的 Dep 对象中, 同时也会判断 key 的值,如果是一个对象,还会对这个对象进行依赖收集, 收集到的依赖则保存在这个对象的 __ob__ 属性对象上的 Dep 上, 而这个 __ob__ 属性对象就是上文中提到的 Observer 类, 在 Observer 类中也有一个 Dep 属性用于专门保存响应式对象的依赖的。 这样无论是对象还是数组数据都可以通过 __ob__ 属性拿到 Observer 实例, 然后拿到 Observer 实例中的 dep。然后就可以进行相关的响应式依赖通知操作了。
实现Vue的数据双向绑定
要求
<div id="app">
<h3>数据的双向绑定</h3>
<div class="cell">
<div class="text" v-text="myHello"></div>
<input class="input" type="text" v-model="myHello" >
<div class="text" v-text="myWorld"></div>
<input class="input" type="text" v-model="myWorld" >
</div>
</div>要求实现一个SimpleVue类,使得执行下面的代码可以实现双向数据绑定效果。
// 创建SimpleVue实例
const app = new SimpleVue({
el : '#app' ,
data : {
myHello : 'hello',
myWorld : 'world',
}
})实现
class SimpleVue {
constructor (options){
// 传入的配置参数
this.options = options;
// 根元素
this.$el = document.querySelector(options.el);
// 数据域
this.$data = options.data;
/**
* 保存数据model与view相关的指令,
* 当model改变时,我们会触发其中的指令类更新,保证view也能实时更新
*/
this._directives = {};
// 数据劫持,重新定义数据的 set 和 get 方法
this._obverse(this.$data);
/**
* 解析器,解析模板指令,
* 并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,
* 一旦数据有变动,收到通知,更新视图
*/
this._compile(this.$el);
}
// _obverse 函数,对data进行处理,重写data的set和get函数
_obverse(data) {
// 遍历数据
for (const key in data) {
// 判断是不是属于自己本身的属性
if (!data.hasOwnProperty(key)) {
continue
}
/**
* 这里的key是一种简单处理,
* 其实在后续递归调用this._obverse时,是可能会出现重复的key的
*/
this._directives[key] = [];
let val = data[key];
// 如果是对象,则继续递归遍历(这里简化了,只考虑对象这种单一场景)
if (typeof val === 'object') {
this._obverse(val);
}
// 初始当前数据的执行队列
let _dir = this._directives[key];
// 重新定义数据的 get 和 set 方法
Object.defineProperty(this.$data, key, {
enumerable: true,
configurable: true,
get: function () {
return val;
},
set: function (newVal) {
if (val !== newVal) {
val = newVal;
/**
* 当 myHello等指令值改变时,
* 触发 _directives 中的绑定的Watcher类的更新
*/
_dir.forEach((item) => {
//调用自身指令的更新操作
item._update();
})
}
}
})
}
}
/**
* 接着我们来看看 _compile 这个方法,它实际上是一个解析器,
* 其功能就是解析模板指令,并将每个指令对应的节点绑定更新函数,
* 添加监听数据的订阅者,一旦数据有变动,就收到通知,
* 然后去更新视图变化,具体实现如下:
*
* 我们从根元素 #app 开始递归遍历每个节点,
* 并判断每个节点是否有对应的指令,这里我们只针对 v-text 和 v-model,
* 我们对 v-text 进行了一次 new Watcher(),
* 并把它放到了 myHello 的指令集里面,对 v-model 也进行了解析,
* 对其所在的 input 绑定了 input 事件,并将其通过 new Watcher() 与 myHello 关联起来
*/
_compile(el){
// 子元素
const nodes = el.children;
for (let i = 0, len = nodes.length; i < len; i++){
const node = nodes[i];
// 递归:对所有子元素进行遍历,并进行处理
if (node.children.length) {
this._compile(node);
}
// 如果有 v-text 指令 , 监控 node的值 并及时更新
if (node.hasAttribute('v-text')) {
const attrValue = node.getAttribute('v-text');
// 将指令对应的执行方法放入指令集
this._directives[attrValue].push(
new Watcher('text', node, this, attrValue, 'innerHTML')
)
}
/**
* 如果有 v-model属性,
* 并且元素是INPUT或者TEXTAREA,
* 我们监听它的input事件
*/
if (
node.hasAttribute('v-model') &&
['INPUT', 'TEXTAREA'].includes(node.tagName)
){
const _this = this;
const attrValue = node.getAttribute('v-model');
// 初始化赋值
_this._directives[attrValue].push(
new Watcher('input', node, _this, attrValue, 'value')
);
// 添加input事件监听
node.addEventListener('input', () => {
// 后面每次都会更新
_this.$data[attrValue] = node.value;
}, { capture: false })
}
}
}
}
/**
* Watcher 其实就是订阅者,
* 是 _observer 和 _compile 之间通信的桥梁,
* 用来绑定更新函数,
* 实现对 DOM 元素的更新。
*
* 每次创建 Watcher 的实例,都会传入相应的参数,
* 也会进行一次 _update 操作,上述的 _compile 中,
* 我们创建了两个 Watcher 实例,不过这两个对应的 _update 操作不同而已,
* 对于 div.text 的操作其实相当于 div.innerHTML=h3.innerHTML = this.data.myHello,
* 对于 input 相当于 input.value=this.data.myHello,
* 这样每次数据 set 的时候,我们会触发两个 _update 操作,
* 分别更新 div 和 input 中的内容~
*/
class Watcher {
/*
* name 指令名称,例如文本节点"text"、输入框'input'
* el 指令对应的DOM元素
* vm 指令所属SimpleVue实例
* exp 指令对应的值,如'myHello'
* attr 绑定的属性值,本例为"innerHTML"
* */
constructor (name, el, vm, exp, attr){
this.name = name;
this.el = el;
this.vm = vm;
this.exp = exp;
this.attr = attr;
// 更新操作
this._update();
}
_update(){
this.el[this.attr] = this.vm.$data[this.exp];
}
}总结
Vue2 是通过 Object.defineProperty 将对象的属性转换成 getter/setter 的形式来进行监听它们的变化, 当读取属性值的时候会触发 getter 进行依赖收集, 当设置对象属性值的时候会触发 setter 进行向相关依赖发送通知,从而进行相关操作。
由于 Object.defineProperty 只对属性 key 进行监听,无法对引用对象进行监听, 所以在 Vue2 中创建一个了 Observer 类对整个对象的依赖进行管理, 当对响应式对象进行新增或者删除则由响应式对象中的 dep 通知相关依赖进行更新操作。
Object.defineProperty 也可以实现对数组的监听的,但因为性能的原因 Vue2 放弃了这种方案, 改由重写数组原型对象上的 7 个能操作数组内容的变更的方法,从而实现对数组的响应式监听。
Vue2 diff 算法
虚拟 DOM (VNode)
假设我们的真实dom是:
<ul id="container">
<li class="box" :key="user1">张三</li>
<li class="box" :key="user2">李四</li>
</ul>那么他对应的VNode就是:
const oldVNode = {
tag: "ul",
data: {
staticClass: "container",
},
text: undefined,
children: [
{
tag: "li",
data: { staticClass: "box", key: "user1" },
text: undefined,
children: [
{ tag: undefined, data: undefined, text: "张三", children: undefined },
],
},
{
tag: "li",
data: { staticClass: "box", key: "user2" },
text: undefined,
children: [
{ tag: undefined, data: undefined, text: "李四", children: undefined },
],
},
],
};这时候修改一个li标签的内容:
<ul id="container">
<li class="box" :key="user1">张三123123123</li>
<li class="box" :key="user2">李四</li>
</ul>对应的虚拟dom就变成:
const newVNode = {
tag: "ul",
data: {
staticClass: "container",
},
text: undefined,
children: [
{
tag: "li",
data: { staticClass: "box", key: "user1" },
text: undefined,
children: [
{ tag: undefined, data: undefined, text: "张三123123123", children: undefined },
],
},
{
tag: "li",
data: { staticClass: "box", key: "user2" },
text: undefined,
children: [
{ tag: undefined, data: undefined, text: "李四", children: undefined },
],
},
],
};diff
用一句话来概括就是:同层比较、深度优先。
- 如果不限制同层比较的话,时间复杂度就不只是 On 了。
执行过程
当我们 this.key = xxx 时,触发当前 key 的 setter,并通过内部 dep.notify() 通知所有 watcher 进行更新,更新的时候就会调用 `patch 方法。
patch
这个函数的作用就是:通过 sameVnode() 判断 oldVnode、newVnode 是否为同一种节点类型。
- 如果是同一种节点类型,就调用
patchVnode()进行 diff 算法。 - 否则,直接进行替换。
patch 的核心代码:
function patch(oldVnode, newVnode) {
const isRealElement = isDef(oldVnode.nodeType) //判断oldVnode是否是真实节点
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// 更新周期走这里,diff发生的地方
patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly)
} else {
// 如果是真实dom,就转换为Vnode,赋值给oldVnode
if (isRealElement) {
oldVnode = emptyNodeAt(oldVnode)
}
// replacing existing element
const oldElm = oldVnode.elm
const parentElm = nodeOps.parentNode(oldElm) // 得到真实dom的父节点
// 将oldVnode转换为真实dom,并插入
createElm(
vnode,
insertedVnodeQueue,
oldElm._leaveCb ? null : parentElm,
nodeOps.nextSibling(oldElm)
)
if (isDef(parentElm)) {
removeVnodes([oldVnode], 0, 0) // 删除老的节点
} else if (isDef(oldVnode.tag)) {
invokeDestroyHook(oldVnode)
}
}
}sameVnode
这个方法主要是用来比较传入的俩个vnode是否是相同节点。判断条件见如下代码:
function sameVnode (a, b) {
return (
a.key === b.key && // 比较key
a.asyncFactory === b.asyncFactory && (
(
a.tag === b.tag && // 比较标签
a.isComment === b.isComment && // 比较注释
isDef(a.data) === isDef(b.data) && // 比较data
sameInputType(a, b)
) || (
isTrue(a.isAsyncPlaceholder) &&
isUndef(b.asyncFactory.error)
)
)
)
}patchVnode
主要作用:比较俩个Vnode,包括三种类型操作:属性更新 、文本更新、子节点更新。
具体规则如下:
- 新老节点均有 children 子节点,则对子节点进行 diff 操作,调用 updateChildren。
- 如果新节点有子节点,而老节点没有子节点,先清空老节点的文本内容,然后为其新增子节点。
- 如果新节点没有子节点,而老节点有子节点,则移除老节点所有的子节点。
- 当新老节点都没有子节点的时候,只是文本的替换。
patchVnode 核心代码:
function patchVnode (oldVnode, vnode,) {
if (oldVnode === vnode) {
return
} // 如果新节点等于老节点直接返回
const elm = vnode.elm = oldVnode.elm // 将oldVnode的真实dom节点赋值给Vnode
// 获取新旧节点的子节点数组
const oldCh = oldVnode.children
const ch = vnode.children
// 如果新节点没文本,大概率有子元素
if (isUndef(vnode.text)) {
// 如果双方都有子元素
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
}
// 如果新节点有子元素
else if (isDef(ch)) {
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
}
// 如果老节点有子元素(走到这一步说明新节点没有子元素)
else if (isDef(oldCh)) {
removeVnodes(oldCh, 0, oldCh.length - 1)
}
// 如果老节点有文本(走到这一步说明新节点没有文本)
else if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, '')
}
}
// 如果老节点的文本 != 新节点的文本
else if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text)
}
}上面的代码验证了我们上面说的四点规则,其中最主要的还是新旧节点都有子元素的时候的对比,也就是 updateChildren。
updateChildren
这个方式是 patchVnode 中的一个重要方法,也叫重排操作。主要进行新旧虚拟节点的子节点的对比,等通过 sameVnode() 找到相同节点时,再递归调用 patchVnode。
对比过程:
- 旧首 => 新首
- 旧尾 => 新尾
- 旧首 => 新尾
- 旧尾 => 新首
如果以上都匹配不到,再以新 vnode 为准,依次遍历老节点,直到找到相同的节点之后,再调用 patchVnode。
备注:过程1~4你可以理解为Vue优化的一种手段,想想你平时使用Vue场景,要么在开头或结尾插入,要么只是单纯的修改某个值(this.key = xxx),Vue考虑到了这种场景可能出现的频率很高,索性就做了这个优化,避免每次重复遍历,这样对性能提升很大。
接下来用一个实际例子,来看一下 diff 过程。
描述:真实 DOM 和 oldVnode 是内容分别为 a、b、c 的 div,新的虚拟 dom 只是改变了原来节点的内容(新a、新b、新c)以及新增了一个内容为 新d 的 div,别的没有任何变化。需要注意的是每次比较都遵循上面的规则。
初始值:
- oSIdx(oldVnode开头下标) = 0
- oEIdx(oldVnode结尾下标) = 2
- nSIdx(newVnode开头下标) = 0
- nEIdx(newVnode结尾下标) = 3
**第一步:oldVnode[oSIdx] === newVnode[nSIdx] **
描述:按照规则,先 旧首 => 新首,sameVnode(a,b) 结果为 true,说明是相同节点。需要做的就是调用patchVnode(oldVnode,vNode) 更新节点的内容,之后 oSIdx++、nSIdx++。
第二步:oldVnode[oSIdx] === newVnode[nSIdx](注意:此时oSIdx为1,nSIdx为1)
描述:此时分别比较oldVnode、newVnode对应的第二个节点,因为是循环,所以依然是重新执行规则 旧首 => 新首(下面的源码里面可以看到对应逻辑),sameVnode(a,b)结果为true,所以依然是调用patchVnode(oldVnode,vNode)更新节点内容。之后oSIdx++、nSIdx++。
第三步:oldVnode[oSIdx] === newVnode[nSIdx]//注意:此时oSIdx为2,nSIdx为2
描述:这一步跟前两步一样,这里不做过多描述。之后oSIdx++、nSIdx++。
第四步
oSIdx = 3 oEIdx = 2
nSIdx = 3 nEIdx = 3描述:因为此时oSIdx>oEIdx、nSIdx===nEIdx(按照源码的逻辑,结束while循环),说明oldCh先遍历完,所以newCh比oldCh多,说明是新增操作,执行addVnodes(),将新节点插入到dom中。
附录: updateChildren核心源码,以及注释:
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
let oldStartIdx = 0 // oldVnode开始下标
let oldEndIdx = oldCh.length - 1 // oldVnode结尾下标
let oldStartVnode = oldCh[0] // oldVnode第一个节点
let oldEndVnode = oldCh[oldEndIdx] // oldVnode最后一个节点
let newStartIdx = 0 // newVnode开始下标
let newEndIdx = newCh.length - 1 // newVnode结尾下标
let newStartVnode = newCh[0] // newVnode第一个节点
let newEndVnode = newCh[newEndIdx] // newVnode最后一个节点
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
const canMove = !removeOnly
if (process.env.NODE_ENV !== 'production') {
checkDuplicateKeys(newCh)
}
// 注意循环条件,只有oldVnode和newVnode的开始节点小于等于的时候才会循环
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // 这一步就是额外操作,如果oldStartVnode取不到元素,就向后移
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx] // 这一步就是额外操作,如果oldEndVnode取不到元素,就向后移
}
// 真正开始执行diff
else if (sameVnode(oldStartVnode, newStartVnode)) {
// 旧首新首比较
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
// 旧尾新尾比较
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// 旧首新尾比较
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// 旧尾新首比较
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 以上都不匹配执行下面的逻辑
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) { // New element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldCh[idxInOld] = undefined
canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)
} else {
// same key but different element. treat as new element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
// 循环结束后,判断是oldCh多,还是newCh多
// 如果oldCh多 newCh少 就是删除
// 如果oldCh少 newCh多 就是创建
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) {
removeVnodes(oldCh, oldStartIdx, oldEndIdx)
}
}参考
Vue3
Vue3 的响应式原理
Vue3 是通过 Proxy 对数据实现 getter/setter 代理,从而实现响应式数据, 然后在副作用函数中读取响应式数据的时候,就会触发 Proxy 的 getter, 在 getter 里面把对当前的副作用函数保存起来, 将来对应响应式数据发生更改的话,则把之前保存起来的副作用函数取出来执行。
具体是副作用函数里面读取响应式对象的属性值时, 会触发代理对象的 getter,然后在 getter 里面进行一定规则的依赖收集保存操作。
简单代码实现:
// 使用一个全局变量存储被注册的副作用函数
let activeEffect
// 注册副作用函数
function effect(fn) {
activeEffect = fn
fn()
}
const obj = new Proxy(data, {
// getter 拦截读取操作
get(target, key) {
// 将副作用函数 activeEffect 添加到存储副作用函数的全局变量 targetMap 中
track(target, key)
// 返回读取的属性值
return Reflect.get(target, key)
},
// setter 拦截设置操作
set(target, key, val) {
// 设置属性值
const result = Reflect.set(target, key, val)
// 把之前存储的副作用函数取出来并执行
trigger(target, key)
return result
}
})
// 存储副作用函数的全局变量
const targetMap = new WeakMap()
// 在 getter 拦截器内追踪依赖的变化
function track(target, key) {
// 没有 activeEffect,直接返回
if(!activeEffect) return
// 根据 target 从全局变量 targetMap 中获取 depsMap
let depsMap = targetMap.get(target)
if(!depsMap) {
// 如果 depsMap 不存,那么需要新建一个 Map 并且与 target 关联
depsMap = new Map()
targetMap.set(target, depsMap)
}
// 再根据 key 从 depsMap 中取得 deps, deps 里面存储的是所有与当前 key 相关联的副作用函数
let deps = depsMap.get(key)
if(!deps) {
// 如果 deps 不存在,那么需要新建一个 Set 并且与 key 关联
deps = new Set()
depsMap.set(key, deps)
}
// 将当前的活动的副作用函数保存起来
deps.add(activeEffect)
}
// 在 setter 拦截器中触发相关依赖
function trgger(target, key) {
// 根据 target 从全局变量 targetMap 中取出 depsMap
const depsMap = targetMap.get(target)
if(!depsMap) return
// 根据 key 取出相关联的所有副作用函数
const effects = depsMap.get(key)
// 执行所有的副作用函数
effects && effects.forEach(fn => fn())
}通过上面的代码我们可以知道 Vue3 中依赖收集的规则, 首先把响应式对象作为 key,一个 Map 的实例做为值方式存储在一个 WeakMap 的实例中, 其中这个 Map 的实例又是以响应式对象的 key 作为 key, 值为一个 Set 的实例为值。 而且这个 Set 的实例中存储的则是跟那个响应式对象 key 相关的副作用函数。
那么为什么 Vue3 的依赖收集的数据结构这里采用 WeakMap 呢?
所以我们需要解析一下 WeakMap 和 Map 的区别, 首先 WeakMap 是可以接受一个对象作为 key 的,而 WeakMap 对 key 是弱引用的。 所以当 WeakMap 的 key 是一个对象时,一旦上下文执行完毕,WeakMap 中 key 对象没有被其他代码引用的时候, 垃圾回收器 就会把该对象从内存移除,我们就无法通过该对象从 WeakMap 中获取内容了。
另外副作用函数使用 Set 类型,是因为 Set 类型能自动去除重复内容。
上述方法只实现了对引用类型的响应式处理,因为 Proxy 的代理目标必须是非原始值。 原始值指的是 Boolean、Number、BigInt、String、Symbol、undefined 和 null 等类型的值。 在 JavaScript 中,原始值是按值传递的,而非按引用传递。 这意味着,如果一个函数接收原始值作为参数,那么形参与实参之间没有引用关系,它们是两个完全独立的值,对形参的修改不会影响实参。
Vue3 中是通过对原始值做了一层包裹的方式来实现对原始值变成响应式数据的。 最新的 Vue3 实现方式是通过属性访问器 getter/setter 来实现的。
class RefImpl{
private _value
public dep
// 表示这是一个 Ref 类型的响应式数据
private _v_isRef = true
constructor(value) {
this._value = value
// 依赖存储
this.dep = new Set()
}
// getter 访问拦截
get value() {
// 依赖收集
trackRefValue(this)
return this._value
}
// setter 设置拦截
set value(newVal) {
this._value = newVal
// 触发依赖
triggerEffect(this.dep)
}
}ref 本质上是一个实例化之后的 “包裹对象”, 因为 Proxy 无法提供对原始值的代理,所以我们需要使用一层对象作为包裹,间接实现原始值的响应式方案。 由于实例化之后的 “包裹对象” 本质与普通对象没有任何区别,所以为了区分 ref 与 Proxy 响应式对象, 我们需要给 ref 的实例对象定义一个 _v_isRef 的标识,表明这是一个 ref 的响应式对象。
最后我们和 Vue2 进行一下对比,我们知道 Vue2 的响应式存在很多的问题,例如:
- 初始化时需要遍历对象所有 key,如果对象层次较深,性能不好
- 通知更新过程需要维护大量 dep 实例和 watcher 实例,额外占用内存较多
- 无法监听到数组元素的变化,只能通过劫持重写了几个数组方法
- 动态新增,删除对象属性无法拦截,只能用特定 set/delete API 代替
- 不支持 Map、Set 等数据结构
而 Vue3 使用 Proxy 实现之后,以上的问题都不存在了。
Vue3 中是如何监测数组变化的?
我们知道在 Vue2 中是需要对数组的监听进行特殊的处理的,其实在 Vue3 中也需要对数组进行特殊处理。 在 Vue2 是不可以通过数组下标对响应式数组进行设置和读取的,而 Vue3 中是可以的, 但是数组中仍然有很多其他特别的读取和设置的方法, 这些方法没经过特殊处理,是无法通过普通的 Proxy 中的 getter/setter 进行响应式处理的。
数组中对属性或元素进行读取的操作方法。
- 通过索引访问数组的元素值
- 访问数组的长度
- 把数组作为对象,使用 for ... in 循环遍历
- 使用 for ... of 迭代遍历数组
- 数组的原型方法,如 concat、join、every、some、find、findIndex、includes 等
数组中对属性或元素进行设置的操作方法。
- 通过索引修改数组的元素值
- 修改数组的长度
- 数组的栈方法
- 修改原数组的原型方法:splice、fill、sort 等
当上述的数组的读取或设置的操作发生时,也应该正确地建立响应式联系或触发响应。
当通过索引设置响应式数组的时候,有可能会隐式修改数组的 length 属性, 例如设置的索引值大于数组当前的长度时,那么就要更新数组的 length 属性, 因此在触发当前的修改属性的响应之外,也需要触发与 length 属性相关依赖进行重新执行。
遍历数组,使用 for ... in 循环遍历数组与遍历常规对象是一致的, 也可以使用 ownKeys 拦截器进行设置。 而影响 for ... in 循环对数组的遍历会是添加新元素:arr[0] = 1 或者修改数组长度:arr.length = 0, 其实无论是为数组添加新元素,还是直接修改数组的长度,本质上都是因为修改了数组的 length 属性。 所以在 ownKeys 拦截器内进行判断,如果是数组的话,就使用 length 属性作为 key 去建立响应联系。
在 Vue3 中也需要像 Vue2 那样对一些数组原型上方法进行重写。
当数组响应式对象使用 includes、indexOf、lastIndexOf 这方法的时候, 它们内部的 this 指向的是代理对象,并且在获取数组元素时得到的值要也是代理对象, 所以当使用原始值去数组响应式对象中查找的时候,如果不进行特别的处理,是查找不到的, 所以我们需要对上述的数组方法进行重写才能解决这个问题。
首先 arr.indexOf 可以理解为读取响应式对象 arr 的 indexOf 属性, 这就会触发 getter 拦截器,在 getter 拦截器内我们就可以判断 target 是否是数组, 如果是数组就看读取的属性是否是我们需要重写的属性,如果是,则使用我们重写之后的方法。
const arrayInstrumentations = {}
;(['includes', 'indexOf', 'lastIndexOf']).forEach(key => {
const originMethod = Array.prototype[key]
arrayInstrumentations[key] = function(...args) {
// this 是代理对象,先在代理对象中查找
let res = originMethod.apply(this, args)
if(res === false) {
// 在代理对象中没找到,则去原始数组中查找
res = originMethod.apply(this.raw, args)
}
// 返回最终的值
return res
}
})上述重写方法的主要是实现先在代理对象中查找, 如果没找到,就去原始数组中查找,结合两次的查找结果才是最终的结果, 这样就实现了在代理数组中查找原始值也可以查找到。
在一些数组的方法中除了修改数组的内容之外也会隐式地修改数组的长度。例如下面的例子:
const arr = new Proxy([1], {
get(target, key) {
console.log(`读取`, target, key)
return target[key]
},
set(target, key, val) {
console.log('设置', key, val)
/**
* 注意这里需要return一下,否则会因为返回undefined报错:
* VM680:1 Uncaught TypeError:
* 'set' on proxy: trap returned falsish for property '1'
* at Proxy.push (<anonymous>)
* at <anonymous>:1:5
*/
return Reflect.set(target, key, val)
}
})
arr.push(2)上述代码执行后,控制台输入内容如下:
读取 [1] push
读取 [1] length
设置 1 2
设置 length 2我们可以看到我们只是进行 arr.push 的操作却也触发了 getter 拦截器, 并且触发了两次,其中一次就是数组 push 属性的读取,还有一次是什么呢? 还有一次就是调用 push 方法会间接读取 length 属性, 那么问题来了,进行了 length 属性的读取,也就会建立 length 的响应依赖, 可 arr.push 本意只是修改操作,并不需要建立 length 属性的响应依赖。 所以我们需要 “屏蔽” 对 length 属性的读取,从而避免在它与副作用函数之间建立响应联系。
相关代码实现如下:
const arrayInstrumentations = {}
// 是否允许追踪依赖变化
let shouldTrack = true
// 重写数组的 push、pop、shift、unshift、splice 方法
;['push','pop','shift', 'unshift', 'splice'].forEach(method => {
// 取得原始的数组原型上的方法
const originMethod = Array.prototype[method]
// 重写
arrayInstrumentations[method] = function(...args) {
// 在调用原始方法之前,禁止追踪
shouldTrack = false
// 调用数组的默认方法
let res = originMethod.apply(this, args)
// 在调用原始方法之后,恢复允许进行依赖追踪
shouldTrack = true
return res
}
})在调用数组的默认方法间接读取 length 属性之前,禁止进行依赖跟踪, 这样在间接读取 length 属性时,由于是禁止依赖跟踪的状态, 所以 length 属性与副作用函数之间不会建立响应联系。
常见疑问
对于基本数据类型ref的处理方式还是Object.defineProperty的get()和set()完成。这说法对吗?
从原理上来说不是的,是使用对象的属性的赋值器(setter)和取值器(getter), 而不是Object.defineProperty,Object.defineProperty 是重新定义,劫持属性的访问和设置。
但从实际上来说是对的,因为用babe转译后就是Object.defineProperty。
总结
Vue3 则是通过 Proxy 对数据实现 getter/setter 代理,从而实现响应式数据, 然后在副作用函数中读取响应式数据的时候,就会触发 Proxy 的 getter, 在 getter 里面把对当前的副作用函数保存起来, 将来对应响应式数据发生更改的话,则把之前保存起来的副作用函数取出来执行。
Vue3 对数组实现代理时,用于代理普通对象的大部分代码可以继续使用, 但由于对数组的操作与对普通对象的操作存在很多的不同, 那么也需要对这些不同的操作实现正确的响应式联系或触发响应。 这就需要对数组原型上的一些方法进行重写。
比如通过索引为数组设置新的元素,可能会隐式地修改数组的 length 属性的值。 同时如果修改数组的 length 属性的值,也可能会间接影响数组中的已有元素。 另外用户通过 includes、indexOf 以及 lastIndexOf 等对数组元素进行查找时, 可能是使用代理对象进行查找,也有可能使用原始值进行查找, 所以我们就需要重写这些数组的查找方法,从而实现用户的需求。 原理很简单,当用户使用这些方法查找元素时,先去响应式对象中查找,如果没找到,则再去原始值中查找。
另外如果使用 push、pop、shift、unshift、splice 这些方法操作响应式数组对象时会间接读取和设置数组的 length 属性, 所以我们也需要对这些数组的原型方法进行重写,让当使用这些方法间接读取 length 属性时禁止进行依赖追踪, 这样就可以断开 length 属性与副作用函数之间的响应式联系了。
React
React做了什么
React是用于构建用户界面的JS框架。因此React只负责解决view层的渲染。
- virtual dom模型
- 生命周期管理
- setState机制
- diff算法
- React patch、事件系统
virtual dom 实际上是对实际dom的一个抽象,是一个js对象。react所有的表层操作实际上是在操作virtual dom。经过diff算法会计算出virtual dom的差异,然后针对这些差异进行实际的dom操作进而更新页面。
React组件的生命周期
mount流程
- getDefaultProps
- getInitialState
- componentWillMount
- render
- componentDidMount
update过程
- componentWillReceiveProps
- shouldComponentUpdate
- componentWillUpdate
- render
- componentDidUpdate
unmount过程
- componentWillUnmount
diff算法
diff算法用于计算出两个virtual dom的差异,是react中开销最大的地方。
传统diff算法通过循环递归对比差异,算法复杂度为O(n^3)。
react diff算法制定了三条策略,将算法复杂度从 O(n^3)降低到O(n)。
- WebUI中DOM节点跨节点的操作特别少,可以忽略不计。
- 拥有相同类的组件会拥有相似的DOM结构。拥有不同类的组件会生成不同的DOM结构。
- 同一层级的子节点,可以根据唯一的ID来区分。
针对这三个策略,react diff实施的具体策略是:
- diff对树进行分层比较,只对比两棵树同级别的节点。跨层级移动节点,将会导致节点删除,重新插入,无法复用。
- diff对组件进行类比较,类相同的递归diff子节点,不同的直接销毁重建。diff对同一层级的子节点进行处理时,会根据key进行简要的复用。两棵树中存在相同key的节点时,只会移动节点。
另外,在对比同一层级的子节点时:
diff算法会以新树的第一个子节点作为起点遍历新树,寻找旧树中与之相同的节点。
如果节点存在,则移动位置。如果不存在,则新建一个节点。
在这过程中,维护了一个字段lastIndex,这个字段表示已遍历的所有新树子节点在旧树中最大的index。 在移动操作时,只有旧index小于lastIndex的才会移动。
这个顺序优化方案实际上是基于一个假设,大部分的列表操作应该是保证列表基本有序的。 可以推倒倒序的情况下,子节点列表diff的算法复杂度为O(n^2)
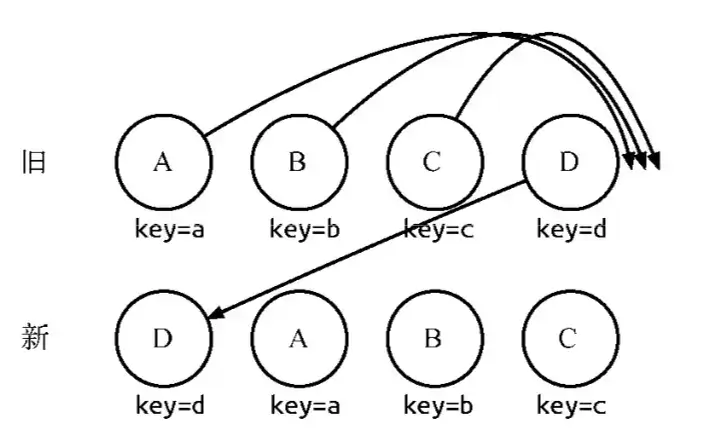
React性能优化方案
由于react中性能主要耗费在于update阶段的diff算法,因此性能优化也主要针对diff算法。
减少diff算法触发次数
减少diff算法触发次数实际上就是减少update流程的次数。
正常进入update流程有三种方式:
setState
setState机制在正常运行时,由于批更新策略,已经降低了update过程的触发次数。
因此,setState优化主要在于非批更新阶段中(timeout/Promise回调),减少setState的触发次数。
常见的业务场景即处理接口回调时,无论数据处理多么复杂,保证最后只调用一次setState。
父组件render
父组件的render必然会触发子组件进入update阶段(无论props是否更新)。此时最常用的优化方案即为shouldComponentUpdate方法。 最常见的方式是对this.props和this.state进行浅比较来判断组件是否需要更新。或者直接使用PureComponent,原理一致。
需要注意的是,父组件的render函数如果写的不规范,将会导致上述的策略失效。
/**
* Bad case
* 每次父组件触发render 将导致传入的handleClick参数都是一个全新的匿名函数引用。
* 如果this.list 一直都是undefined,每次传入的默认值[]都是一个全新的Array。
* hitSlop的属性值每次render都会生成一个新对象
*/
class Father extends Component {
onClick() {}
render() {
return (
<Child
handleClick={() => this.onClick()}
list={this.list || []}
hitSlop={{ top: 10, left: 10}}
/>
)
}
}
/**
* Good case
* 在构造函数中绑定函数,给变量赋值
* render中用到的常量提取成模块变量或静态成员
*/
const hitSlop = {top: 10, left: 10};
class Father extends Component {
constructor(props) {
super(props);
this.onClick = this.onClick.bind(this);
this.list = [];
}
onClick() {}
render() {
return (
<Child
handleClick={this.onClick}
list={this.list}
hitSlop={hitSlop}
/>
)
}
}forceUpdate
forceUpdate方法调用后将会直接进入componentWillUpdate阶段,无法拦截,因此在实际项目中应该弃用。
其他优化策略
shouldComponentUpdate
使用shouldComponentUpdate钩子,根据具体的业务状态,减少不必要的props变化导致的渲染。如一个不用于渲染的props导致的update。
另外,也要尽量避免在shouldComponentUpdate中做一些比较复杂的操作,比如超大数据的pick操作等。
合理设计state
不需要渲染的state,尽量使用实例成员变量。
合理设计props
不需要渲染的props,合理使用context机制,或公共模块(比如一个单例服务)变量来替换。
正确使用diff算法
- 不使用跨层级移动节点的操作(因为会导致节点无法复用)。
- 对于条件渲染多个节点时,尽量采用隐藏等方式切换节点,而不是替换节点。
- 尽量避免将后面的子节点移动到前面的操作,当节点数量较多时,会产生一定的性能问题。
Redux
预备知识
先提出个疑问:我们为什么需要状态管理?
对于SPA应用来说,前端所需要管理的状态越来越多,需要查询、更新、传递的状态也越来越多,如果让每个组件都存储自身相关的状态,理论上来讲不会影响应用的运行,但在开发及后续维护阶段,我们将花费大量精力去查询状态的变化过程,在多组合组件通信或客户端与服务端有较多交互过程中,我们往往需要去更新、维护并监听每一个组件的状态,在这种情况下,如果有一种可以对状态做集中管理的地方是不是会更好呢?
状态管理好比是一个集中在一处的配置箱,当需要更新状态的时候,我们仅对这个黑箱进行输入,而不用去关心状态是如何分发到每一个组件内部的,这可以让开发者将精力更好的放在业务逻辑上。
但状态管理并不是必需品,当你的UI层比较简单、没有较多的交互去改变状态的场景下,使用状态管理方式反倒会让你的项目变的复杂。例如Redux的发明者Dan Abramov就说过这样一句话:
只有遇到React实在解决不了的问题,你才需要Redux。
一般来讲,在以下场景下你或许需要使用状态管理机制去维护应用:
- 用户操作较为繁琐,导致组件间需要有状态依赖关系,如根据多筛选条件来控制其他组件的功能。
- 客户端权限较多且有不同的使用方式,如管理层、普通层级等。
- 客户端与服务端有大量交互,例如请求信息实时性要求较高导致需要保证鲜活度。
- 前端数据缓存部分较多,如记录用户对表单的提交前操作、分页控制等。
Redux之类的状态管理库充当了一个应用的业务模型层,并不会受限于如React之类的View层。
与react结合使用
原理
数据流向
我们先来看一下一个完整的Redux数据流是怎样的:
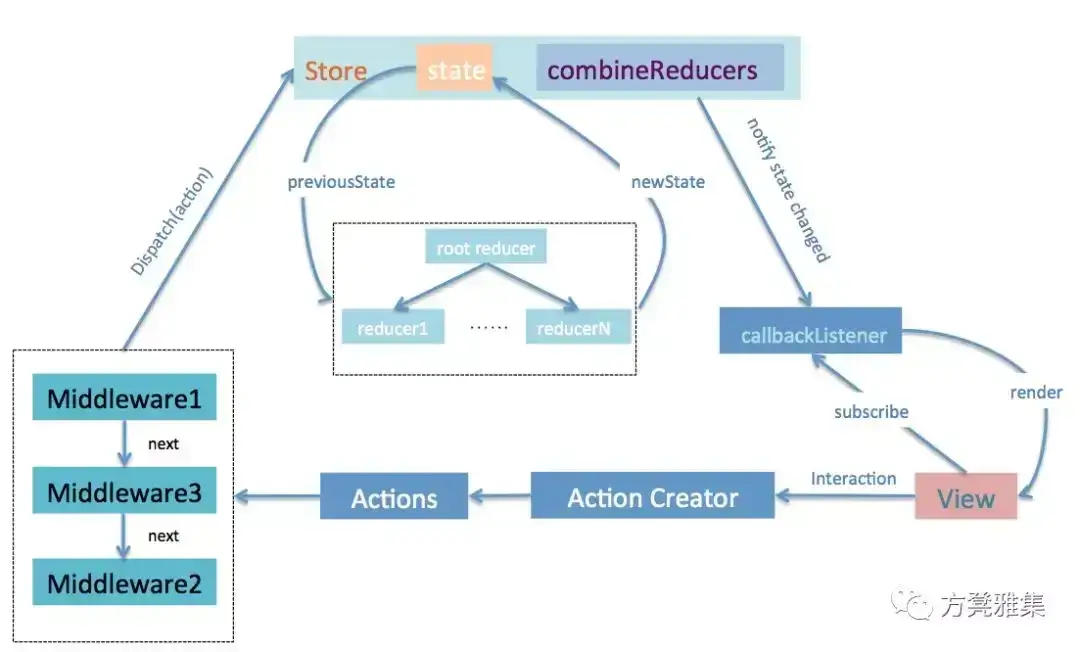
setState机制
理想情况
setState是“异步”的,调用setState只会提交一次state修改到队列中,不会直接修改this.state。
等到满足一定条件时,react会合并队列中的所有修改,触发一次update流程,更新this.state。
因此setState机制减少了update流程的触发次数,从而提高了性能。
由于setState会触发update过程,因此在update过程必经的生命周期中调用setState会存在循环调用的风险。
另外如果要监听state更新完成,可以使用setState方法的第二个参数,回调函数。在这个回调中读取this.state就是已经批量更新后的结果。
特殊情况
在实际开发中,setState的表现有时会不同于理想情况。主要是以下两种。
- 在mount流程中调用setState。
- 在setTimeout/Promise回调中调用setState。
在第一种情况下,不会进入update流程,队列在mount时合并修改并render。
在第二种情况下,setState将不会进行队列的批更新,而是直接触发一次update流程。
这是由于setState的两种更新机制导致的,只有在批量更新模式中,才会是“异步”的。
useState的实现原理
基本用法
import React, { useState } from "react";
import ReactDOM from "react-dom";
function App() {
const [count, setCount] = useState(0);
return (
<div>
<p>count: {count}</p>
<button
onClick={() => setCount(count + 1)}
>
+1
</button>
</div>
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);按照React 16.8.0版本之前的机制,我们知道如果某个组件是函数组件,则这个function就相当于Class组件中的render(),不能拥有自己的状态(故又称其为无状态组件,stateless components),所以数据(输入)必须是来自父组件的props。
而在>=16.8.0中,函数组件支持通过使用Hooks来为其引入state的能力,例如上面所展示的例子:这个App组件提供了一个按钮,每次点击这个都会执行setCount使得count增加1,并更新在视图上。
模拟实现
React.useState() 里都做了些什么:
- 将初始值赋给一个变量我们称之为 state
- 返回这个变量 state 以及改变这个 state 的回调函数我们称之为 setState
- 当 setState() 被调用时, state 被其传入的新值重新赋值,并且更新根视图
function useState(initialState) {
let _state = initialState;
const setState = (newState) => {
_state = newState;
ReactDOM.render(<App />, rootElement);
};
return [_state, setState];
}- 每次更新时,函数组件会被重新调用,也就是说useState()会被重新调用,为了使state的新值被记录(而不是一直被重新赋上initialState),需要将其提到外部作用域声明。
let _state;
function useState(initialState) {
_state = _state === undefined ? initialState : _state;
const setState = (newState) => {
_state = newState;
ReactDOM.render(<App />, rootElement);
};
return [_state, setState];
}通过时上面的处理,目前暂时是达到了React.useState()一样的效果。
- 但是,如果添加多个useState(),就一定会出现BUG了。因为当前的_state只能存放一个单一变量。如果我将_state改成数组存储呢?让这个数组_state根据当前操作useState()的索引向内添加state。
let _state = []
let _index = 0
function useState(initialState) {
let curIndex = _index; // 记录当前操作的索引
_state[curIndex] = _state[curIndex] === undefined
? initialState
: _state[curIndex]
const setState = (newState) => {
_state[curIndex] = newState;
ReactDOM.render(<App />, rootElement);
/**
* 每更新一次都需要将_index归零,才不会不断重复增加_state
* 说明1:
* useState只在每次渲染App函数的时候执行,
* 将_index重置为0是为了下一次render App时,
* useState重新从_index为0开始计算顺序
*
* 说明2:
* 其实也可以在最后一个useState触发后将_index归0,
* 或者App组件函数调用完毕后归0,
* 只是逻辑不太好写
*/
_index = 0;
}
// 下一个操作的索引
_index += 1
return [_state[curIndex], setState];
}虽然通过使用数组存储_state成功模拟了多个useState()的情况,但这要求我们保证useState()的调用顺序,所以我们不能在循环、条件或嵌套函数中调用useState(),这在React.useState()同样要求,官网还给出了专门的解释。
实际上,React并不是真的是这样实现的。上面提到的_state其实对应React的memoizedState,而_index实际上是利用了链表。
数据结构和算法
除了个别岗位,大部分前端都是很偏向应用层面的(不管是电商还是低代码平台)。对数据结构和算法的要求并不高。
但是为什么面试的时候还是有很多人喜欢问算法这块的东西呢?因为它是一个很有区分度的话题。 算法差的人,写业务代码的能力有好有差,上下限都很大。算法好的人,往往下限不会太低(但上限也未必高)。 就为了这一点,面一些算法题就已经无可厚非了。 当然还有些情况纯粹是面试官偷懒,这就不赘述了。
一个人是否擅长编写复杂的业务逻辑,主要是看他是否擅长进行反思总结。 这是一个需要长期编码、迭代、反思、重构的过程。靠面对算法题进行乌托邦式实验是没有多少帮助的。
个人的建议是,你需要了解一些基本的数据结构和算法知识,但不必过多涉猎。 以我自己为例,我并不擅长数据结构和算法,但是仅仅是因为有所了解,也就可以写出类似这样的文字:
在我自己的电脑上,编译1组路由时用时大概是2分钟,同时编译2组路由时用时大概5分钟, 同时编译3组路由时用时大概30分钟,同时编译4组路由时用时大概75分钟。 可以发现编译时长和代码量总体上并不是一个线性增长的关系。 猜测是因为计算需要从入口文件开始去爬引用到的文件,然后一层层去爬,不同入口爬到的文件有交集文件,也有各自独立的文件, 毛估估很像是数据结构里的图(遍历时间复杂度为O(N^2)),而且我大致去算了下也能找到一个合适的模拟函数曲线, 不过鉴于样本量有限,每个页面大小差别也很大,也没啥科学性。 我在IDE里跳转到webpack源码后发现不是很好确认这点,便作罢。……
以上节选自2021年撰写的博文《编译要1小时的Webpack项目优化思路和条件编译方案》。
我认为需要了解的数据结构和算法知识如下:
- 冒泡排序。
- 二分法查找。
- 链表、循环链表、合并两个排序链表。
- 栈、单调栈。
- 快排。
- 队列。
- 二叉树:如何构造、前/中/后序遍历的递归与非递归实现、层次遍历。
- 图:了解下概念和时间、空间复杂度即可。
在你还没法清楚地知道是否需要了解这块的情况下,了解这些内容已经足够了。
Bubble Sort 冒泡排序
冒泡排序的思想是,比较相邻两个数,如果前者大于后者,就把两个数交换位置;这样一来,第一轮就可以选出一个最大的数放在最后面;那么经过n-1轮,就完成了所有数的排序。
基本实现
function bubbleSort (arr) {
let len = arr.length
while (len > 0) {
for (let i = 0; i < len - 1; i++) {
if (arr[i] > arr[i + 1]) {
const temp = arr[i]
arr[i] = arr[i + 1]
arr[i + 1] = temp
}
}
len--
}
return arr
}优化思路
在上面的方案中,如果我们经过第一轮排序就成功将所有元素正确排好序了的话,仍然会继续遍历。 这里可以每一轮开始遍历时,加一个初始值为false的changeFlag标记, 当本轮有进行过换位的话,就接着遍历下一轮。 当本轮没有进行过换位操作的话,则说明已经排序完毕,就可以直接退出循环,没必要接着遍历了。
具体实现还是比较简单的,大家自行尝试,这里就不写了。
Dichotomy 二分法
在已从小到大排序的数组(数组内元素均为数字)中找到给定的数字对应的下标
function dichotomySearch (arr, num) {
var low = 0
var high = arr.length - 1
var mid = Math.floor((low + high) / 2)
// while循环的判断条件是high - low > 1
while (high - low > 1) {
if (num === arr[low]) {
return low
}
if (num === arr[high]) {
return high
}
if (num === arr[mid]) {
return mid
}
if (num > arr[mid]) {
low = mid
mid = Math.floor((low + high) / 2)
} else {
high = mid
mid = Math.floor((low + high) / 2)
}
}
// 如果没找到,则返回-1
return -1
}求一个数n的平方根
/**
* 计算平方根
* @param {number} n 需要求平方根的目标数字
* @param {number} deviation 偏离度(允许的误差范围)
* @return {number} 返回平方根
*/
function square (n, deviation) {
let max = n
let min = 0
let mid = (max - min) / 2
const isAlmost = (val) => (
(val * val - n <= deviation) &&
(n - val * val <= deviation)
)
while (isAlmost(mid) === false) {
if (mid * mid > n) {
max = mid
mid = (max + min) / 2
} else if (mid * mid < n) {
min = mid
mid = (max + min) / 2
}
}
return mid
}Link 链表
约瑟夫环问题
据说著名犹太历史学家 Josephus有过以下的故事:
在罗马人占领乔塔帕特后,39 个犹太人与Josephus及他的朋友(共41个人)躲到一个洞中, 39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式: 41个人排成一个圆圈,由第1个人开始报数,每报数到第3人该人就必须自杀, 然后再由下一个重新报数,直到所有人都自杀身亡为止。 然而Josephus 和他的朋友并不想遵从。 首先从一个人开始,越过k-2个人(因为第一个人已经被越过), 并杀掉第k个人。接着,再越过k-1个人,并杀掉第k个人。 这个过程沿着圆圈一直进行,直到最终只剩下一个人留下,这个人就可以继续活着。 问题是一开始要站在什么地方才能避免自杀?Josephus要他的朋友先假装遵从, 他将朋友与自己安排在第16个与第31个位置,于是逃过了这场死亡游戏。
数组下标方案
// 初始状态各坐标都赋值为0,被选中则标记为1
const arr = new Array(41).fill(0)
const key = 3
// 最后会剩下2人,走掉39人
const numOfPeopleToLeave = arr.length - 2
let count = 0
while (arr.filter((checked) => checked === 1).length < numOfPeopleToLeave) {
for (let i = 0, len = arr.length; i < len; i++) {
// 如果数组中该坐标已被标记,则直接跳过
if (arr[i] === 1) {
continue
}
count++
// 每到第key个人
if (count === key) {
// 标记数组中该坐标已被占位
arr[i] = 1
count = 0
}
}
}
// 输出标记情况,标记为0的表示未被选中,标记为1表示被选中
console.log(arr)
// 输出被留下的人(值为0)对应的坐标
console.log(
arr
.map((checked, idx) => checked === 0 ? idx : undefined)
.filter((idx) => typeof idx === 'number')
)链表方案(单向循环链表)
如果是单向循环链表的话,对单个链表节点,有:
function Node (next) {
this.next = next || null
}每当计数计到3时,将当前node节点的上一个节点的next指向当前node节点的下一个节点, 然后继续从1开始计数,代码就不写了,虽说数据结构上和数组下标方案不同, 逻辑是差不多的,while循环的终止条件可以换成当当前节点next指向null时。
合并2个排序链表
输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
递归版本
function merge(pHead1, pHead2) {
let node = null;
if (pHead1 === null) {
return pHead2;
} else if (pHead2 === null) {
return pHead1;
}
if (pHead1.val >= pHead2.val) {
node = pHead2;
node.next = merge(pHead1, pHead2.next);
} else {
node = pHead1;
node.next = merge(pHead1.next, pHead2);
}
return node;
}非递归版本
function merge(pHead1, pHead2) {
if (pHead1 === null) {
return pHead2;
} else if (pHead2 === null) {
return pHead1;
}
let node = null;
let startNode = null;
if (pHead1.val <= pHead2.val) {
node = pHead1;
startNode = pHead1;
pHead1 = pHead1.next;
} else {
node = pHead2;
startNode = pHead2;
pHead2 = pHead2.next;
}
while (pHead1 !== null && pHead2 !== null) {
if (pHead1.val <= pHead2.val) {
node.next = pHead1;
node = pHead1;
pHead1 = pHead1.next;
} else {
node.next = pHead2;
node = pHead2;
pHead2 = pHead2.next;
}
}
if (pHead1 !== null) {
node.next = pHead1;
} else if (pHead2 !== null) {
node.next = pHead2;
}
return startNode;
}快速排序与分治法
介绍
快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高, 因此经常被采用,再加上快速排序思想——分治法也确实实用, 因此很多软件公司的笔试面试,包括像腾讯,微软等知名IT公司都喜欢考这个。
分治法
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。 它采用了一种分治的策略,通常称其为分治法(Divide-and-Conquer Method)。
该方法的基本思想是:
- 先从数列中取出一个数作为基准数(一般是以中间项为基准);
- 分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边;
- 再对左右区间重复第二步,直到各区间只有一个数。
代码实现
function quickSort (arr) {
if (arr.length <= 1) {
return arr
}
// pivot:枢纽、中心点
var pivotIndex = Math.floor(arr.length / 2)
// 找基准,并把基准从原数组中删除
var pivot = arr.splice(pivotIndex, 1)[0]
// 定义左右数组
var left = []
var right = []
// 比基准小的放在left,比基准大的放在right
arr.forEach(function (val) {
if (val <= pivot) {
left.push(val)
} else {
right.push(val)
}
})
// 递归
return quickSort(left).concat([pivot], quickSort(right))
}Stack 栈
括号闭合问题
问题描述
给定一个只包括'(',')','{','}','[',']'的字符串s, 判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
如:
- 有效的字符串:
"()"、"()[]{}"、"{[]}"。 - 无效的字符串:
"(]"、"([)]"。
解法
function isStrValid (str) {
const matches = ['()', '[]', '{}']
const arr = []
for (let i = 0, len = str.length; i < len; i++) {
const char = str.charAt(i)
if (arr.length === 0) {
arr.push(char)
continue
}
const last = arr[arr.length - 1]
if (matches.includes(last + char)) {
arr.pop()
continue
}
arr.push(char)
}
return arr.length === 0
}字符消消乐
问题描述
给定一个字符串,消除其中所有的字符串 ac 和 b,如果消掉之后获得的新字符串中仍存在可消内容则需要继续消,直到没有可继续消的字符串为止。
比如字符串 aaaaaaaaabbbbbbbcccccbbbbbcccc 经过处理后应该得到空字符串。
解决方案
function deleteMatchStr (str) {
const arr = str.split('')
const tempArr = []
arr.forEach((item) => {
const last = tempArr.length ? tempArr[tempArr.length - 1] : ''
if (last + item === 'ac') {
tempArr.pop()
return
}
if (item !== 'b') {
tempArr.push(item)
}
})
return tempArr.join('')
}
deleteMatchStr('aaaaaaaaabbbbbbbcccccbbbbbcccc')Monotone stack 单调栈
单调栈是一种特殊的栈结构,其内部元素的排序是单调朝一个方向的。 在许多数组的范围查询问题上,用上单调栈可显著降低时间复杂度——毕竟其时间复杂度只有O(N)。
去重返回最小数
这是LeetCode里的一道难度级别显示为中等的题目。
题目:给定一串数字, 去除字符串中重复的数字, 而且不能改变数字之间的顺序, 使得返回的数字最小 "23123" => "123" "32134323" => "1342"。
解法如下:
function handleArray(strings) {
const array = strings.split('')
const stack = []
const obj = {}
for (let i = 0, len = array.length; i < len; i++) {
const item = array[i]
if (stack.length === 0) {
stack.push(item)
continue
}
const lastStackItem = stack[stack.length - 1]
while (lastStackItem >= item && array.slice(i).includes(lastStackItem)) {
stack.pop()
}
if (!stack.includes(item)) {
stack.push(item)
}
}
return stack.join('')
}
handleArray('23123')
handleArray('32134323')二叉搜索树及其遍历
排序类型
- 前序遍历(根节点 > 左子树 > 右子树):8 => 3 => 1 => 6 => 4 => 7 => 10 => 14 => 13
- 中序遍历(左子树 > 根节点 > 右子树):1 => 3 => 4 => 6 => 7 => 8 => 10 => 13 => 14
- 后序遍历(左子树 > 右子树 > 根节点):1 => 4 => 7 => 6 => 3 => 13 => 14 => 10 => 8
- 层次遍历(从上往下一层层来):8 => 3 => 10 => 1 => 6 => 14 => 4 => 7 => 13
二叉树的构造
// 节点对象的构造函数
function Node (data, left, right) {
this.data = data
this.left = left
this.right = right
}
Node.prototype.getData = function () {
return this.data
}
// 二叉搜索树的构造函数
function BST () {
this.root = null
}
// 插入方法
BST.prototype.insert = function (data) {
const n = new Node(data, null, null)
if (this.root === null) {
this.root = n
return
}
let current = this.root
let parent
while (true) {
parent = current
if (data < current.data) {
current = current.left
if (current === null) {
parent.left = n
break
}
} else {
current = current.right
if (current === null) {
parent.right = n
break
}
}
}
}
const nums = new BST()
nums.insert(8)
nums.insert(3)
nums.insert(10)
nums.insert(1)
nums.insert(6)
nums.insert(14)
nums.insert(4)
nums.insert(7)
nums.insert(13)前/中/后序遍历的递归实现
这个算法很好实现:
// 前序遍历二叉树
BST.prototype.preOrder = function (node) {
if (node !== null) {
console.log(node.getData())
this.preOrder(node.left)
this.preOrder(node.right)
}
}
// 中序遍历二叉树
BST.prototype.inOrder = function (node) {
if (node !== null) {
this.inOrder(node.left)
console.log(node.getData())
this.inOrder(node.right)
}
}
// 后序遍历二叉树
BST.prototype.postOrder = function (node) {
if (node !== null) {
this.postOrder(node.left)
this.postOrder(node.right)
console.log(node.getData())
}
}
// 测试
nums.inOrder(nums.root)
// 依次输出如下内容:
// 1 3 4 6 7 8 10 13 14前序遍历的非递归实现
根据前序遍历访问的顺序,优先访问根结点,然后再分别访问左孩子和右孩子。 即对于任一结点,其可看做是根结点,因此可以直接访问,访问完之后,若其左孩子不为空, 按相同规则访问它的左子树;访问其左子树后,再访问它的右子树。因此其处理过程如下:
对于任一结点P:
访问结点P,并将结点P入栈;
判断结点P的左孩子是否为空,
- 若为空,则取栈顶结点并进行出栈操作,并将栈顶结点的右孩子置为当前的结点P,循环至1;
- 若不为空,则将P的左孩子置为当前的结点P;
直到P为NULL并且栈为空,则遍历结束。
function preOrder (bst) {
let p = bst.root
const arr = []
while (p !== null || arr.length > 0) {
while (p !== null) {
console.log(p.getData())
arr.push(p)
p = p.left
}
if (arr.length > 0) {
p = arr.pop()
p = p.right
}
}
}中序遍历的非递归实现
根据中序遍历的顺序,对于任一结点,优先访问其左孩子,而左孩子结点又可以看做一根结点, 然后继续访问其左孩子结点,直到遇到左孩子结点为空的结点才进行访问, 然后按相同的规则访问其右子树。因此其处理过程如下:
对于任一结点P,
若其左孩子不为空,则将P入栈并将P的左孩子置为当前的P,然后对当前结点P再进行相同的处理;
若其左孩子为空,则取栈顶元素并进行出栈操作,访问该栈顶结点,然后将当前的P置为栈顶结点的右孩子;
直到P为NULL并且栈为空则遍历结束。
function inOrder (bst) {
let p = bst.root
const arr = []
while (p !== null || arr.length > 0) {
while (p !== null) {
arr.push(p)
p = p.left
}
if (arr.length > 0) {
p = arr.pop()
console.log(p.getData())
p = p.right
}
}
}后序遍历的非递归实现
后续遍历比前中/序遍历是要麻烦一些的。
遍历顺序:左右根。左路的遍历和上面的思路是类似的,区别是元素出栈时不能直接打印, 因为如果有没访问过右侧子树的话,需要先访问右侧子树。 右侧子树访问结束后才访问根节点。
function postOrder (bst) {
let p = bst.root
let last = null
const arr = []
while (p !== null || arr.length > 0) {
while (p !== null) {
arr.push(p)
p = p.left
}
if (arr.length > 0) {
p = arr[arr.length - 1] // 栈顶元素
// 当p不存在右子树或右子树已被访问过的话,直接访问当前节点数据
if (!p.right || p.right === last) {
p = arr.pop()
console.log(p.getData())
last = p // 记录上一次访问过的节点
p = null // 这个容易漏掉,避免下个循环继续访问左子树
} else {
p = p.right
}
}
}
}层次遍历
递归方案
// 遍历到某个节点后,将该节点的值推入到指定深度对应的数组中
function level(node, idx, arr) {
if (arr.length < idx) {
arr.push([])
}
arr[idx - 1].push(node.value)
if (node.left !== null) {
level(node.left, idx + 1, arr)
}
if (node.right !== null) {
level(node.right, idx + 1, arr)
}
}
function levelOrder(root) {
if (root === null) {
return []
}
const arr = []
level(root, 1, arr)
return arr
}非递归方案
使用队列实现。
function levelOrder(root) {
const arr = []
if (root === null) {
return arr
}
const queue = [root]
while (queue.length > 0) {
const currentLevel = []
const currentLevelLength = queue.length
for (let i = 0; i <= currentLevelLength; i++) {
const node = queue.pop()
currentLevel.push(node.value)
if (node.left !== null) {
queue.push(node.left)
}
if (node.right !== null) {
queue.push(node.right)
}
}
arr.push(currentLevel)
}
return arr
}其他
实现对象深拷贝
function deepClone(obj) {
// if not object
if (typeof obj !== 'object') {
return obj
}
// if null
if (obj === null) {
return null
}
// if array
if (Array.isArray(obj)) {
return obj.map((elem) => deepClone(elem))
}
// if obj
const tempObj = {}
for (const key in obj) {
if (obj.hasOwnProperty(key)) {
tempObj[key] = deepClone(obj[key])
}
}
return tempObj
}数组扁平化
问题
- 将数组中的所有数组元素扁平化成顶层元素,返回新数组,不修改原数组
- 增加去重功能,重复的为基本数据类型的元素不显示(只是不显示重复的部分,即如果有两个2,第二个重复的2不显示,第一个2还是要显示的)
解答
function flattenArray(arr) {
if (!Array.isArray(arr)) {
throw new TypeError('You should pass in an Array parameter')
}
const tempArr = []
const tempObj = {}
void function recurison(item) {
if (Array.isArray(item)) {
item.forEach(recurison)
} else {
if (typeof item === 'object') {
tempArr.push(item)
} else if (!tempObj[item]) {
tempArr.push(item)
tempObj[item] = true
}
}
}(arr)
return tempArr
}数字数组奇偶排序
问题
将数组中奇数放在右边,偶数放在左边,不允许使用额外空间。
说明:从一个数组中间删除元素splice的运行代价是比较大的。
方案
const arr = [1, 4, 5, 2, 3, 7, 8]
arr.sort(function (a, b) {
return a % 2 !== 0
})求数组中第二大的数
问题
要求:
- 不能对这个数组进行整体排序;
- 若要用循环,只能一重循环;
- 不使用额外空间。
解答
思路:把最大的数字标记为null,然后再求此时的最大数字。
const arr = [1, 3, 5, 2, 7, 6]
arr[arr.indexOf(Math.max.apply(null, arr))] = null
Math.max.apply(null, arr)90度旋转二维数组
const rawArr = [
['1', '2', '3', '4', '5'],
['6', '7', '8', '9', 'a'],
['b', 'c', 'd', 'e', 'f'],
['g', 'h', 'i', 'j', 'k'],
['l', 'm', 'n', 'o', 'p']
]使用新数组再覆盖原数组
如果直接先生成一个新数组, 然后逐个将旧数组里的元素赋值到新数组中的对应位置,那就很简单了。
先列数据看规律:
- (0, 0) => (0, 4)
- (0, 1) => (1, 4)
- (0, 2) => (2, 4)
- (0, 3) => (3, 4)
- (0, 4) => (4, 4)
- ...
- (2, 0) => (0, 2)
- (2, 1) => (1, 2)
- (2, 2) => (2, 2)
- (2, 3) => (3, 2)
- (2, 4) => (4, 2)
- ...
- (4, 0) => (0, 0)
- (4, 1) => (1, 0)
- (4, 2) => (2, 0)
- (4, 3) => (3, 0)
- (4, 4) => (4, 0)
可以看出规律是:oldArray(x, y) => newArray(y, 5 - 1 - x)
const rawArr = [
['1', '2', '3', '4', '5'],
['6', '7', '8', '9', 'a'],
['b', 'c', 'd', 'e', 'f'],
['g', 'h', 'i', 'j', 'k'],
['l', 'm', 'n', 'o', 'p']
]
function rotate90(arr) {
const length = arr.length
// 直接这样写是不行的,5个子数组实际对应的是同一个对象,修改一个其实是5个子数组里的值都变了
// const tempArr = new Array(length).fill(new Array(length))
// 这里去掉fill(1)的话就无法构造成二维数组了
const tempArr = new Array(5).fill(1).map(() => new Array(5))
arr.forEach((row, rowIdx) => {
row.forEach((col, colIdx) => {
tempArr[colIdx][length - rowIdx - 1] = arr[rowIdx][colIdx]
console.log(`(${rowIdx}, ${colIdx}) => (${colIdx}, ${length - rowIdx - 1})`)
})
})
return tempArr
}
console.log(rotate90(rawArr))画星号
问题描述
实现一个函数,入参为数字 n,输出如下图所示的字符串。

解决方案
function drawAsterisk(n) {
function getRepeatStr (num, repeatStr) {
return new Array(num).fill(repeatStr).join('')
}
function log (str) {
console.log(str)
}
const arr = []
const sumLength = 2 * n - 1
for (let i = 0; i < n - 1; i++) {
const numOfStar = 2 * i + 1
const numOfSpaces = sumLength - numOfStar
const sideSpaces = getRepeatStr(numOfSpaces / 2, ' ')
arr.push(sideSpaces + getRepeatStr(numOfStar, '*') + sideSpaces)
}
// 画上半部分
arr.forEach(log)
// 画中间一行
console.log(getRepeatStr(2 * n - 1, '*'))
// 下半部分与上半部分层是轴对称的,直接 `reverse()` 反转下就可以直接用
arr.reverse()
// 画下半部分
arr.forEach(log)
}
drawAsterisk(2)最佳实践
“最佳实践”只是一种习惯说法,是大家总结出的一些较好的代码实践方式,落地到具体项目中时,它并不一定就是最好的,各位可带着自己的思考进行阅读。
代码要精炼。代码量的多少直接影响可读性。这简直是一句正确的废话,但又因为太朴素,总是被人忽略。在没有其他问题/原因的情况下,3行代码就是比5行代码好。
代码隔离。一言以蔽之,就是在说代码的模块化。提到模块化,大家的第一反应就是import/export和代码复用。其实可以多一些思考。有时候我们不是为了复用,只是为了把代码分开:
- 将次要代码挪到单独的文件提高主要代码的可读性。
- 将赶业务临时写的脏代码放到单独的文件,便于后期重构。这里要注意函数的输入和输出,它们比函数内部的具体实现的优先级要高得多。只要输入和输出控制好了,加上一个友好的注释,即便内部实现非常脏,对于整体系统而言一点不良影响都没有。
设计模式
设计模式是前人总结出来的一些典型的代码设计方案。了解一下,对提升架构能力会有所帮助。
设计模式的分类
根据设计模式的参考书《Design Patterns - Elements of Reusable Object-Oriented Software》中所提到的,总共有23种设计模式。 这些模式可以分为三大类:
创建型模式(Creational Patterns):这些设计模式提供了一种在创建对象的同时隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象。这使得程序在判断针对某个给定实例需要创建哪些对象时更加灵活。
- 工厂模式(Factory Pattern)
- 抽象工厂模式(Abstract Factory Pattern)
- 单例模式(Singleton Pattern)
- 建造者模式(Builder Pattern)
- 原型模式(Prototype Pattern)
结构型模式(Structural Patterns):这些设计模式关注类和对象的组合。
- 适配器模式(Adapter Pattern)
- 桥接模式(Bridge Pattern)
- 过滤器模式(Filter、Criteria Pattern)
- 组合模式(Composite Pattern)
- 装饰器模式(Decorator Pattern)
- 外观模式(Facade Pattern)
- 享元模式(Flyweight Pattern)
- 代理模式(Proxy Pattern)
行为型模式(Behavioral Patterns):这些设计模式特别关注对象之间的通信。
- 责任链模式(Chain of Responsibility Pattern)
- 命令模式(Command Pattern)
- 解释器模式(Interpreter Pattern)
- 迭代器模式(Iterator Pattern)
- 中介者模式(Mediator Pattern)
- 备忘录模式(Memento Pattern)
- 观察者模式(Observer Pattern)
- 状态模式(State Pattern)
- 空对象模式(Null Object Pattern)
- 策略模式(Strategy Pattern)
- 模板模式(Template Pattern)
- 访问者模式(Visitor Pattern)
另外还有一些由Sun Java Center提出的J2EE 设计模式,这些模式特别关注表示层:
- MVC 模式(MVC Pattern)
- 业务代表模式(Business Delegate Pattern)
- 组合实体模式(Composite Entity Pattern)
- 数据访问对象模式(Data Access Object Pattern)
- 前端控制器模式(Front Controller Pattern)
- 拦截过滤器模式(Intercepting Filter Pattern)
- 服务定位器模式(Service Locator Pattern)
- 传输对象模式(Transfer Object Pattern)
设计模式的6大原则
- Open Close Principle:开放封闭原则。面向扩展扩展开放(Open for Extension),面向修改封闭(Closed for Modification)。想要使程序的扩展性好,易于维护和升级,想要使用接口和抽象类。
- Liskov Substitution Principle。里氏代换原则。用子类替换基类。
- Dependence Inversion Principle。依赖倒转原则:针对接口编程,依赖于抽象而不依赖于具体。
- Interface Segregation Principle。接口隔离原则:使用多个隔离的接口,比使用单个接口要好。降低类之间的耦合度。
- Demeter Principle。迪米特法则,又称最少知道原则:一个实体应尽量少地与其他实体之间发生相互作用,使得系统功能模块相对独立。
- Composite Reuse Principle。合成/复用原则是指:尽量使用合成/聚合的方式,而不是使用继承。
观察者模式
什么是观察者模式
提示
观察者模式(Observer) 通常又被称为发布-订阅者模式或消息机制, 它定义了对象间的一种一对多的依赖关系, 只要当一个对象的状态发生改变时, 所有依赖于它的对象都得到通知并被自动更新, 解决了主体对象与观察者之间功能的耦合, 即一个对象状态改变给其他对象通知的问题。
下面这段代码就是一种发布-订阅模式:
document.querySelector('#btn').addEventListener('click', function () {
alert('You click this button');
}, false)除了我们常见的 DOM 事件绑定外,观察者模式应用的范围还有很多~
比如 vue2 框架里不少地方都涉及到了观察者模式,比如:
数据的双向绑定
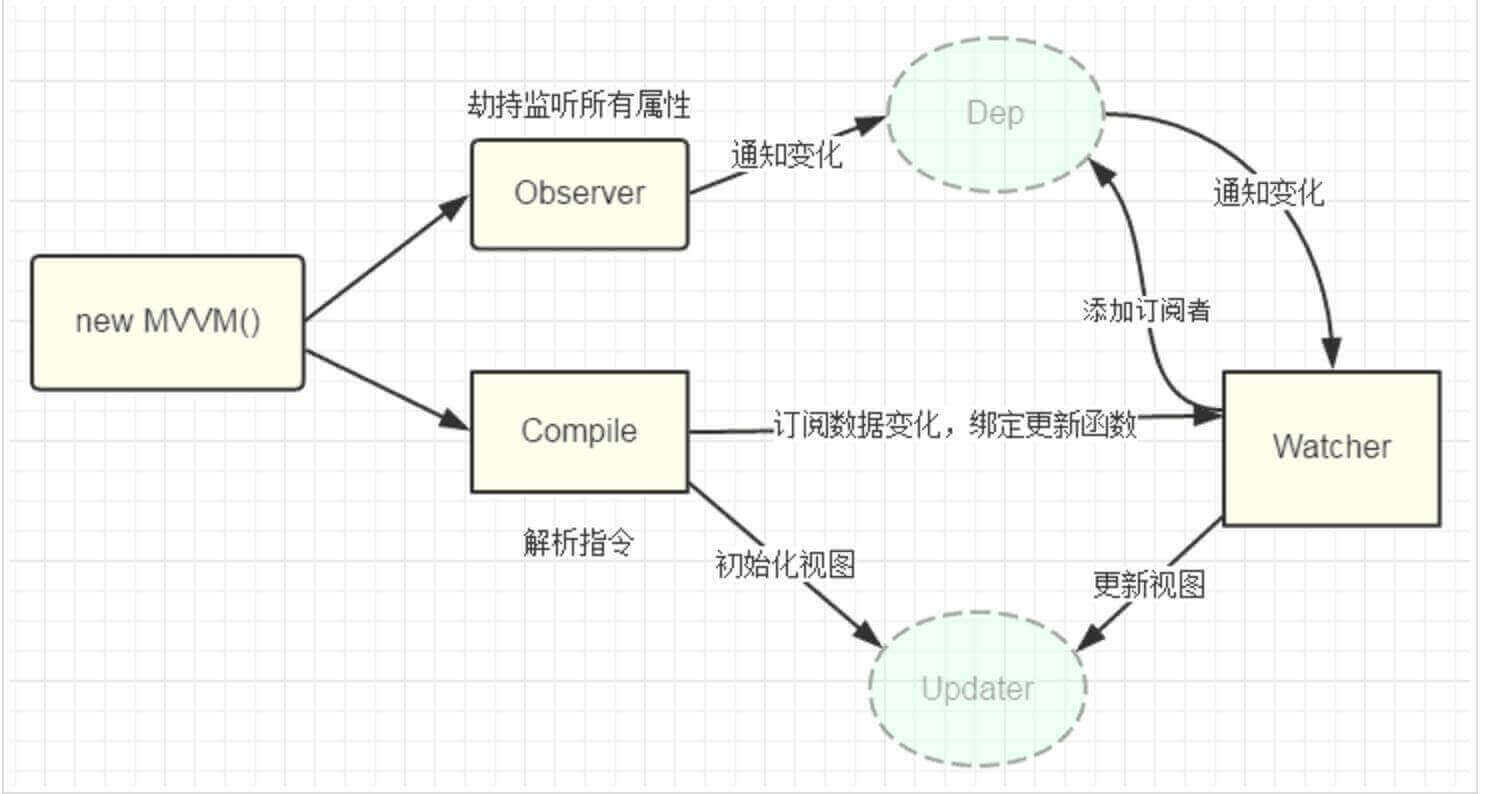
利用Object.defineProperty()对数据进行劫持, 设置一个监听器Observer,用来监听所有属性, 如果属性上发上变化了,就需要告诉订阅者Watcher去更新数据, 最后指令解析器Compile解析对应的指令, 进而会执行对应的更新函数,从而更新视图,实现了双向绑定。
子组件与父组件通信
Vue中我们通过props完成父组件向子组件传递数据, 子组件与父组件通信我们通过自定义事件即$on、$emit来实现, 其实也就是通过$emit来发布消息,并对订阅者$on做统一处理。
创建一个观察者
首先我们需要创建一个观察者对象,它包含一个消息容器和三个方法,分别是:
- on:订阅消息
- off:取消订阅消息
- publish:发送订阅消息
const Observe = (function() {
// 防止消息队列暴露而被篡改,将消息容器设置为私有变量
let __message = {};
return {
// 注册消息接口
on: function(type, fn) {
// 如果此消息不存在,创建一个该消息类型
if (typeof __message[type] === 'undefined') {
// 将执行方法推入该消息对应的执行队列中
__message[type] = [fn];
} else {
// 如果此消息存在,直接将执行方法推入该消息对应的执行队列中
__message[type].push(fn);
}
},
// 发布消息接口
publish: function(type, args) {
// 如果该消息没有注册,直接返回
if (!__message[type]) return;
// 定义消息信息
const events = {
type, // 消息类型
args: args || {} // 参数
}
// 遍历执行函数
for (let i = 0, len = __message[type].length; i < len; i++) {
// 依次执行注册消息对应的方法
__message[type][i].call(this, events)
}
},
// 移除消息接口
off: function(type, fn) {
// 如果消息执行队列存在
if (__message[type] instanceof Array) {
// 从最后一条依次遍历(之所以从最后一个开始遍历,是因为下面会用到splice)
for (let i = __message[type].length - 1; i >= 0; i--) {
// 如果存在该执行函数则移除相应的动作
__message[type][i] === fn && __message[type].splice(i, 1);
}
}
}
}
})();使用:
// 订阅消息
Observe.on('say', function (data) {
console.log(data.args.text);
})
Observe.on('success',function () {
console.log('success')
});
//发布消息
Observe.publish('say', { text : 'hello world' } )
Observe.publish('success');我们在消息类型为say、success的消息中注册了两个方法,其中有一个接受参数,另一个不需要参数, 然后通过publish发布say和success消息,结果跟我们预期的一样, 控制台输出了 hello world 以及 success。
实现EventBus
class EventBus {
constructor() {
this.event = Object.create(null);
};
// 注册事件
on(name, fn) {
if(!this.event[name]){
// 一个事件可能有多个监听者
this.event[name]=[];
};
this.event[name].push(fn);
};
// 触发事件
emit(name, ...args) {
//给回调函数传参
this.event[name] && this.event[name].forEach(fn => {
fn(...args)
});
};
// 只被触发一次的事件
once(name, fn) {
// 在这里同时完成了对该事件的注册、对该事件的触发,并在最后取消该事件。
const cb=(...args)=>{
//触发
fn(...args);
//取消
this.off(name,fn);
};
//监听
this.on(name, cb);
};
// 取消事件
off(name, offCb) {
if(this.event[name]){
const index = this.event[name].findIndex((fn)=>{
return offCb === fn;
})
if (index !== -1) {
this.event[name].splice(index, 1);
if(!this.event[name].length){
delete this.event[name];
}
}
}
}
}单例模式
通用的单例构造函数:
const getSingle = function (fn) {
let result
return function () {
return result || (result = fn.apply(this, arguments))
}
}// 单例构造函数
function CreateSingleton (name) {
this.name = name;
this.getName();
};
// 获取实例的名字
CreateSingleton.prototype.getName = function() {
console.log(this.name)
};
// 单例对象
const Singleton = (function(){
var instance;
return function (name) {
if(!instance) {
instance = new CreateSingleton(name);
}
return instance;
}
})();
// 创建实例对象1
const a = new Singleton('a');
// 创建实例对象2
const b = new Singleton('b');
// 返回true
console.log(a===b);
// 返回true
console.log(a.name === b.name)使用单例模式
责任链模式、观察者模式、策略模式 这三种在日常的前端开发中,经常遇到:
责任链模式通常在分布提交表单中,前一步表单满足后才能进入下一步,例如新建商品、营促销活动等;
观察者模式通常应用在组件之间的通讯中;
策略模式通常用来优化过多的
if/else或switch/case;
那么单例模式有哪些场景使用呢?
不借助第三方库,我们可以使用单例模式来制作一个全局的状态存储。
例如在小程序这种移动端,需要开发一个新建商品的需求,由于商品的属性很多,会将基本信息、规格属性、商品详情(富文本)等做成三个页面,规格属性选择又会多出一个页面。
总共 4 个页面以及各种组件,都需要能共享到“商品”这个对象用来进行回显。
这个时候就可以用单例模式来存储“商品”数据:
// store.js
const PRODUCT_MODEL = Object.freeze({
productName: "",
productBrand: "",
productSkuList: [],
// etc...
});
class Storage {
static getInstance() {
if (!this.instance) {
this.instance = new Storage();
}
return this.instance;
}
constructor() {
this.data = Object.assign({}, PRODUCT_MODEL);
}
init(obj) {
this.data = { ...this.data, ...obj };
}
set(key, value) {
if (!key) {
throw new Error("A store key must be provided");
}
this.data[String(key)] = value;
return this;
}
get(key) {
const value = key ? this.data[String(key)] : this.data;
return value;
}
removeItem(key) {
delete this.data[String(key)];
}
reset(obj = {}) {
this.data = Object.assign({}, PRODUCT_MODEL, obj);
}
}
module.exports = Storage.getInstance();这份 store.js 模块,暴露了几个函数用来共享给页面和组件:
init()用来在编辑模式下回填接口返回的商详数据;reset()用来清空并重置当前存储的数据;javascript// 在保存或某个场景结束操作时,需要重置单例所存储的数据 const store = require("./store.js"); onUnload() { storage.reset(); }set()用来设置某个属性的值,同时它返回了this,这样可以链式调用:javascriptconst store = require("./store.js"); store .set("productName", "商品名称") .set("productBrand", "商品品牌");get()用来获取指定属性或全部属性的值;javascriptconst store = require("./store.js"); onShow() { // 获取全部属性的值 const productInfo = storage.get(); // 获取指定属性的值 const productName = storage.get("productName"); }removeItem()用来移除某个属性的值;
策略模式
策略模式有时是违法最少知识原则的,因为使用者可能要了解所有的 strategy 才能判断应该具体使用哪种 strategy。
例1:
const strategy = new SomeStrategy()
context.setStrategy(strategy)
context.doSomething()例2:
const eventStrategies = {
commandStart: {
editor: async () => {},
},
commandEnd: {
editor: async () => {},
},
*: async () => {}
}
addEventListener((type, msg) => {
const strategy = eventStrategies[type][msg]
if (typeof strategy === 'function') {
strategy()
return
}
eventStrategies['*']()
})外观模式
例1:
class ObjType1 {
static add () {}
}
class ObjType2 {
static add () {}
}
function addElement(type) {
switch (type) {
case 'objType1':
ObjType1.add()
break
case 'objType2':
ObjType2.add()
break
default:
break
}
}
// 调用者无需关心具体有哪些对象类自己去调用对应对象类的 add 静态方法
addElement('objType1')例2:
/**
* 调用者只需要知道对象 id,
* 就可以初始化对象实例,
* 不用关心具体代码是如何判断某个 id 对应的对象是哪个 class 的实例,
* 也不用关心里面的是否有缓存逻辑和是否有优先调用批查询命令替换多次调用单查询命令的情况
* 高级开发可以慢慢完善内部的具体实验,普通开发可以直接开发业务功能,只要确定好输入和输出即可
*/
batchGetElementInstanceList([id1, id2, id3, id4])备忘录模式
本文参考了以下文章:
备忘录模式(Memento Pattern)保存一个对象的某个状态,以便在适当的时候恢复对象。备忘录模式属于行为型模式。
备忘录模式使用三个类 Memento、Originator 和 CareTaker。Memento 包含了要被恢复的对象的状态。Originator 创建并在 Memento 对象中存储状态。Caretaker 对象负责从 Memento 中恢复对象的状态。

创建 Memento 类:
public class Memento {
private String state;
public Memento(String state){
this.state = state;
}
public String getState(){
return state;
}
}创建 Originator 类。
public class Originator {
private String state;
public void setState(String state){
this.state = state;
}
public String getState(){
return state;
}
public Memento saveStateToMemento(){
return new Memento(state);
}
public void getStateFromMemento(Memento Memento){
state = Memento.getState();
}
}创建 CareTaker 类。
import java.util.ArrayList;
import java.util.List;
public class CareTaker {
private List<Memento> mementoList = new ArrayList<Memento>();
public void add(Memento state){
mementoList.add(state);
}
public Memento get(int index){
return mementoList.get(index);
}
}使用 CareTaker 和 Originator 对象。
public class MementoPatternDemo {
public static void main(String[] args) {
Originator originator = new Originator();
CareTaker careTaker = new CareTaker();
originator.setState("State #1");
originator.setState("State #2");
careTaker.add(originator.saveStateToMemento());
originator.setState("State #3");
careTaker.add(originator.saveStateToMemento());
originator.setState("State #4");
System.out.println("Current State: " + originator.getState());
originator.getStateFromMemento(careTaker.get(0));
System.out.println("First saved State: " + originator.getState());
originator.getStateFromMemento(careTaker.get(1));
System.out.println("Second saved State: " + originator.getState());
}
}验证输出:
Current State: State #4
First saved State: State #2
Second saved State: State #3代理模式
本文参考了曾探的《JavaScript设计模式与开发实践》一书。
其实代理模式很常见:
- 比如我之前写项目时,一般不喜欢同事直接使用第三方的 api,或者直接使用未确定具体实现的 api,喜欢再嵌一层。举个例子,封装一个 storage 对象来代替 localStorage,这样以后要把 localStorage 替换成别的存储引擎也无需大动干戈。再举个例子,比如接口请求,我不会直接用 axios,而是会再封装一层,这样以后不想用 axios 想用别的比如 jQuery 的话,要替换起来会很方便。
- 不只是方便替换,有时候我们想增加更多的细节功能,如果之前多了一层代理,这样都会方便很多。比如对第三方的日志打印功能不满意,可以自己代理一下,然后在里面加上打印正文前加上时间戳前缀等逻辑。或者对 query 方法增加缓存和打日志功能,对 execute 方法增加打日志功能。
注意:代理和本地的接口需要保持一致。
虚拟代理模式示例:
var myImage = (function(){
var imgNode = document.createElement( 'img' );
document.body.appendChild( imgNode );
return function( src ){
imgNode.src = src;
}
})();
var proxyImage = (function(){
var img = new Image;
img.onload = function(){
myImage( this.src );
}
return function( src ){
myImage( 'file:// /C:/Users/svenzeng/Desktop/loading.gif' );
img.src = src;
}
})();
proxyImage( 'http://imgcache.qq.com/music// N/k/000GGDys0yA0Nk.jpg' );虚拟代理合并 HTTP 请求:
var synchronousFile = function( id ){
console.log( ’开始同步文件,id为: ' + id );
};
var proxySynchronousFile = (function(){
var cache = [], // 保存一段时间内需要同步的ID
timer; // 定时器
return function( id ){
cache.push( id );
if ( timer ){ // 保证不会覆盖已经启动的定时器
return;
}
timer = setTimeout(function(){
synchronousFile( cache.join( ', ' ) ); // 2秒后向本体发送需要同步的ID集合
clearTimeout( timer ); // 清空定时器
timer = null;
cache.length = 0; // 清空ID集合
}, 2000 );
}
})();
var checkbox = document.getElementsByTagName( 'input' );
for ( var i = 0, c; c = checkbox[ i++ ]; ){
c.onclick = function(){
if ( this.checked === true ){
proxySynchronousFile( this.id );
}
}
};命令模式
本文参考了曾探的《JavaScript设计模式与开发实战》。
有时候需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是什么,此时希望用一种松耦合的方式来设计软件,使得请求发送者和请求接收者能够消除彼此之间的耦合关系。
享元模式
本文参考了曾探的《JavaScript设计模式与开发实战》。
享元(flyweight)模式是一种用于性能优化的模式,“fly”在这里是苍蝇的意思,意为蝇量级。享元模式的核心是运用共享技术来有效支持大量细粒度的对象。
如果系统中因为创建了大量类似的对象而导致内存占用过高,享元模式就非常有用了。在JavaScript中,浏览器特别是移动端的浏览器分配的内存并不算多,如何节省内存就成了一件非常有意义的事情。
对象池
一个典型的例子就是对象池。对象池维护一个装载空闲对象的池子,如果需要对象的时候,不是直接new,而是转从对象池里获取。如果对象池里没有空闲对象,则创建一个新的对象,当获取出的对象完成它的职责之后,再进入池子等待被下次获取。
示例代码如下:
var toolTipFactory = (function(){
var toolTipPool = []; // toolTip对象池
return {
create: function() {
// 如果对象池为空
if ( toolTipPool.length === 0 ) {
// 创建一个dom
var div = document.createElement( 'div' );
document.body.appendChild( div );
return div;
} else {
// 如果对象池里不为空
// 则从对象池中取出一个dom
return toolTipPool.shift();
}
},
recover: function( tooltipDom ){
// 对象池回收dom
return toolTipPool.push( tooltipDom );
}
}
})();职责链模式
本文参考了曾探的《JavaScript设计模式与开发实战》。
职责链模式的定义是:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系,将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
职责链模式的名字非常形象,一系列可能会处理请求的对象被连接成一条链,请求在这些对象之间依次传递,直到遇到一个可以处理它的对象,我们把这些对象称为链中的节点。
一般情况下我们会利用一个 Chain 类来把普通函数包装成职责链的节点。但是利用 JavaScript 的函数式特性,有一种更加方便的方法来创建职责链:
Function.prototype.after = function( fn ){
var self = this;
return function(){
var ret = self.apply( this, arguments );
if ( ret === 'nextSuccessor' ){
return fn.apply( this, arguments );
}
return ret;
}
};
var order = order500yuan.after( order200yuan ).after( orderNormal );
order( 1, true, 500 ); // 输出:500元定金预购,得到100优惠券
order( 2, true, 500 ); // 输出:200元定金预购,得到50优惠券
order( 1, false, 500 ); // 输出:普通购买,无优惠券用 AOP 来实现职责链既简单又巧妙,但这种把函数叠在一起的方式,同时也叠加了函数的作用域,如果链条太长的话,也会对性能有较大的影响。
AOP
AOP 是 Aspect Oriented Programming 的缩写,即“面向切面编程”。编程中,对象之间、方法之间、模块之间,都是一个个的切面。
中介者模式
本文参考了曾探的《JavaScript设计模式与开发实战》。
面向对象设计鼓励将行为分布到各个对象中,把对象划分成更小的粒度,有助于增强对象的可复用性,但由于这些细粒度对象之间的联系激增,又有可能会反过来降低它们的可复用性。
中介者模式的作用就是解除对象与对象之间的紧耦合关系。增加一个中介者对象后,所有的相关对象都通过中介者对象来通信,而不是互相引用,所以当一个对象发生改变时,只需要通知中介者对象即可。中介者使各对象之间耦合松散,而且可以独立地改变它们之间的交互。中介者模式使网状的多对多关系变成了相对简单的一对多关系。
有个购买商品(比如内存条)时选规则然后校验库存的场景:现在我们来引入中介者对象,所有的节点对象只跟中介者通信。当下拉选择框colorSelect、memorySelect和文本输入框numberInput发生了事件行为时,它们仅仅通知中介者它们被改变了,同时把自身当作参数传入中介者,以便中介者辨别是谁发生了改变。剩下的所有事情都交给中介者对象来完成,这样一来,无论是修改还是新增节点,都只需要改动中介者对象里的代码。
var goods = { // 手机库存
"red|32G": 3,
"red|16G": 0,
"blue|32G": 1,
"blue|16G": 6
};
var mediator = (function(){
var colorSelect = document.getElementById( 'colorSelect' ),
memorySelect = document.getElementById( 'memorySelect' ),
numberInput = document.getElementById( 'numberInput' ),
colorInfo = document.getElementById( 'colorInfo' ),
memoryInfo = document.getElementById( 'memoryInfo' ),
numberInfo = document.getElementById( 'numberInfo' ),
nextBtn = document.getElementById( 'nextBtn' );
return {
changed: function( obj ){
var color = colorSelect.value, // 颜色
memory = memorySelect.value, // 内存
number = numberInput.value, // 数量
stock = goods[ color + '|' + memory ]; // 颜色和内存对应的手机库存数量
if ( obj === colorSelect ){ // 如果改变的是选择颜色下拉框
colorInfo.innerHTML = color;
}else if ( obj === memorySelect ){
memoryInfo.innerHTML = memory;
}else if ( obj === numberInput ){
numberInfo.innerHTML = number;
}
if ( ! color ){
nextBtn.disabled = true;
nextBtn.innerHTML = ’请选择手机颜色’;
return;
}
if ( ! memory ){
nextBtn.disabled = true;
nextBtn.innerHTML = ’请选择内存大小’;
return;
}
if ( Number.isInteger ( number -0 ) && number > 0 ){ // 输入购买数量是否为正整数
nextBtn.disabled = true;
nextBtn.innerHTML = ’请输入正确的购买数量’;
return;
}
nextBtn.disabled = false;
nextBtn.innerHTML = ’放入购物车’;
}
}
})();
// 事件函数:
colorSelect.onchange = function(){
mediator.changed( this );
};
memorySelect.onchange = function(){
mediator.changed( this );
};
numberInput.oninput = function(){
mediator.changed( this );
};可以想象,某天我们又要新增一些跟需求相关的节点,比如CPU型号,那我们只需要稍稍改动 mediator 对象即可:
var goods = { // 手机库存
"red|32G|800": 3, // 颜色red,内存32G, cpu800,对应库存数量为3
"red|16G|801": 0,
"blue|32G|800": 1,
"blue|16G|801": 6
};
var mediator = (function(){
// 略
var cpuSelect = document.getElementById( 'cpuSelect' );
return {
change: function(obj){
// 略
var cpu = cpuSelect.value,
stock = goods[ color + '|' + memory + '|' + cpu ];
if ( obj === cpuSelect ){
cpuInfo.innerHTML = cpu;
}
// 略
}
}
})();装饰者模式
本文参考了曾探的《JavaScript设计模式与开发实战》。
装饰者模式可以动态地给某个对象添加一些额外的职责,而不会影响从这个类中派生的其他对象。
JavaScript语言动态改变对象相当容易,我们可以直接改写对象或者对象的某个方法,并不需要使用“类”来实现装饰者模式。
在JavaScript中,几乎一切都是对象,其中函数又被称为一等对象。在平时的开发工作中,也许大部分时间都在和函数打交道。在JavaScript中可以很方便地给某个对象扩展属性和方法,但却很难在不改动某个函数源代码的情况下,给该函数添加一些额外的功能。在代码的运行期间,我们很难切入某个函数的执行环境。
这里我们可以用 AOP 的方式来装饰函数:
Function.prototype.before = function( beforefn ){
// 保存原函数的引用
var __self = this;
// 返回包含了原函数和新函数的"代理"函数
return function(){
/**
* 执行新函数,且保证this不被劫持,新函数接受的参数
* 也会被原封不动地传入原函数,新函数在原函数之前执行
*/
beforefn.apply( this, arguments );
/**
* 执行原函数并返回原函数的执行结果,
* 并且保证this不被劫持
*/
return __self.apply( this, arguments );
}
}
Function.prototype.after = function( afterfn ){
var __self = this;
return function(){
var ret = __self.apply( this, arguments );
afterfn.apply( this, arguments );
return ret;
}
};使用示例:
window.onload = function(){
console.log(1);
}
// 该回调被触发时,会依次输出数字:0、1、2、3、4。
window.onload = ( window.onload || function(){} )
.before(function () {
console.log(0)
})
.after(function(){
console.log(2);
})
.after(function(){
console.log(3);
})
.after(function(){
console.log(4);
});案例:数据统计上报
分离业务代码和数据统计代码,无论在什么语言中,都是 AOP 的经典应用之一。
<html>
<button tag="login" id="button">点击打开登录浮层</button>
<script>
Function.prototype.after = function( afterfn ){
var __self = this;
return function(){
var ret = __self.apply( this, arguments );
afterfn.apply( this, arguments );
return ret;
}
};
var showLogin = function(){
console.log('打开登录浮层');
}
var log = function(){
console.log('上报标签为: ' + this.getAttribute( 'tag' ) );
}
// 打开登录浮层之后上报数据
showLogin = showLogin.after( log );
document.getElementById( 'button' ).onclick = showLogin;
</script>
</html>案例:用 AOP 动态改变函数的参数
var getToken = function(){
return 'Token';
}
ajax = ajax.before(function( type, url, param ){
param.Token = getToken();
});
ajax( 'get', 'http://xxx.com/userinfo', { name: 'sven' } );案例:插件式的表单校验
Function.prototype.before = function( beforefn ){
var __self = this;
return function(){
if ( beforefn.apply( this, arguments ) === false ){
// beforefn返回false的情况直接return,不再执行后面的原函数
return;
}
return __self.apply( this, arguments );
}
}
var validata = function(){
if ( username.value === '' ){
alert ( ’用户名不能为空’ );
return false;
}
if ( password.value === '' ){
alert ( ’密码不能为空’ );
return false;
}
}
var formSubmit = function(){
var param = {
username: username.value,
password: password.value
}
ajax( 'http://xxx.com/login', param );
}
formSubmit = formSubmit.before( validata );
submitBtn.onclick = function(){
formSubmit();
}值得注意的是,因为函数通过Function.prototype.before或者Function.prototype.after被装饰之后,返回的实际上是一个新的函数,如果在原函数上保存了一些属性,那么这些属性会丢失。
另外,这种装饰方式也叠加了函数的作用域,如果装饰的链条过长,性能上也会受到一些影响。
装饰者模式和代理模式
代理模式和装饰者模式最重要的区别在于它们的意图和设计目的。代理模式的目的是,当直接访问本体不方便或者不符合需要时,为这个本体提供一个替代者。本体定义了关键功能,而代理提供或拒绝对它的访问,或者在访问本体之前做一些额外的事情。装饰者模式的作用就是为对象动态加入行为。换句话说,代理模式强调一种关系(Proxy与它的实体之间的关系),这种关系可以静态的表达,也就是说,这种关系在一开始就可以被确定。而装饰者模式用于一开始不能确定对象的全部功能时。代理模式通常只有一层代理-本体的引用,而装饰者模式经常会形成一条长长的装饰链。
适配器模式
本文参考了曾探的《JavaScript设计模式与开发实战》。
适配器模式是一对相对简单的模式。有一些模式跟适配器模式的结构非常相似,比如装饰者模式、代理模式和外观模式。这几种模式都属于“包装模式”,都是由一个对象来包装另一个对象。区别它们的关键仍然是模式的意图。
- 适配器模式主要用来解决两个已有接口之间不匹配的问题,它不考虑这些接口是怎样实现的,也不考虑它们将来可能会如何演化。适配器模式不需要改变已有的接口,就能够使它们协同作用。
- 装饰者模式和代理模式也不会改变原有对象的接口,但装饰者模式的作用是为了给对象增加功能。装饰者模式常常形成一条长的装饰链,而适配器模式通常只包装一次。代理模式是为了控制对对象的访问,通常也只包装一次。
- 外观模式的作用倒是和适配器比较相似,有人把外观模式看成一组对象的适配器,但外观模式最显著的特点是定义了一个新的接口。
重构
本文参考了曾探的《JavaScript设计模式与开发实战》。
提炼函数
如果一个函数过长,不得不加上若干注释才能让这个函数显得易读一些,那这些函数就很有必要进行重构。
如果在函数中有一段代码可以被独立出来,那我们最好把这些代码放进另外一个独立的函数中。这是一种很常见的优化工作,这样做的好处主要有以下几点。
- 避免出现超大函数。
- 独立出来的函数有助于代码复用。
- 独立出来的函数更容易被覆写。
- 独立出来的函数如果拥有一个良好的命名,它本身就起到了注释的作用。
合并重复的条件片段
比如把这段代码:
var paging = function( currPage ){
if ( currPage <= 0 ){
currPage = 0;
jump( currPage ); // 跳转
}else if ( currPage >= totalPage ){
currPage = totalPage;
jump( currPage ); // 跳转
}else{
jump( currPage ); // 跳转
}
};修改成:
var paging = function( currPage ){
if ( currPage <= 0 ){
currPage = 0;
}else if ( currPage >= totalPage ){
currPage = totalPage;
}
jump( currPage ); // 把jump函数独立出来
};把条件分支语句提炼成函数
比如把下面这段代码:
var getPrice = function( price ){
var date = new Date();
if ( date.getMonth() >= 6 && date.getMonth() <= 9 ){ // 夏天
return price * 0.8;
}
return price;
};
观察这句代码:
if ( date.getMonth() >= 6 && date.getMonth() <= 9 ){
// ...
}修改成:
var isSummer = function(){
var date = new Date();
return date.getMonth() >= 6 && date.getMonth() <= 9;
};
var getPrice = function( price ){
if ( isSummer() ){ // 夏天
return price * 0.8;
}
return price;
};合理使用循环
比如将下面这段代码:
var createXHR = function(){
var xhr;
try{
xhr = new ActiveXObject( 'MSXML2.XMLHttp.6.0' );
}catch(e){
try{
xhr = new ActiveXObject( 'MSXML2.XMLHttp.3.0' );
}catch(e){
xhr = new ActiveXObject( 'MSXML2.XMLHttp' );
}
}
return xhr;
};
var xhr = createXHR();修改成:
var createXHR = function(){
var versions= [
'MSXML2.XMLHttp.6.0ddd',
'MSXML2.XMLHttp.3.0',
'MSXML2.XMLHttp'
];
for ( var i = 0, version; version = versions[ i++ ]; ){
try{
return new ActiveXObject( version );
}catch(e){
}
}
};
var xhr = createXHR();提前让函数退出代替嵌套条件分支
比如将下面这段代码:
var del = function( obj ){
var ret;
if ( ! obj.isReadOnly ){ // 不为只读的才能被删除
if ( obj.isFolder ){ // 如果是文件夹
ret = deleteFolder( obj );
}else if ( obj.isFile ){ // 如果是文件
ret = deleteFile( obj );
}
}
return ret;
};修改为:
var del = function( obj ){
if ( obj.isReadOnly ){ // 反转if表达式
return;
}
if ( obj.isFolder ){
return deleteFolder( obj );
}
if ( obj.isFile ){
return deleteFile( obj );
}
};传递对象参数代替过长的参数列表
比如将下面的代码:
var setUserInfo = function( id, name, address, sex, mobile, qq ){
console.log( 'id= ' + id );
console.log( 'name= ' +name );
console.log( 'address= ' + address );
console.log( 'sex= ' + sex );
console.log( 'mobile= ' + mobile );
console.log( 'qq= ' + qq );
};
setUserInfo( 1314, 'sven', 'shenzhen', 'male', '137********', 377876679 );修改为:
var setUserInfo = function( obj ){
console.log( 'id= ' + obj.id );
console.log( 'name= ' + obj.name );
console.log( 'address= ' + obj.address );
console.log( 'sex= ' + obj.sex );
console.log( 'mobile= ' + obj.mobile );
console.log( 'qq= ' + obj.qq );
};
setUserInfo({
id: 1314,
name: 'sven',
address: 'shenzhen',
sex: 'male',
mobile: '137********',
qq: 377876679
});尽量减少参数数量
比如将下面这段代码:
var draw = function( width, height, square ){};修改为:
// square 完全可以在函数内部自行计算出来,不需要从外部传入
var draw = function( width, height ){
var square = width * height;
};少用三目运算符
如果条件分支逻辑简单且清晰,这无碍我们使用三目运算符:
var global = typeof window ! == "undefined" ? window : this;但是像下面这样就不合适了:
if ( ! aup || ! bup ) {
return a === doc ? -1 :
b === doc ? 1 :
aup ? -1 :
bup ? 1 :
sortInput ?
( indexOf.call( sortInput, a ) - indexOf.call( sortInput, b ) ) :
0;
}合理使用链式调用
在JavaScript中,可以很容易地实现方法的链式调用,即让方法调用结束后返回对象自身,如下代码所示:
var User = function(){
this.id = null;
this.name = null;
};
User.prototype.setId = function( id ){
this.id = id;
return this;
};
User.prototype.setName = function( name ){
this.name = name;
return this;
};
console.log( new User().setId( 1314 ).setName( 'sven' ) );或者这样写也可以:
var User = {
id: null,
name: null,
setId: function( id ){
this.id = id;
return this;
},
setName: function( name ){
this.name = name;
return this;
}
};
console.log( User.setId( 1314 ).setName( 'sven' ) );使用链式调用的方式并不会造成太多阅读上的困难,也确实能省下一些字符和中间变量,但节省下来的字符数量同样是微不足道的。链式调用带来的坏处就是在调试的时候非常不方便,如果我们知道一条链中有错误出现,必须得先把这条链拆开才能加上一些调试log或者增加断点,这样才能定位错误出现的地方。
如果该链条的结构相对稳定,后期不易发生修改,那么使用链式调用无可厚非。但如果该链条很容易发生变化,导致调试和维护困难,那么还是建议使用普通调用的形式:
var user = new User();
user.setId( 1314 );
user.setName( 'sven' );分解大型类
示例代码:
var Spirit = function( name ){
this.name = name;
this.attackObj = new Attack( this );
};
Spirit.prototype.attack = function( type ){ // 攻击
this.attackObj.start( type );
};
var spirit = new Spirit( 'RYU' );
spirit.attack( 'waveBoxing' ); // 输出:RYU:使用波动拳
spirit.attack( 'whirlKick' ); // 输出:RYU:使用旋风腿用return退出多重循环
Webpack
Webpack配置示例
const webpackConfig = {
entry: {
bundle: resolve('src/index.lint.jsx'),
componentsInFolders: glob.sync(resolve('src/components/*/*.js?(x)')),
componentsInRoot: glob.sync(resolve('src/components/*.js?(x)')),
api: glob.sync(resolve('src/api/*.js?(x)')),
utils: glob.sync(resolve('src/utils/*.js?(x)')),
},
output: {
path: resolve('dist'),
filename: '[name].js',
publicPath: '',
},
externals: {
'zepto': 'window.$',
'highcharts': 'window.Highcharts',
'jsencrypt': 'window.JSEncrypt',
},
resolve: {
extensions: [
'.lint.jsx',
'.jsx',
'.js',
'.css',
'.ejs',
'.scss',
'.json',
'.sass',
],
alias: {
'@': resolve('src'),
'@img': resolve('src/assets/img'),
'@utils': resolve('src/utils'),
'@css': resolve('src/assets/css'),
'@component': resolve('src/components'),
},
},
resolveLoader: {
modules: [
'node_modules',
],
},
// Some libraries import Node modules but don't use them in the browser.
// Tell Webpack to provide empty mocks for them so importing them works.
node: {
dgram: 'empty',
fs: 'empty',
net: 'empty',
tls: 'empty',
child_process: 'empty',
},
module: {
rules: [
{
test: /\.jsx?$/,
use: [
'happypack/loader?id=babel',
conditionalCompiler,
],
include: [resolve('src')],
},
{
test: /\.(png|jpg|gif|svg|mp3)$/,
loader: 'file-loader',
exclude: /node_modules/,
query: {
name: 'assets/img/[name].[ext]',
// name: 'assets/img/[path][module-img][name].[ext]',
},
},
{
test: /\.less$/,
use: [
{ loader: 'style-loader' },
{ loader: 'css-loader' },
{ loader: 'postcss-loader' },
{
loader: 'less-loader',
options: {
modifyVars: require('../package').theme,
javascriptEnabled: true,
},
},
],
},
],
},
plugins: [
new webpack.DllReferencePlugin({
context: __dirname,
manifest: dllManifestForVendorCxg,
}),
new webpack.DllReferencePlugin({
context: __dirname,
manifest: dllManifestForVendorCxgOthers,
}),
new webpack.LoaderOptionsPlugin({
options: {
customInterpolateName (url) {
if (/\[module-img\]/.test(url)) {
url = url.replace(/img[\\/]/g, '')
url = url.replace(/\[module-img\]/, '')
const folderName = url.replace(
/^.*[\\/]([\w-]+)[\\/][\w-]+\.[\w]+/,
'$1'
)
const fileName = url.replace(
/^.+[\\/]([\w-]+\.[\w]+$)/,
'$1'
)
url = `assets/img/${folderName}/${fileName}`
return url
}
return url
},
},
}),
new HappyPack({
id: 'babel',
threads: os.cpus().length,
verbose: false,
loaders: [
{
loader: 'babel-loader',
options: {
cacheDirectory: 'node_modules/.cache/babel-loader',
},
},
],
}),
new CopyWebpackPlugin([
{
from: resolve('src/hbenv.js'),
to: './assets/js/hbenv.js',
},
{
from: resolve('example'),
to: './example',
},
{
from: resolve('favicon.ico'),
to: './',
},
]),
],
}
module.exports = webpackConfig怎么配置输出多个chunk
通过配置不同的 entry 来生成不同的 chunk。
hash、chunkhash、contenthash
hash
hash是跟整个项目的构建相关,只要项目里有文件更改, 整个项目构建的hash值都会更改,并且全部文件都共用相同的hash值
chunkhash
采用hash计算的话,每一次构建后生成的哈希值都不一样, 即使文件内容压根没有改变。这样子是没办法实现缓存效果, 我们需要换另一种哈希值计算方式,即chunkhash。
chunkhash和hash不一样, 它根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk, 生成对应的哈希值。 我们在生产环境里把一些公共库和程序入口文件区分开,单独打包构建, 接着我们采用chunkhash的方式生成哈希值, 那么只要我们不改动公共库的代码,就可以保证其哈希值不会受影响。
contenthash
只要内容不变,hash值就不变。
如何写一个loader
const loaderUtils = require('loader-utils');
module.exports = function (source /* 逐个处理的文件内容 */) {
const self = this
const options = loaderUtils.getOptions(self)
const resourcePath = self.resourcePath
// 根据上面的一些信息处理resource
return resource
}如何写一个plugin
module.exports = class FixedChunkIdPlugin {
constructor (options) {
this.options = options || {}
}
apply (compiler) {
compiler.plugin('compilation', (compilation) =>
compilation.plugin('before-chunk-ids', (chunks) => {
chunks.forEach((chunk) => {
if (!chunk.id) {
/**
* 要求定义路由的chunk名时不要重名
* 我们现有的逻辑,如果页面chunk名重复的话会生成同一个页面js,
* 本来就是不允许重名的
*/
chunk.id = chunk.name
}
})
})
)
}
}Performance 性能数据统计
简书性能背景
发现简书控制台会输出性能相关的一些统计数据,类似下面这样:
{
"link": "https://www.jianshu.com/",
"times": {
"alltime": 31772,
"details": {
"redirect": 0,
"dns": 0,
"ttfb": 751,
"static": 741,
"render": 31018,
"onload": 1624684987502
},
"lifecycle": {
"_1": {
"key": "redirect",
"desc": "网页重定向的耗时",
"value": 0
},
"_2": {
"key": "cache",
"desc": "检查本地缓存的耗时",
"value": 0
},
"_3": {
"key": "dns",
"desc": "DNS查询的耗时",
"value": 0
},
"_4": {
"key": "tcp",
"desc": "TCP连接的耗时",
"value": 0
},
"_5": {
"key": "request",
"desc": "客户端发起请求的耗时",
"value": 738
},
"_6": {
"key": "response",
"desc": "服务端响应的耗时",
"value": 3
},
"_7": {
"key": "render",
"desc": "渲染页面的耗时",
"value": 31018
},
"__": 31759
}
},
"ua": "Mozilla/5.0 (Macintosh; ... 4 Safari/537.36"
}去把他们编译产物拿出来格式化处理后,我们来一个个看这些值都是怎么取到的。
link和ua
link的取值为window.location.href.split("?")[0]。
ua的取值为:navigator.userAgent。
times
编译产物代码里性能数据的核心代码如下:
window.addEventListener("load", function() {
setTimeout(function() {
var e = window.performance;
if (e) {
var t = e.timing,
n = {
_1: {
key: "redirect",
desc: "网页重定向的耗时",
value: t.redirectEnd - t.redirectStart
},
_2: {
key: "cache",
desc: "检查本地缓存的耗时",
value: t.domainLookupStart - t.fetchStart
},
_3: {
key: "dns",
desc: "DNS查询的耗时",
value: t.domainLookupEnd - t.domainLookupStart
},
_4: {
key: "tcp",
desc: "TCP连接的耗时",
value: t.connectEnd - t.connectStart
},
_5: {
key: "request",
desc: "客户端发起请求的耗时",
value: t.responseStart - t.requestStart
},
_6: {
key: "response",
desc: "服务端响应的耗时",
value: t.responseEnd - t.responseStart
},
_7: {
key: "render",
desc: "渲染页面的耗时",
value: t.domComplete - t.responseEnd
}
},
o = 0;
(0, a.default)(n).forEach(function(e) {
n[e] && n[e].value > 0 && (o += n[e].value)
}), n.__ = o;
var r = {
redirect: t.redirectEnd - t.redirectStart,
dns: t.domainLookupEnd - t.domainLookupStart,
ttfb: t.responseStart - t.navigationStart,
static: t.responseEnd - t.requestStart,
render: t.domComplete - t.responseEnd,
onload: t.responseEnd - t.redirectStart
},
i = {
alltime: t.domComplete - t.navigationStart,
details: r,
lifecycle: n
},
l = Date.now() % 5 == 0;
if ((0, a.default)(r).forEach(function(e) {
(r[e] > 15e3 || r[e] < 0) && (l = !1)
}), l) {
var u = "/" === window.location.pathname
? "/index"
: window.location.pathname;
try {
d.default.post(
"https://tr.jianshu.com/fe/1/mon/atf",
(0, s.default)({}, {
url: window.location.href.split("?")[0],
ua: navigator.userAgent,
path: u,
total: t.domComplete - t.navigationStart,
app: "maleskine",
tags: [
"undefined" != typeof ParadigmSDKv3
? "with-Paradigm"
: "without-Paradigm"
]
}, r)
).then(function() {}).catch(function() {})
} catch (e) {}
}
console && console.log({
link: window.location.href.split("?")[0],
times: i,
ua: navigator.userAgent
})
}
}, 0)
})可以看出,主要是利用了performance这个性能api,当有该API时,才会记录相关的数据。
const timing = performance.timing
// 网页重定向的耗时
const redirect = timing.redirectEnd - timing.redirectStart
// 检查本地缓存的耗时
const cache = timing.domainLookupStart - timing.fetchStart
// DNS查询的耗时
const dns = timing.domainLookupEnd - timing.domainLookupStart
// TCP连接的耗时
const tcp = timing.connectEnd - timing.connectStart
// 客服端发起请求的耗时
const request = timing.responseStart - timing.requestStart
// 服务端响应的耗时
const response = timing.responseEnd - timing.responseStart
// 渲染页面的耗时
const render = timing.domComplete - timing.responseEnd
//
const ttfb = timing.responseStart - timing.navigationStart
// 发起请求到响应结束的耗时
const statics = timing.responseEnd - timing.requestStart
//
const onload = timing.responseEnd - timing.redirectStart
//
const alltime = timing.domComplete - timing.navigationStartperformance.timing弃用
这个API其实已经被弃用,你可以通过在控制台执行performance.getEntries()来查看相关的一些性能数据。
这里面的API和属性太多就不介绍了。
Resource loading phases
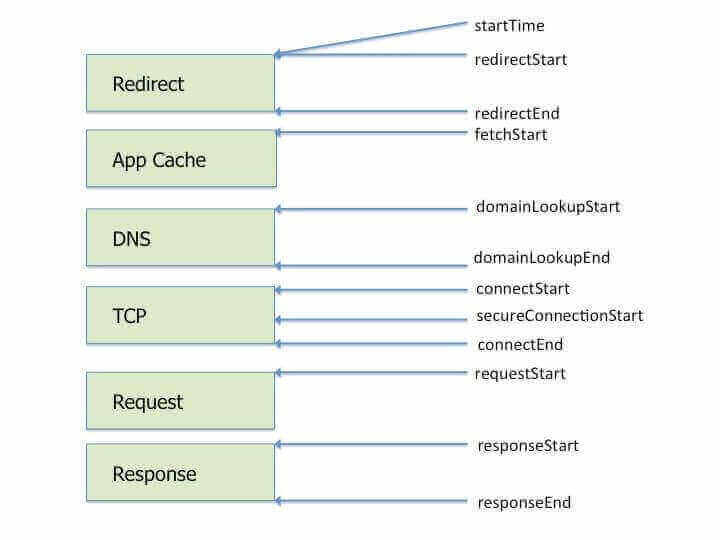
页面加载、响应、渲染耗时
我们不看简书上的逻辑,根据MDN上的例子,可知:
页面加载时间
const perfData = window.performance.timing;
const pageLoadTime = perfData.loadEventEnd - perfData.navigationStart;请求响应时间
const connectTime = perfData.responseEnd - perfData.requestStart;页面渲染时间
const renderTime = perfData.domComplete - perfData.domLoading;Babel和AST(抽象语法树)
Babel基本知识
Babel的处理步骤
Babel的3个主要处理步骤:
- parse(解析):解析步骤接收代码并输出AST。分词法分析(Lexical Analysis)和语法分析(Syntactic Analysis)两个阶段。 词法分析阶段把字符串形式的代码转换为令牌流(tokens,可视为扁平的语法片段数组)。 语法分析阶段会使用token中的信息把它们转换成AST的表示结构,便于后续操作。
- transform(转换):转换步骤接收AST并对其进行遍历。在此过程中对节点进行添加、更新及移除等操作。在转换步骤中,需要进行树的递归遍历(深度遍历)。
- generate(生成):代码生成步骤把经过一系列转换之后的最终AST转换成最终形式的代码,同时还会创建Source Maps用于映射源码。 代码生成其实很简单:深度优先遍历整个AST树,然后构件可以表示转换后代码的字符串。
提示
可以通过https://astexplorer.net/在线工具将待转换的代码转换成AST抽象语法树。
以下代码:
let tips = [
"Click on any AST node with a '+' to expand it",
"Hovering over a node highlights something",
"Shift click on an AST node to expand the whole subtree"
];
function printTips() {
tips.forEach((tip, i) => console.log(`Tip ${i}:` + tip));
}转换成AST后长这样:
{
"type": "Program",
"start": 0,
"end": 481,
"body": [
{
"type": "VariableDeclaration",
"start": 179,
"end": 394,
"declarations": [
{
"type": "VariableDeclarator",
"start": 183,
"end": 393,
"id": {
"type": "Identifier",
"start": 183,
"end": 187,
"name": "tips"
},
"init": {
"type": "ArrayExpression",
"start": 190,
"end": 393,
"elements": [
{
"type": "Literal",
"start": 194,
"end": 241,
"value": "Click on any AST node with a '+' to expand it",
"raw": "\"Click on any AST node with a '+' to expand it\""
},
{
"type": "Literal",
"start": 246,
"end": 330,
"value": "Hovering over a node highlights something",
"raw": "\"Hovering over a node highlights something\""
},
{
"type": "Literal",
"start": 335,
"end": 391,
"value": "Shift click on an AST node to expand the whole subtree",
"raw": "\"Shift click on an AST node to expand the whole subtree\""
}
]
}
}
],
"kind": "let"
},
{
"type": "FunctionDeclaration",
"start": 396,
"end": 480,
"id": {
"type": "Identifier",
"start": 405,
"end": 414,
"name": "printTips"
},
"expression": false,
"generator": false,
"async": false,
"params": [],
"body": {
"type": "BlockStatement",
"start": 417,
"end": 480,
"body": [
{
"type": "ExpressionStatement",
"start": 421,
"end": 478,
"expression": {
"type": "CallExpression",
"start": 421,
"end": 477,
"callee": {
"type": "MemberExpression",
"start": 421,
"end": 433,
"object": {
"type": "Identifier",
"start": 421,
"end": 425,
"name": "tips"
},
"property": {
"type": "Identifier",
"start": 426,
"end": 433,
"name": "forEach"
},
"computed": false,
"optional": false
},
"arguments": [
{
"type": "ArrowFunctionExpression",
"start": 434,
"end": 476,
"id": null,
"expression": true,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 435,
"end": 438,
"name": "tip"
},
{
"type": "Identifier",
"start": 440,
"end": 441,
"name": "i"
}
],
"body": {
"type": "CallExpression",
"start": 446,
"end": 476,
"callee": {
"type": "MemberExpression",
"start": 446,
"end": 457,
"object": {
"type": "Identifier",
"start": 446,
"end": 453,
"name": "console"
},
"property": {
"type": "Identifier",
"start": 454,
"end": 457,
"name": "log"
},
"computed": false,
"optional": false
},
"arguments": [
{
"type": "BinaryExpression",
"start": 458,
"end": 475,
"left": {
"type": "TemplateLiteral",
"start": 458,
"end": 469,
"expressions": [
{
"type": "Identifier",
"start": 465,
"end": 466,
"name": "i"
}
],
"quasis": [
{
"type": "TemplateElement",
"start": 459,
"end": 463,
"value": {
"raw": "Tip ",
"cooked": "Tip "
},
"tail": false
},
{
"type": "TemplateElement",
"start": 467,
"end": 468,
"value": {
"raw": ":",
"cooked": ":"
},
"tail": true
}
]
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 472,
"end": 475,
"name": "tip"
}
}
],
"optional": false
}
}
],
"optional": false
}
}
]
}
}
],
"sourceType": "module"
}Visitors访问者
进入一个节点,实际上就是在访问这个节点。之所以使用这个术语,是因为有个叫做访问者模式的概念。
访问者是一个用于 AST 遍历的跨语言的模式。简单的说它们就是一个对象,定义了用于在一个树状结构中获取具体节点的方法。 比如:
const Visitor = {
Identifier() {
console.log("Called!");
}
};
// Identifier() { ... } 是 Identifier: { enter() { ... } } 的简写形式。.
// 也可以先创建一个访问者对象,并在稍后给它添加方法。
let visitor = {};
visitor.MemberExpression = function() {};
visitor.FunctionDeclaration = function() {}以上为一个简单的访问者,用于遍历时,每遇到一个Identifier的时候都会调用Identifier()方法。
此种方法默认为在进入节点时进行操作,也可以在退出节点时进行操作:
const Visitor = {
Identifier: {
enter() {
console.log("Entered!");
},
exit() {
console.log("Exited!");
}
}
};如果对不同节点有同样的操作,可以用“|”将方法名分隔开:
const visitor = {
"Idenfifier |MemberExpression"(path){}
}特别的,还可以使用别名(https://github.com/babel/babel/tree/master/packages/babel-types/src/definitions)去定义:
//Function is an alias for FunctionDeclaration, FunctionExpression,
//ArrowFunctionExpression, ObjectMethod and ClassMethod.
const Visitor = {
Function(path) {}
}Paths路径
AST 通常会有许多节点,Path 是表示两个节点之间连接的对象。 在某种意义上,路径是一个节点在树中的位置以及关于该节点各种信息的响应式 Reactive 表示。 当你调用一个修改树的方法后,路径信息也会被更新。 Babel 帮你管理这一切,从而使得节点操作简单,尽可能做到无状态。
Paths in Visitors(存在于访问者中的路径)
当你调用一个访问者的Identifier() 成员方法时,你实际上是在访问路径而非节点。 通过这种方式,你操作的就是节点的响应式表示(即路径)而非节点本身。
// 对表达式:a+b+c
const visitor = {
Identifier(path){
console.log("now: " + path.node.name);
}
}
// 使用path.traverse(visitor)进行转换
path.traverse(visitor);
//以下是输出结果:
now: a
now: b
now: cState状态
状态是抽象语法树AST转换的敌人,状态管理会不断牵扯你的精力。 而且几乎所有你对状态的假设,总是会有一些未考虑到的语法最终证明你的假设是错误的。
const parser = require("@babel/parser"); // 解析,js转AST
const traverse = require("@babel/traverse").default; // 转换
const t = require("@babel/types");
const generator = require("@babel/generator").default; // 生成
const fs = require('fs'); // 文件读写
target_js = "function square(n) { return n * n;}"
// 尝试将该代码中的n都变为x
const visitor = {
FunctionDeclaration(path){
const param = path.node.params[0]
if (param.name === 'n'){
paramName = param.name;
param.name = 'x'
}
},
Identifier(path){
if (path.node.name === paramName){
path.node.name = "x"
}
}
}
let ast = parser.parse(target_js);
traverse(ast, visitor);
let {code} = generator(ast);
// 输出:
function square(x) {
return x * x;
}以上代码可以做到将n变为x,但如果js代码变为:
function square(n){
return n * n;
}
function add(n, m){
return n + m
}输出结果就变成了:
function square(x) {
return x * x;
}
function add(x, m) {
return x + m;
}但我们本意只想变换square方法中的n。于是可以用递归的方式:
const parser = require("@babel/parser"); // 解析,js转AST
const traverse = require("@babel/traverse").default; // 转换
const t = require("@babel/types");
const generator = require("@babel/generator").default; // 生成
const fs = require('fs'); // 文件读写
var target_js = "function square(n){\n" +
" return n * n;\n" +
"}\n" +
"\n" +
"function add(n, m){\n" +
" return n + m\n" +
"}"
// 尝试将该代码中的n都变为x
const updateParamName = {
"Identifier"(path){
if (path.node.name === this.paramName){
path.node.name = "x"
}
}
}
const visitor = {
"FunctionDeclaration"(path){
if (path.node.params.length > 1){
return;
}
const param = path.node.params[0]
if (param.name === 'n'){
paramName = param.name;
param.name = 'x'
path.traverse(updateParamName, { paramName });
}
}
}
let ast = parser.parse(target_js);
traverse(ast, visitor);
let {code} = generator(ast);
console.log(code)
//输出结果
function square(x) {
return x * x;
}
function add(n, m) {
return n + m;
}此处为特殊例子,为了演示如何从访问者中消除全局状态。
Scopes作用域
JavaScript支持词法作用域,在树状嵌套结构中代码块创建出新的作用域。
在JavaScript中,每创建一个引用,不管是通过变量(variable)、函数(function)、类型(class)、 参数(params)、模块导入(import)还是标签(label)等,都属于当前作用域。
更深的内部作用域代码可以使用外层作用域中的引用。
内层作用域也可以创建和外层作用域同名的引用。
当写转换时,必须小心作用域,必须要确保在改变代码的各个部分时不会破坏已经存在的代码。
在添加一个新的引用时需要确保新增加的引用名字和已有的所有引用不冲突。 或者想找出使用一个变量的所有引用,应该在给定的作用域中找出这些引用。
作用域可以表示为:
const scope = {
path: path,
block: path.node,
parentBlock: path.parent,
parent: parentScope,
bindings: [/** ... */]
}创建一个新的作用域,需要给出它的路径和父作用域,之后在遍历过程中它会在该作用域内收集所有的引用("绑定")。
一旦引用收集完毕,就可以在作用域上使用各种方法。
Bindings绑定
所有引用属于特定的作用域,引用和作用域的这种关系被称为:绑定(binding)。
单个绑定可以表示为:
const binding = {
identifier: node,
scope: scope,
path: path,
kind: 'var',
referenced: true,
references: 3,
referencePaths: [path, path, path],
constant: false,
constantViolations: [path]
}有以上信息就可以查找一个绑定的所有引用,并且知道这是什么类型的绑定(参数,定义等), 查找所属的作用域,或者拷贝标识符,甚至知道是不是常量,如果不是,那么哪里修改了它。
在很多情况下,知道一个绑定是否是常量非常有用,最有用的一种情形就是代码压缩。
API
Babel实际上是一组模块的集合。接下来是一些主要的模块,会解释他们是做什么的,以及如何使用。
babylon
Babylon是Babel的解析器。最初是从Acorn项目fork出来的。Acorn非常快,易于使用,并且针对非标准特性(以及未来的标准特性)设计了一个基于插件的架构。
babel-traverse
Babel Traverse模块维护了整棵树的状态,并且负责替换、移除和添加节点。
babel-types
Babel Types模块是一个用于AST节点的Lodash式工具库(JavaScript函数工具库,提供了基于函数式编程风格的众多工具函数), 包含了构造、验证以及变化AST节点的方法。 该工具库包含考虑周到的工具方法,对编写处理AST逻辑非常有用。
Definitions定义
Babel Types模块拥有每一个单一类型节点的定义,包括节点包含那些属性,什么是合法值,如何构建节点、遍历节点,以及节点的别名等信息。
单一节点类型的定义形式如下:
defineType("BinaryExpression", {
builder: ["operator", "left", "right"],
fields: {
operator: {
validate: assertValueType("string")
},
left:{
validate: assertNodeType("Expression")
},
right:{
validate: assertNodeType("Expression")
}
},
visitor: ["left", "right"],
aliases: ["Binary", "Expression"]
});Builders构建器
上边的定义中有builder字段,这个字段的出现是因为每个节点类型都有构造器方法builder,使用方法:
type.binaryExpression("*", type.identifier("a"), type.identifiier("b"));可以创建的AST:
const ast = {
type: "BinaryExpression",
operator: "*",
left: {
type: "Identifier",
name: "a"
},
right: {
type: "Identifier",
name: "b"
}
}转为js代码后:
a * b构造器还会验证自身创建的节点,并在错误使用的情况下抛出描述性错误。于是有了验证器。
Validators验证器
BinaryExpression的定义还包含了节点的字段fields信息,以及如何验证这些字段。
const validator = {
fields: {
operator: {
validate: assertValueType("string")
},
left: {
validate: assertNodeType("Expression")
},
right: {
validate: assertNodeType("Expression")
}
}
}可以创建两种验证方法。第一种是isX。
type.isBinaryExpression(maybeBinaryExpressionNode)这个测试用来确保节点是一个二进制表达式,另外你也可以传入第二个参数来确保节点包含特定的属性和属性值。
type.isBinaryExpression(maybeBinaryExpressionNode, { operator: "*" });还有一些断言式版本,会抛出异常而非true或false。
type.assertBinaryExpressiion(maybeBinaryExpressionNode);
type.assertBiinaryExpression(maybeBinaryExpressionNode, { operator: "*" });
// Error: Expected type "BinaryExpression" with option { "operator": "*" }Converters变换器
babel-generator
是Babel的代码生成器,读取AST并将其转换为代码和源码映射。
const code = '......'
const ast = babylon.parse(code);
generate(ast, {}, code);
// 结果
// {
// code: "...",
// map: "..."
// }
// 也可以传递选项
generate(ast, {
retainLines: false,
compact: "auto",
concise: false,
quotes: "double",
}, code);babel-template
是另一个虽然小但非常有用的模块,能使你编写字符串形式切带有占位符的代码来代替手动编码,尤其生成大规模AST时。 在计算机科学中,这种能力被称为准引用(quasiquotes)。
import template from "babel-template";
import generate from "babel-generator";
import * as type from "babel-types";
const buildRequire = template(' var IMPORT_NAME = require(SOURCE); ');
const ast = buildRequire({
IMPORT_NAME: type.identifier("myModule"),
SOURCE: type.stringLiteral("my-module")
});
console.log(generate(ast).code);
// 结果:
var myModule = require("my-module");转换
访问
获取子节点的Path
为了得到一个AST节点的属性值,我们一般先访问到该节点,然后利用path.node.property方法即可。
// BinaryExpression AST node 的属性: 'left', 'right', 'operator'
BinaryExpression(path) {
path.node.left;
path.node.right;
path.node.operator;
}访问该属性内部的path,使用path对象的get方法,传递属性的字符串形式作为参数:
BinaryExpression(path){
path.get('left');
}
Program(path){
path.get('body.0');
}检查节点的类型
如果想检查节点的类型,最好的方式是:
BinaryExpression(path){
if (t.isIdentifier(path.node.left)){
// ...
}
}或者可以对节点的属性做浅层检查:
BinaryExpression(path){
if (t.isIdentifier(path.node.left, { name: "n" })) {
// ...
}
}功能上等价于:
BinaryExpression(path){
if (path.node.left != null &&
path.node.left.type === "Identiifiier" &&
path.node.left.name === "n"
){
// ...
}
}检查路径(Path)类型
BinaryExpression(path) {
if (path.get('left').isIdentifier({ name: "n" })){
// ...
}
}
// 等价于
BinaryExpression(path) {
if (t.isIdentifier(path.node.left, { name: "n" })) {
// ...
}
}检查标识符(Identifier)是否被引用
Identifier(path) {
if (path.isReferencedIdentifier()) {
// ...
}
}
// 或者
Identifier(path) {
if (t.isReferenced(path.node, path.parent)) {
// ...
}
}找到特定的父路径
有时需要从一个路径向上遍历语法树,直到满足相应的条件。
/**
* 对于每一个父路径调用callback并将其NodePath当作参数,
* 当callback返回真值时,则将其NodePath返回。
*/
path.findParent((path) => path.isObjcetExpression());
// 如果也需要遍历当前节点:
path.find((path) => path.isObjectExpression());
// 查找最接近的父函数或程序:
path.getFunctionParent();
// 向上遍历语法树,直到找到在列表中的父节点路径
path.getStatementParent();获取同级路径
如果一个路径是在一个Function/Program中的列表里面,他就有同级节点。
- 使用path.inList来判断路径是否有同级节点
- 使用path.getSibling(index)来获取同级路径
- 使用path.key获取路径所在容器的索引
- 使用path.container获取路径的容器(包含所有同级节点的数组)
- 使用path.listKey获取容器的key
target_js = `
var a = 1; // pathA, path.key = 0
var b = 2; // pathB, path.key = 1
var c = 3; // pathC, path.key = 2
`
export default function({ types: t }) {
return {
visitor: {
VariableDeclaration(path) {
// if the current path is pathA
path.inList // true
path.listKey // "body"
paht.key // 0
path.getSibling(0) // pathA
path.getSibling(path.key + 1) //pathB
path.container // [pathA, pathB, pathC]
}
}
};
}停止遍历
如果插件需要在某种情况下不运行,最简单的做法是尽早返回:
BinaryExpression(path){
if (path.node.operator !== '**') return;
}如果在顶级路径中进行子遍历,则可以使用2个提供的API方法:
path.skip() 会跳过当前路径之后的子节点遍历;path.stop() 完全停止遍历。
处理
替换一个节点
BinaryExpression(path) {
// 将当前BinaryExpression替换为:binaryExpression节点
// 该节点值为"**", left为path.node.left, right为t.numberLiteral(2),即2。
path.replaceWith(
t.binaryExpression("**", path.node.left, t.numberLiteral(2))
);
}用多个节点替换单个节点
ReturnStatement(path) {
path.replaceWithMultiple([
t.expressionStatement(t.stringLiteral("Is this the real life?")),
t.expressionStatement(t.stringLiteral("Is this just fantasy?")),
t.expressionStatement(
t.stringLiteral(
"(Enjoy singing the rest of the song in you head)"
)
),
]);
}提示
注意,当多个节点替换一个表达式时,他们必须是声明。 因为Babel在更换节点时广泛使用启发式算法,这意味着您可以做一些疯狂的转换,否则将会非常冗长。
用字符串源码替换节点
FunctionDeclaration(path){
path.replaceWithSourceString(function add(a, b) {
return a + b;
});
}
// 结果:
- function square(n) {
- return n * n
- }
+ function add(a, b) {
+ return a + b
+ }注意
不建议使用这个API,除非正在处理动态的源码字符串,否则在访问者外部解析代码更有效率
插入兄弟节点
FunctionDeclaration(path) {
path.insertBefore(
t.expressionStatement(
t.stringLiteral("Because I'm easy come, easy go.")
)
);
path.insertAfter(
t.expressionStatement(
t.stringLiteral("A little high, little low.")
)
);
}
// 结果
+ "Because I'm easy come, easy go.";
function square(n) {
return n * n;
}
+ "A little high, little low.";提示
这里同样应该使用声明或者一个声明数组。这个使用了在用多个节点替换一个节点中提到的相同的启发式算法。
插入到容器(container)中
如果要在AST节点属性中插入一个类似body那样的数组,其方法与insertBefore/insertAfter类似,但必须指定listKey。
ClassMethod(path) {
path.get('body').unshiftContainer(
'body',
t.expressionStatement(t.stringLiteral('before'))
);
path.get('body').pushContainer(
'body',
t.expressionStatement(t.stringLiteral('after'))
);
}
// 结果
class A{
+ "before"
var a = 'middle';
+ "after"
}删除一个节点
FunctionDeclaration(path) {
path.remove();
}
//结果
- function square(n) {
- return n * n;
- }替换父节点
只需要用parentPath: path.parentPath.replaceWith即可:
BinaryExpression(path) {
path.parentPath.replaceWith(
t.expressionStatement(
t.stringLiteral(
"Anyway the wind blows, doesn't really matter to me, to me."
)
)
);
}
// 结果
function square(n) {
- return n * n
+ "Anyway the wind blows, doesn't really matter to me, to me.";
}删除父节点
BinaryExpression(path) {
path.parentPath.remove();
}
// 结果
function square(n) {
- return n * n
}基于scope作用域的操作
检查本地变量是否被绑定
FunctionDeclaration(path) {
if (path.scope.hasBinding("n")) {
// ...
}
}
// 以上操作将遍历范围树,并检查特定的绑定
FunctionDeclaration(path) {
if (path.scope.hasOwnBinding("n")) {
// ...
}
}
// 这步是检查一个作用域是否有自己的绑定。创建一个UID
生成一个标识符,不会与任何本地定义的变量冲突:
FunctionDeclaration(path){
path.scope.generateUidIdentifier("uid");
// Node { type: "Identifier", name: "_uid" }
path.scpoe.generateUidIdentifier("uid");
// Node { type: "Identifier", name: "_uid2" }
}提升变量声明至父级作用域
FunctionDeclaration(path) {
const id = path.scope.generateUidIdentifierBasedOnNode(path.node.id);
path.remove();
path.scope.parent.push({ id, init: path.node });
}
// 结果
- function square(n) {
+ var _square = function square(n) {
return n * n
- }
+ }重命名绑定及其引用
FunctionDeclaration(path) {
path.scope.rename("n", "x");
}
// 结果
- function square(n) {
- return n * n;
+ function square(x) {
+ return x * x;
}
// 或者将绑定重命名为生成的唯一标识符
FunctionDeclaration(path) {
path.scope.rename("n");
}
// 结果
- function square(n) {
- return n * n;
+ function square(_n) {
+ return _n * _n;
}编写第一个babel插件
// 源代码:
target_js = 'foo === bar'
// AST:
//{
// type: "BinaryExpression",
// operator: "===",
// left: {
// type: "Identifier",
// name: "foo"
// },
// right: {
// type: "Identifier",
// name: "bar"
// }
//}
// 目标是将 === 运算符左右变量名替换
export default function({ types: t}) {
return {
visitor: {
BinaryExpression(path){
if (path.node.operator !== "==="){
return;
}
path.node.left = t.identifier("x");
path.node.rigth = t.identifier("y");
}
}
}
}
// 运行结果:
x === y插件选项
如果想自定义Babel插件的行为,可以指定插件特定选项:
{
plugins: [
["my-plugin", {
"option1": true,
"option2": false
}]
]
}这些选项会通过state对象传递给插件访问者:
export default function({ types: t}) {
return {
visitor: {
FunctionDeclaration(path, state){
console.log(state.opts);
//输出:
// { option1: true, option2: false}
}
}
}
}这些选项特定于插件,不能访问其他插件中的选项。
插件的准备和收尾工作
插件可以具有在插件之前或之后运行的函数。可以用于设置或清理/分析:
export default function({ types: t }) {
return {
pre(state) {
this.cache = new Map();
},
visitor: {
StringLiteral(path) {
this.cache.set(path.node.value, 1);
}
},
post(state) {
console.log(this.cache);
}
}
}在插件中启用其他语法
插件可以启用babylon plugins,以便用户不需要安装/启用他们。这可以防止解析错误,而不会继承语法插件。
export default function({ types: t }) {
return {
inherits: require("babel-plugin-syntax-jsx")
};
}babel如何编译const和let
在线babel编译
在Babeljs.io Try it out可以在线查看babel转换结果(左侧TARGETS里可以输入IE 9)。
let value = 'a'
// babel编译后:
var value = 'a'可以看到 Babel是将let编译成了var,那再来一个例子:
if (false) {
let value = 'a';
}
console.log(value); // value is not defined如果babel将let编译为var应该打印 undefined,为何会报错呢,babel是这样编译的:
if (false) {
var _value = 'a';
}
console.log(value);babel是改变量名,使内外层的变量名称不一样。
const修改值时报错,以及重复声明报错怎么实现的呢?其实在编译时就报错了。
重点来了:for循环中的 let 声明呢?
var functions = [];
for (let i = 0; i < 3; i++) {
functions[i] = function () {
console.log(i);
};
}
functions[0](); // 0babel编译成了:
var functions = [];
var _loop = function _loop(i) {
functions[i] = function () {
console.log(i);
};
};
for (var i = 0; i < 3; i++) {
_loop(i);
}
functions[0](); // 0从输入URL到整个页面显示在用户面前发生了什么
大体流程
- 浏览器从url中解析出服务器的主机名
- 浏览器将服务器的主机名转换成服务器的IP地址(DNS)
- 浏览器将端口号从url中解析出来
- 浏览器建立一条与web服务器的TCP连接
- 浏览器向服务器发送一条HTTP的请求报文
- 服务器向浏览器回送一条HTTP的响应报文
- 关闭连接,浏览器渲染
1. 浏览器查找域名对应的IP地址
IP地址:IP协议为互联网上的每一个网络和每一台主机都分配的一个逻辑地址。通过IP地址才能确定一台主机(服务器)的位置。
域名(DN,Domain Name):IP地址不便于用户记忆和使用,故用域名来代替纯数字的IP地址。
DNS(Domain Name System):每个域名都对应一个或多个提供相同服务的服务器的IP地址,只有知道服务器IP地址才能建立连接,所以需要通过DNS把域名解析成一个IP地址。
域名和IP的关系
域名和IP不是一一对应的关系,可以把多个提供相同服务的服务器IP设置为同一个域名,同一时刻一个域名可以解析出多个IP地址;同时,一个IP地址可以绑定多个域名,数量不限。
再强调一下,同一时刻一个域名是可以解析出多个IP地址的(多条A记录很常见)。只是每次域名解析请求会根据对应的负载均衡算法计算出一个IP地址返回给访客。
vivi@vivi:~$ nslookup aliyun.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: aliyun.com
Address: 140.205.60.46
Name: aliyun.com
Address: 106.11.172.9
Name: aliyun.com
Address: 140.205.135.3
Name: aliyun.com
Address: 106.11.253.83
Name: aliyun.com
Address: 106.11.249.99
Name: aliyun.com
Address: 106.11.248.146
Name: aliyun.com
Address: 2401:b180:1:60::6
Name: aliyun.com
Address: 2401:b180:1:60::5
vivi@vivi:~$ dig aliyun.com
; <<>> DiG 9.16.1-Ubuntu <<>> aliyun.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 47126
;; flags: qr rd ra; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 65494
;; QUESTION SECTION:
;aliyun.com. IN A
;; ANSWER SECTION:
aliyun.com. 300 IN A 106.11.248.146
aliyun.com. 300 IN A 106.11.249.99
aliyun.com. 300 IN A 106.11.253.83
aliyun.com. 300 IN A 140.205.135.3
aliyun.com. 300 IN A 106.11.172.9
aliyun.com. 300 IN A 140.205.60.46
;; Query time: 8 msec
;; SERVER: 127.0.0.53#53(127.0.0.53)
;; WHEN: 三 2月 21 16:12:48 CST 2024
;; MSG SIZE rcvd: 135DNS重定向
这里的知识点,对前端而言只要知道使用CDN存放静态资源这种优化策略的原理是DNS负载均衡: 如果一个大型网站的所有请求都由同一个服务器进行处理,是不现实的; 并且对用户而言,用户并不关注具体是哪台机器处理了他的请求。 因此,DNS可以根据多个服务器中每个服务器的负载量、该机器离用户的地理位置的距离等信息 返回其中某个适合的主机的IP地址,这个过程就是DNS负载均衡,又叫做DNS重定向。 CDN(Content Delivery Network)就是利用DNS的重定向技术,DNS服务器会返回一个跟用户最接近的点的IP地址。
要实现一个域名对应多个IP地址的效果,首先需要了解DNS(域名系统)的工作原理。
DNS(Domain Name System)是因特网的一项服务,它作为域名和IP地址相互映射的一个分布式数据库,能够使人们更方便地访问互联网。我们平时访问网站更多的是通过域名而非IP地址去触达,但域名并不能被计算机直接识别,所以需要通过DNS将域名“翻译”成可由计算机直接识别的IP地址。具体的操作方式,是在DNS解析操作平台,添加一条解析记录(A记录或AAAA记录),将网站的域名指向服务器的IP地址。一般情况下,一个域名对应一个IP地址,也就只需添加一条解析记录即可。如果想要实现一个域名对应多个IP地址,就需要添加多条解析记录,这也是通过DNS实现负载均衡的简单原理。
如我们想要将http://www.example.com这个域名分别指向1.1.1.1(北京电信)、2.2.2.2(上海移动)、3.3.3.3(深圳联通)三个IP。那么我们就可以在DNS服务器中配置三个A记录,分别为
- http://www.example.com IN A 114.100.20.201;
- http://www.example.com IN A 114.100.20.202;
- http://www.example.com IN A 114.100.20.203;
这样,每次域名解析请求都会根据对应的负载均衡算法计算出一个不同的IP地址返回给访客,这样就构成了一个服务器集群,并实现负载均衡的效果。在实际场景中,当北京用户访问http://www.example.com域名时,DNS会根据负载均衡算法和A记录得出一个就近IP地址1.1.1.1返回给客户端,当上海用户访问http://www.example.com域名时,DNS就会返回给2.2.2.2的服务器地址,深圳用户返回3.3.3.3。
不同用户就近访问不同的服务器IP地址,访问速度大大提升,同时也减轻了单个服务器的访问压力。
实现负载均衡的方式有很多种,其中DNS是一种十分简单和有效的技术手段,它主要有以下几点优势:
- 将负载均衡工作交给DNS,省去了网站管理维护负载均衡服务器的麻烦;
- 技术实现比较灵活,操作简单,成本低,适用于大多数TCP/IP应用;
- 对于部署在服务器上的应用来说,不需要修改任何代码就能实现不同机器上的应用访问;
- 很多DNS系统还支持基于地理位置的域名解析,可以将域名解析成距离用户地理位置最近的服务器地址,加快用户访问速度。
但基于DNS的负载均衡同样也存在一些弊端:
- 目前的DNS系统是需要经过递归服务器、顶级服务器、权威服务器以及众多缓存等多级解析的,在每一个环节都可能存在解析记录缓存。如果服务器IP发生变动,即使修改了A记录,也需要各级缓存失效后才能生效。而在解析生效前的这段时间,用户可能就会根据缓存记录访问到已经被更换过的服务器上,从而导致访问失败。
- DNS负载均衡采用的是简单的轮询算法,不能区分不同服务器之间的性能和负载差异,不能反映服务器当前的运行状态,所以负载均衡效果并不太好。
- 为了本地DNS服务器能够及时同步权威服务器上的最新记录,所以一般将DNS缓存刷新时间设置得比较小,这就会导致DNS频繁发起解析请求,从而造成额外的网络问题。
所以一些大型网站总是使用DNS域名解析作为第一级负载均衡手段,然后在通过提供负载均衡服务的内部服务器再进行负载均衡,将最终请求发到真实的服务器上,从而完成最终请求。
2. 浏览器根据IP地址与服务器建立socket连接
建立连接——三次握手
知道了服务器的IP地址,便可开始与服务器建立连接了,通信连接的建立需要经历以下三个过程:
- 客户端首先发送一个带有SYN标志的数据包给服务端(您好,我想认识你);
- 服务端接受SYN数据包之后,回传一个SYN/ACK标志的数据包以示传达确认连接信息(好的,很高兴认识你);
- 客户端收到SYN/ACK的确认数据包之后,再回传一个ACK标志的数据包给服务端,表示‘握手’结束(我也很高兴认识你),至此,客户端便与服务器建立了连接。
说明:
- TCP协议:三次握手的过程采用TCP协议,其可以保证信息传输的可靠性,三次握手过程中,若一方收不到确认信息,协议会要求重新发送信号。
TCP的作用是啥?
- 提供无差错的数据传输
- 按序传输(数据总是会按照发送顺序到达)
- 未分段的数据流(可以在任意时刻以任意尺寸将数据发送出去)
3. 浏览器与服务器通信:浏览器发出请求、服务器处理请求、渲染
当服务器与客户端建立了连接之后,客户端便开始与服务器进行通信。 网页请求是一个客户端向服务器请求数据==>服务器返回相应数据的单向的请求过程。
- 浏览器根据URL生成HTTP请求,请求中包含请求文件的位置、请求文件的方式等信息;
- 服务器接到请求后,会根据HTTP请求中的信息来决定如何获取相应的HTML文件;
- 服务器将得到的HTML文件发送给浏览器;
- 在浏览器还没有完全接受完HTML文件时便开始渲染、显示页面;
- 在执行HTML中代码时,根据需要,浏览器会继续请求图片、CSS、Javascript、视频、音频等文件,过程类似。
针对浏览器渲染、显示页面的过程,说明如下:
- 浏览器端是一个边解析边渲染的过程。
- HTML Parser将HTML内容解析为DOM Tree,CSS Parser将CSS内容解析为样式规则(Style Rules);
- 根据样式规则和DOM Tree来渲染树(Render Tree),在这个渲染树的过程中会发生回流(layout/reflow/relayout),回流就是浏览器计算各个盒模型的位置、大小等属性的过程;
- 等浏览器确定了盒模型的位置、尺寸等数据后开始绘制页面,这个过程称为重绘(Painting/repaint)。
4. 浏览器与服务器断开连接
断开连接——四次挥手:
- 客户端向服务端先发送一个带有FIN标志的数据包(我想关闭);
- 服务端接受FIN数据包之后,回传一个ACK的数据包给客户端以示传达确认关闭信息(知道了:只是表示确认我知道你想要关闭了,但是我可能还有事还在处理,不一定现在就关)
- 服务端向客户端发送一个FIN标志的数据包,请求关闭连接(我处理好了,可以关闭了)
- 客户端收到FIN的数据包之后,回传一个ACK的数据包给服务端,以表示确认关闭(好的,那我关了),服务器收到确认信号后断开连接。
说明:
- 为什么服务器在接到断开请求时不立即同意断开:当服务器收到断开连接的请求时,可能仍然有数据未发送完毕,所以服务器先发送确认信号,等所有数据发送完毕后再同意断开;
- 第四次挥手后,主机发送确认信号后并没有立即断开连接,而是等待了2个报文传送周期,原因是:如果第四次挥手的确认信息丢失,服务器将会重新发送第三次挥手的断开连接的信号,而服务器发觉丢包与重新发送断开连接到达主机的时间正好为2个报文传输周期。
前端优化
常见的前端优化技巧
- 大体
- 减少服务器请求数:
- 将多个JS/CSS文件进行合并;
- 图片不需要经常改动时,可使用CSS sprite;
- 如果仅单个页面使用某JS/CSS文件,可以直接将文件内容放于html页面中(若多个页面公用相同的JS/CSS)文件,则不该这么做,应该利用好浏览器缓存功能。
- 加快资源访问速度:
- CDN。
- 减小文件大小:
- 将图片适当压缩;
- 压缩JS/CSS文件。
- 提高代码执行效率。
- 减少服务器请求数:
- JS
- 需要多次使用的值(比如需要遍历的数组对象的length),应先将其存为一个变量,然后调用该变量以减少JS查询的时间;
- 于页面底部引入脚本,先将页面内容呈现给用户;
- 提高代码复用率,减少代码冗余。
- CSS
- 于页面头部引入样式,避免用户看到布局错乱的内容;
- 不要使用CSS表达式。
- HTML
- 主要是SEO方面的优化,添加name为keyword和description的meta标签,减少外链,外链上加上rel="nofollow",标签尽量符合语义,减少不必要的嵌套标签。
- 其他
- 预解析
- 比如首页添加≶link rel="prerender" href="/about.html" />
- 利用缓存
- 比如可以使用百度静态资源公共库(cdn.code.baidu.com),若用户以前访问过其他引用了相同资源地址的文件的话,缓存的优势就出来了。
- 预解析
- 总结:像压缩图片这种方法对提高网页加载速度的效果是很明显的,但是有些优化方法对于访问量小的小型网站而言并没有啥好呢么必要,比如:如果某JS文件本来就只用100来行,压缩后减少的文件大小对页面访问速度的提高等于没有,对服务器压力的减少也没啥意义。
高频率触发的事件的性能优化
一些事件,比如touchmove可能会被高频率地触发,如果该事件对应的handler函数中需要处理的逻辑较多,可能会导致FPS下降影响程序流畅度,在这种情况下,可以考虑将handler中的执行体放于setTimeout(function () { //执行的代码 }, 0)中,程序会变流畅。
debounce 防抖
当事件触发时,函数不立即执行,而是延迟一段时间后再执行。并且这期间只要事件再次被触发,就重新计算延迟时间。所以如果事件被不停触发的话,函数就一直不会被执行。
/**
* 将函数进行防抖处理,生成一个新的防抖函数
* @param {function|Promise} fn - 需要进行防抖处理的原始函数(可以是async函数)
* @param {number} [delay = 1000] - 防抖延迟时间,单位 ms
* @param {boolean} [immediate = false] 不在延迟时间内的每次第一次触发时是否立即执行
* @param {function} [callback] - 回调函数,用于获取每次最终执行后的结果
* @return {function} 生成的防抖函数
*/
function debounce(fn, delay = 1000, immediate = false, callback) {
let timer = 0
let isFirstTime = false
let self = this
function returnFunc(...args) {
if (timer) {
clearTimeout(timer)
timer = 0
}
const mainTask = () => {
let errorObj = null
// apply 第二个入参为数组,call 和 bind 的第二个入参是0到多个arguments
let result = fn.apply(self, args)
const doCallback = () => {
if (typeof callback === 'function') {
// 第一个参数表示error,第二个参数表示实际结果
callback(errorObj, result)
}
}
if (result instanceof Promise) {
result
.then((res) => {
result = res
doCallback()
})
.catch((err) => {
errorObj = err
doCallback()
})
} else {
doCallback()
}
}
if (immediate && isFirstTime) {
mainTask()
isFirstTime = false
}
timer = setTimeout(() => {
mainTask()
isFirstTime = true
}, delay)
}
return returnFunc
}throttle 节流
节流的话,当事件被频繁触发时,函数也只会按指定的间隔频率被触发,函数被触发的时间间隔只会大于等于指定时间间隔。节流与防抖的最大区别在于防抖的核心是延时等待,节流的核心在于保证最小时间间隔。
function throttle (fn, delay) {
let lastTime = 0
return function () {
const currentTime = Date.now()
if (lastTime > 0 && currentTime - lastTime < delay) {
return
}
lastTime = currentTime
fn.apply(this, arguments)
}
}安全
CSRF:Cross-site request forgery,跨站请求伪装
攻击者会在用户不知情的情况下通过用户浏览器向网站后端发起请求。攻击者可以通过XSS攻击的方式触发CSRF攻击。
比如,在一个未做好安全防范的聊天室或者论坛上,攻击者发送了一个img标签:
<!-- 注意:这个img标签的src属性值并非一个真正的图片地址,而是一个请求银行网站的链接地址 -->
<img src="https://bank.example.com/withdraw?account=bob&amount=1000000&for=mallory" />如果一个用户在访问这个渲染好的html片段之前正好访问过这个银行网站, 并且cookie信息未过期,且银行方也没有做除了cookie之外的其他校验,那么这个用户的钱就有可能被直接转走了!
通过img标签触发的都是get请求,那是不是转账这种敏感请求都用post不用get就没这个问题了呢?也不是的,因为攻击者也可以通过构造form表单或者直接注入js脚本来实现非get请求。
<form action="https://bank.example.com/withdraw" method="POST">
<input type="hidden" name="account" value="bob" />
<input type="hidden" name="amount" value="1000000" />
<input type="hidden" name="for" value="mallory" />
</form>
<script>
window.addEventListener('DOMContentLoaded', () => {
document.querySelector('form').submit();
})
</script>上面这段代码,只要是放在一个看不叫的iframe标签内部的话,触发时就不会导致页面跳转,也就不会被用户感知到。
预防措施:
- GET接口应该是幂等的。用别的比如POST接口去处理会产生变化且不以查询数据为目的的请求。POST接口应避免同时支持解析GET请求和查询字符串参数。
- 对所有可能会执行“改动操作”的非GET请求,应在请求体中携带一个可以区分不同用户的CSRF token。服务端在接收到请求后,校验token是否有效,如无效则忽视该请求。
- 这种预防措施生效的前提是假定攻击者无法获取到程序下发给用户的CSRF token。
- 每次登录都需要重新生成新的token。
- 用于敏感操作的cookie的有效期应该设置得短一点,同时响应头里的SameSite属性值应设置为Strict。在支持SameSite响应头的浏览器中,这个设置能保证跨域请求不会携带该敏感cookie,进而服务端校验请求时可以直接拦截。
- 应同时采用CSRF token和SameSite cookie。这样即便在SameSite cookie无效的情况下(比如从子域名发起的攻击请求。
XSS:Cross-site scripting,跨站脚本攻击
跨站脚本攻击(XSS)是攻击者通过向网站的客户端注入恶意代码来实现的。 受害者执行这段代码之后,攻击者就可以绕过访问权限的拦截,模拟用户行为。
如果Web应用没有采用足够的校验和编码措施来进行预防的话,这些攻击就可能会得逞。 用户的浏览器无法判断这些恶意脚本是“恶意的”,所以会允许它们访问cookie、token或者其他网站敏感信息,也会允许这些代码去修改HTML内容。
当动态内容,或者来自不可信来源(通常是网络请求)的数据,在未经校验是否有恶意内容的情况下被发送给用户时,就容易出现跨站脚本攻击。
这些恶意内容通常包括JavaScript代码,有时候也包括HTML、Flash,或者其他浏览器可以执行的代码。XSS攻击有很多类型,但通常包括:
- 将cookie或者session信息等私有数据传输给攻击者;
- 将用户重定向到一个由攻击者控制的网页上;
- 伪装成站点身份在用户的机器上执行其他恶意的操作。
我们可以将跨站脚本攻击分成3类:
- 存储型跨站脚本攻击。攻击者注入的脚本会被永久存储在目标服务器上,当受害者通过浏览器向服务端请求数据时,恶意脚本被发送给了受害者。
- 反射型跨站脚本攻击。当用户被诱导去点击恶意链接、提交恶意表单、或者访问恶意网站时,恶意内容被注入到目标网站,目标网站通过错误提示、搜索结果或者其他响应形式将注入代码返回到用户浏览器。此时,用户浏览器认为这些恶意代码来自可信任的来源,就正常去执行它们了。
- DOM型跨站脚本攻击。注入脚本将原先正常客户端脚本所需的DOM环境进行了恶意修改。导致客户端代码的运行结果不在预期内。
前端加密的意义
前端加密的意义不是为了防止中间人,而是提供一种隐私保护服务。
这样即使因为使用的是http协议导致通信过程被攻击者拦截, 攻击者直接拿到的也不是用户的原始密码,而是加密字符串,这个加密字符串可以直接被用于当前网站。 但是当攻击者拿这个加密字符串去其他网站尝试使用时,只要其他网站使用的不是同一套加密逻辑,就没有用。 就是说用户在其他网站使用这个密码还是相对安全的。
攻击者如果能拿到密码明文的话,还是很危险的,前端加密一定程度上可以增加这个难度(增加了攻击者从加密字符串破解出明文密码的过程)。
如何安全传输密码?
一般做法是使用https协议,并且对密码采用非对称加密算法(如RSA)处理后再进行传输。
使用https协议
使用https协议,可以避免用户密码在网络上裸奔。http协议是明文传输的,有3大风险:
- 窃听/嗅探风险:第三方可以截获通信数据。
- 数据篡改风险:第三方获取到通信数据后,会进行恶意修改。
- 身份伪造风险:第三方可以冒充他人身份参与通信。
https原理是什么呢?为什么它能解决http的三大风险呢?
https = http + SSL/TLS, SSL/TLS 是传输层加密协议, 它提供内容加密、身份认证、数据完整性校验, 以解决数据传输的安全性问题。
一次完整的https请求流程如下:
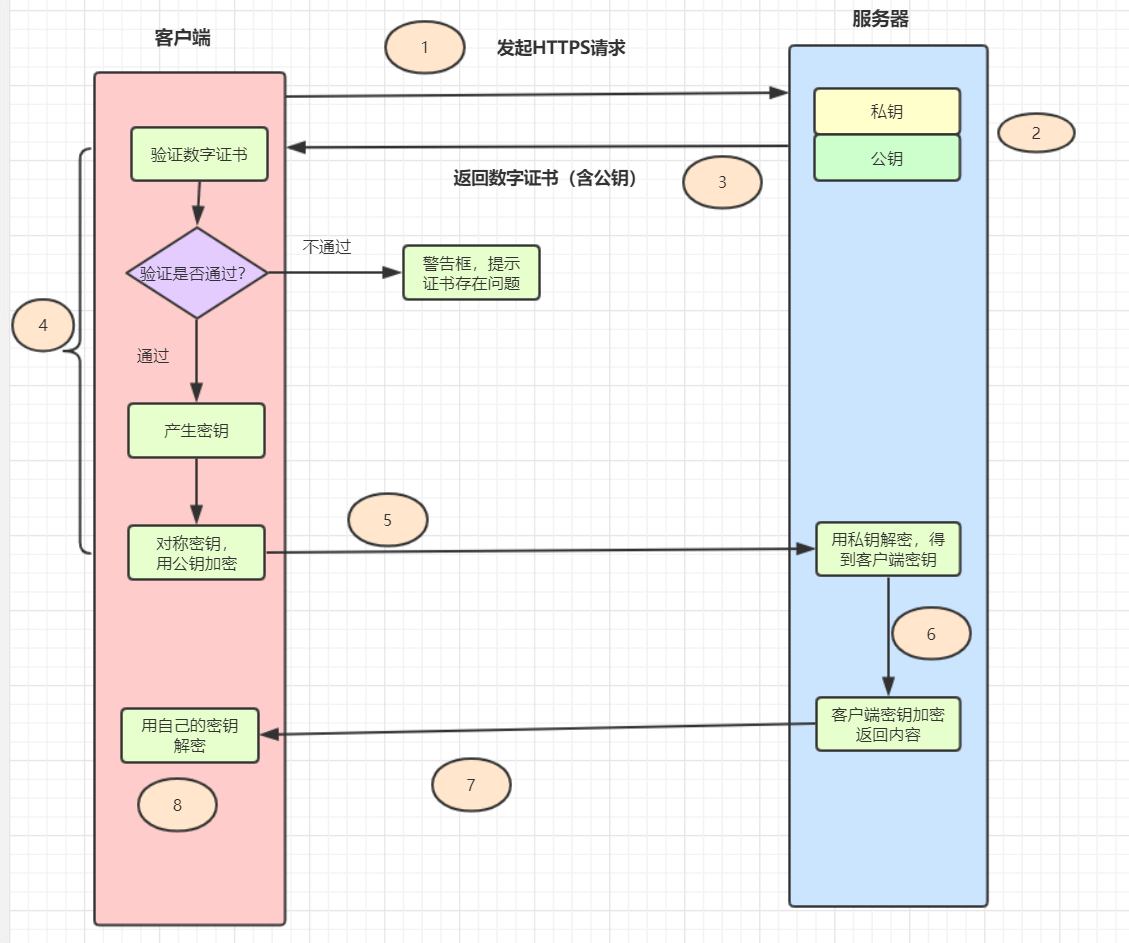
- 客户端发起https请求
- 服务器必须要有一套数字证书,可以自己制作,也可以向权威机构申请。这套证书其实就是一对公私钥。
- 服务器将自己的数字证书(含有公钥、证书的颁发机构等)发送给客户端。
- 客户端收到服务器端的数字证书之后,会对其进行验证,主要验证公钥是否有效,比如颁发机构,过期时间等等。如果不通过,则弹出警告框。如果证书没问题,则生成一个密钥(对称加密算法的密钥,其实是一个随机值),并且用证书的公钥对这个随机值加密。
- 客户端会发起https中的第二个请求,将加密之后的客户端密钥(随机值)发送给服务器。
- 服务器接收到客户端发来的密钥之后,会用自己的私钥对其进行非对称解密,解密之后得到客户端密钥,然后用客户端密钥对返回数据进行对称加密,这样数据就变成了密文。
- 服务器将加密后的密文返回给客户端。
- 客户端收到服务器发返回的密文,用自己的密钥(客户端密钥)对其进行对称解密,得到服务器返回的数据。
https的数据传输过程,数据都是密文的。 但是,即时使用了https协议传输密码信息,也不一定就安全了。 比如,https完全就是建立在证书可信的基础上的。 如果遇到中间人伪造证书,一旦客户端通过验证,安全性就没了。 通过伪造证书,https也是可能被抓包的。
加密算法
如上所述,即使用了https协议传输用户密码,只要用户信任了伪造证书,也还是会有安全隐患的。所以,对于密码,传输前还是需要先进行加密的。
加密算法有对称加密和非对称加密两种。
对称加密算法
加密和解密使用“相同密钥”的加密算法。 使用对称加密算法时,需要考虑如何将密钥给到客户端的问题,如果还是通过网络传输的方式,如果密钥在传输过程中被中间人拿到的话,还是有风险的。
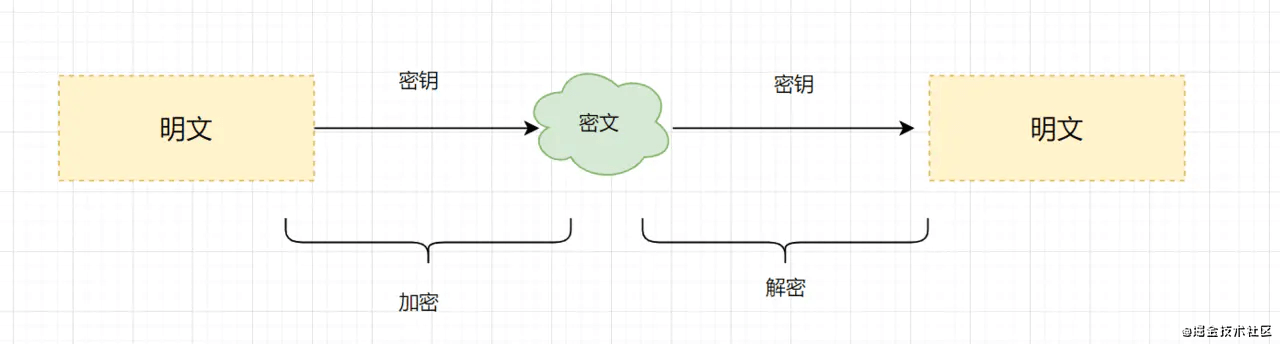
常见的对称加密算法有:
- DES:基于使用56位密钥的对称算法。
- 3DES:每个数据块应用三次数据加密标准(DES)算法。
- AES:密码学中的高级加密标准。
- RC5:一种因简洁著称的对称分组加密算法。
- RC6:基于RC5设计的,以更好地符合AES的要求。
非对称加密算法
非对称加密算法需要2个密钥(公钥和私钥)。公钥和私钥是成对存在的,用公钥对数据进行加密,用对应的私钥才能解密。 使用费对称加密算法时,也需要考虑如何将密钥、公钥给到客户端的问题, 如果公钥在网络传输过程中被中间人拿到的话,中间人可以伪造公钥,把伪造的公钥给客户端,然后用自己的私钥解密从客户端过来的加密数据。
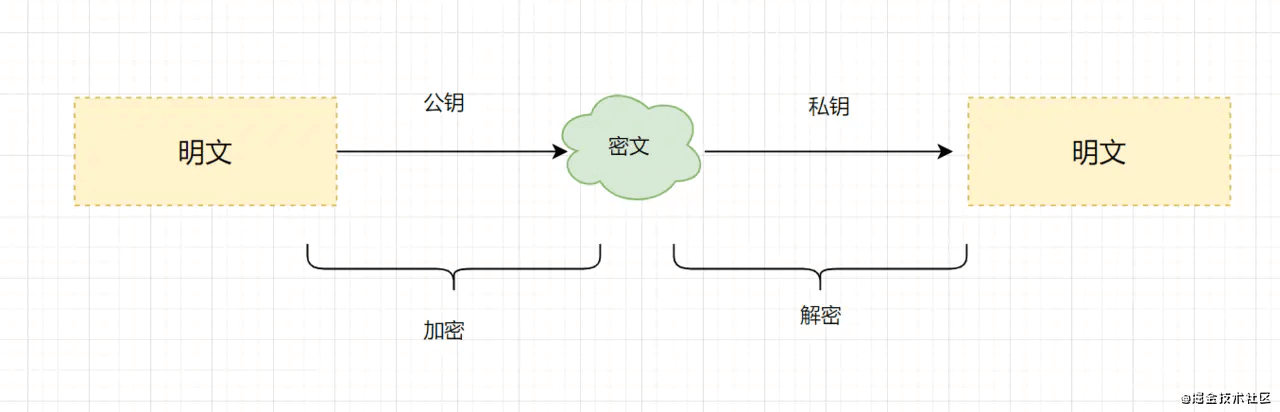
常见的非对称加密算法有:
- RSA:基于因子分解。
- Elgamal:基于离散对数。
- DSA:Digital Signature Algorithm,数字签名算法。
- D-H:(Diffie-Hellman)密钥交换算法。
- ECC:(Elliptical Curve Cryptography)——椭圆曲线加密。
如何安全存储密码?
密码安全送达服务端后,一定不能明文存储密码到数据库。可以先用哈希摘要算法加密密码,然后再保存到数据库。
哈希摘要算法:只能从明文生成一个对应的哈希值,不能反过来根据哈希值得到对应的明文。
MD5加密
MD5是一种非常经典的哈希摘要算法,被广泛应用于数据完整性校验、数据摘要、数据加密等。
直接MD5加密
对原始密码直接进行MD5加密的话是很不安全的。因为攻击者用彩虹表可以很容易破解出密码。 如果把所有20位以内的数字和字母组合的密码全部计算其MD5哈希值,并把密码和对应哈希值存到一个超大数据库里,就是一个彩虹表了。
提醒:网络上已经有很多MD5免费破解网站了,可以自己随便试。
优化方案:密码加盐后再进行MD5加密
先对字段进行加盐处理,再进行MD5加密,即MD5(password + salt)。只要salt够长,是没有办法通过彩虹表反查的。
在密码学中,通过在密码任意固定位置插入特定的字符串,让散列后的结果和使用原始密码的散列结果不相符,这个过程称为“加盐”。
加盐有几个注意事项
- 不能再代码中写死盐,且盐需要有一定的长度(盐写死太简单的话,攻击者可能注册几个账号反推出来)。
- 每个密码都有独立的盐,并且盐要长一点,比如超过20位。(如果盐和原始密码都太短的话,容易被破解)。
- 盐最好是随机的值,并且是全球唯一的,这样就不可能有现成的彩虹表可以用于破解。
BCrypt
即使MD5加密前加了盐,密码仍有可能被暴力破解。可以采取更慢一点的算法,增加攻击者破解密码所需的成本,迫使攻击者放弃攻击。
为了应对暴力破解,我们需要非常耗时而非高效的哈希算法。 BCrypt算法的特点是可以通过参数设置重复计算的次数,重复计算的次数越多耗时越长。 如果计算一个哈希值需要耗时1秒以上,破解一个6位纯数字密码就需要耗时11.5天以上,更不要说高安全级别的密码了。暴力破解密码的可能性就很低了。
实际上,Spring Security 已经废弃了MessageDigestPasswordEncoder,推荐使用BCryptPasswordEncoder,也就是BCrypt来进行密码哈希。
如何应对暴力破解
感知到暴力破解危害时,应开启短信验证、图形验证码、账号暂时锁定等防御机制来进行抵御。
如何明确是暴力破解的话,可以采取封IP等措施。
refresh token 和 access token
本文参考了以下文章:
access token 是用来临时授权用户访问受保护的资源或执行特定操作用的,通常有效期较短(分钟级),以减少 token 被泄露带来的风险(攻击者可用于 access token 获取保密资源的时间越少越好)。refresh token 则是用于在 access token 过期后获取新的 access token 用的,从而减少用户因为 access token 过期而总是需要重复登录的问题。
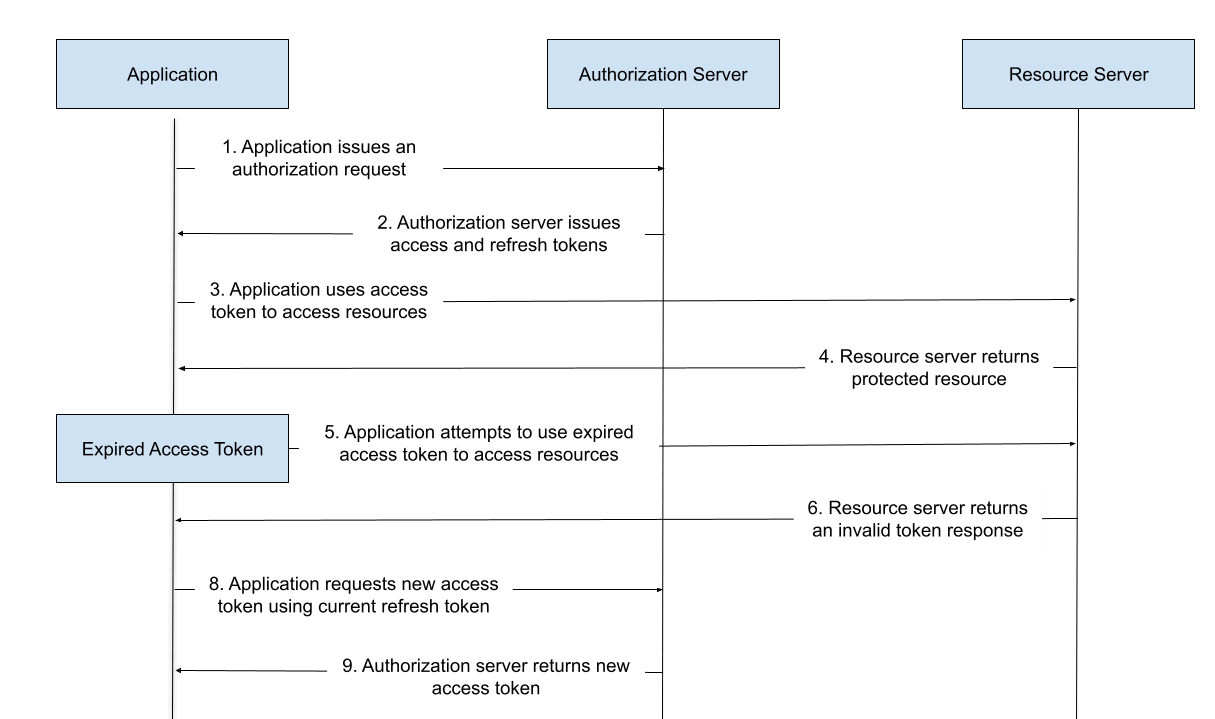
refresh token 的一些最佳实践
1、轮转 refresh token (RTR,Refresh token rotation)
RTR 通过降低 refresh token 的有效期来提高了安全性。Refresh token rotation 的意思是,每次使用 refresh token 去获取 access token 时,服务端就让旧的 refresh token 失效,并返回给前端一个新的 refresh token。基本上可以认为,在该方案下,每个 refresh token 只能使用一次。这样,当攻击者获取到 refresh token 后,该 refresh token 失效的可能性将大大增加。
2、监测 refresh token 的复用
除了轮转 refresh token,还应该监测 refresh token 的复用。如果授权服务器发现有请求尝试使用一个已经用过的、无效了的 refresh token 去获取新 access token 的行为的话,授权服务器应让相关的 token 全部失效,包括所有已经下发给用户的 access token 和最近下发的 refresh token。
3、安全地存储 refresh token
4、设置合理的过期时间
度量过期时间时,其起始时间除了用下发 token 的时间,也可以用 token 最后一次被使用的时间。
5、监控 refresh token 的异常使用情况
在一个应用中,服务端解析 access token 的场景要比解析 refresh token 的场景多得多,我们可以在 access token 中仅包好较少的用户信息,而在 refresh token 中包含较多的信息(比如用户 ip 地址),然后在 refresh token 刷 access token 的请求中,对用户 ip 地址是否有变动等进行检查。
Cache
HTTP 缓存见 HTTP 相关章节,本节不再赘述。
Disk Cache 和 Memory Cache
Disk Cache
当你访问一个网站的时候,一些资源(图片、CSS样式文件、JS脚本文件等)可能会被储存到你的硬盘中。这种就就是硬盘缓存(Disk Cache)。
硬盘缓存的优点有:
- 可长期保存(数周甚至数月之久)。
- 通常来说,一台机器中硬盘空间相对内存空间来说要多得多,所以硬盘缓存可以存储大量的内容。
硬盘缓存的缺点:
- 访问硬盘中的资源比直接访问内容中的资源要慢一些。
Memory Cache
Memory Cache 与 Disk Cache 不同的地方在于,命中 Memory Cache 的资源是被储存在设备的 RAM 中的,这种缓存资源访问起来速度非常快。但是只要你关掉浏览器,这些缓存就会被丢弃,也就是说下一次你重新打开浏览器尝试去访问这些资源时,就已经没有缓存了。
MySQL
基本上前端的职业发展走到后期,技能点自然而然会点到后端这块的。那么最主流的 MySQL 就是一个必须要熟悉的数据库。
MySQL
MySQL 是当下流行的关系数据库管理系统(Relational Database Management System, RDBMS),使用 C 和 C++ 语言编写而成。MySQL 支持多线程,可以充分利用CPU资源。
MySQL 基础知识
关系数据库设计理论三大范式
- 第一范式(1NF,First Normal Form):目标是确保每列都是不可再分的最小数据单元(也被称为最小的原子单元),则满足第一范式。
- 第二范式(2NF,Second Normal Form):要求每张表只描述一件事情。
- 第三范式(3NF,Third Normal Form):如果一个关系满足第二范式,并且除了主键以外的其他列都不依赖于主键列,则满足第三范式。
连接数据库
mysql -h host -u user -p
# 如果在运行 MySQL 的同一台机器上登录,则可以省略主机名:
mysql -u user -p创建数据库和表
创建数据库
- 在 UNIX 操作系统中,数据库的名称是区分字母大小写的。
CREATE DATABASE database_name;创建表
create table table_name (column_name column_type);例子:
create table if not exists `userinfo` (
`id` int unsigned auto_increment,
`name` varchar(100) not null,
`age` int not null,
`date` date,
primary key ( `id` )) engine=innodb default charset=utf8;说明:
- primary key:用于把列定义为主键,可以使用多列来定义主键,列之间以逗号分隔。
- engine:设置存储引擎。
- charset:设置字符集的编码。
查询指定表的结构
describe table_name;如上面创建的 userinfo 表,查询出来的信息如下:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| id | int unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(100) | NO | NULL | ||
| age | int | NO | NULL | ||
| date | date | YES | NULL |
MySQL 数据类型
数字数据类型
- 整数类型:integer、int、smallint、tinyint、mediumint、bigint。
- 定点类型:decimal、numeric。
- 浮点类型:float、double。
- 位值类型:bit。
整数类型所需的存储空间和取值范围:
| 类型 | 存储空间(字节) | 有符号的最小值 | 无符号的最小值 | 有符号的最大值 | 无符号的最大值 |
|---|---|---|---|---|---|
| tinyint | 1 | -128 | 0 | 127 | 255 |
| smallint | 2 | -32768 | 0 | 32767 | 65535 |
| mediuminit | 3 | -8388608 | 0 | 8388607 | 16777215 |
| int | 4 | -2147483648 | 0 | 2147483647 | 4294967295 |
| bigint | 8 | -2^63 | 0 | 2^63 - 1 | 2^64 - 1 |
decimal 列声明中,可以指定精度和小数位数:
# 精度为5,小数位数为2,取值范围为 -999.99 ~ 999.99
salary decimal(5,2)bit 类型的表示方式为 bit(m),m 的取值范围为 1~64(换算成十进制的话,就是 0 ~ 2^64-1)。bit 类型存储的是二进制字符串。
日期和时间数据类型
表示时间值的日期和时间类型有这样几种:datetime、date、timestamp、time 和 year。每种时间类型都有一个有效值范围和一个“零”值,当指定的日期或时间数据不符合规则时,MySQL 将使用“零”值来替换。MySQL允许将“零”值(0000-00-00)存储为“虚拟日期”。在某些情况下,这比使用 null 值更方便,并且使用更少的数据和索引空间。
所有日期和时间类型格式的详细说明如下:
| 类型 | 存储字节 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| date | 3 | 1000-01-01 到 9999-12-31 | YYYY-MM-DD | 日期值 |
| time | 3 | '-838:59:59' 到 '838:59:59' | HH:MM:SS | 时间值 |
| year | 1 | 1901 到 2155 | YYYY | 年份值 |
| datetime | 8 | 1000-01-01 00:00:00 到 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 日期和时间值 |
| timestamp | 4 | 1970-01-01 00:00:00 到 2038-01-19 11:14:07 | YYYY-MM-DD HH:MM:SS | 日期和时间值 |
字符串数据类型
在 MySQL中,字符串数据类型有:char、varchar、text、binary、varbinary、blob、enum 和 set。对于数据类型定位为 char、varchar 和 text 的列,MySQL 以字符为单位定义长度规范。对于数据类型为 binary、varbinary 和 blob 的列,MySQL 以字节为单位定义长度规范。
当列定义为 char、varchar、enum 和 set 的数据类型时,同时还可以指定列的字符集,尤其在存储中文时,建议指定字符集格式为 utf8,以防止出现乱码问题。
create table mytable
(
c1 varchar(255) character set utf8,
c2 text character set latin1 collate latin1_general_cs
);blob 类型
blob类型的值是一个二进制的大对象,可以容纳可变数量的数据。tinyblob、blob、mediumblob 和 longblob 类型的区别仅在于它们可以存储的值的最大长度不相同。
enum 类型
enum 类型(即枚举类型)的列值表示一个字符串对象,其值选自定义列时给定的枚举值。enum 类型具有以下优点:
- 在列具有有限的数据集合的情况下压缩数据空间。输入的字符串会自动编码为数字。
- 可读的查询和输出。在查询时,实际存储的数字被转换为相应字符串。
定义时,注意枚举值必须是带引号的字符串。
create table mytable (
name varchar(40),
size enum('x-small', 'small', 'medium')
);set 类型
set 类型(集合类型)的列值表示可以有零个或多个字符串对象。一个 set 类型的列最多可以有64个不同的成员值,并且每个值都必须从定义列时指定的值列表中选择。set 类型成员值本身不应包含英文逗号。
create table myset (col set('a', 'b', 'c', 'd'));JSON 数据类型
create table mytable (jdoc json);MySQL 支持 JSON 数据类型,JSON 数据类型具有如下优点:
- 存储在 JSON 类型列中的 JSON 文档会被自动验证,无效的文档会产生错误。
- 存储在 JSON 类型列中的 JSON 文档会被转换为允许快速读取文档元素的内部格式。
- 在 MySQL 8中,优化器可以执行 JSON 类型列的局部就地更新,而不用删除旧文档后再将整个新文档写入该列。
在 MySQL 中,JSON 类型列的值会被写为字符串。如果字符串不符合 JSON 数据格式,则会产生错误。
MySQL 基本操作
数据库和数据表的创建与查看
查看 MySQL 服务器中的所有数据库:
show databases;切换使用指定数据库:
USE database_name;查询当前操作的数据库名称:
SELECT DATABASE();查询当前数据库下的所有表:
SHOW TABLES;删除数据库:
drop database if exists mydb;重新创建 mydb 数据库,指定编码为 utf8:
create database mydb charset utf8;查看建库时的雨具(并验证数据库使用的编码):
show create database mydb;进入 mydb 库,然后删除 student 表(如果存在):
use mydb;
drop table if exists student;创建 student 表:
drop table if exists student;
create table student (
id int primary key auto_increment,
name varchar(50),
gender varchar(2),
birthday date,
score double
);上述语句创建的表结构如下:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(50) | YES | NULL | ||
| gender | varchar(2) | YES | NULL | ||
| birthday | date | YES | NULL | ||
| score | double | YES | NULL |
查看创建时的语句:
show create table student;
# 得到如下内容:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`gender` varchar(20) DEFAULT NULL,
`birthday` date DEFAULT NULL,
`score` double DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8;新增、修改、删除表数据
插入记录:
insert into student(name,gender,birthday,score)
values('zhangsan','m','1999-2-2',70);
insert into student
values(null,'lisi','m','1997-2-2',80);
insert into student
values(null,'wangwu','m','1989-2-2',75);查询表中所有学生的信息:
select * from student;得到:
| id | name | gender | birthday | score |
|---|---|---|---|---|
| 1 | zhangsan | m | 1999-02-02 | 70 |
| 2 | lisi | m | 1997-02-02 | 80 |
| 3 | wangwu | m | 1989-02-02 | 75 |
修改student表中所有学生的成绩,加10分特长分:
update student set score=score+10;修改 student 表中 zhangsan 的成绩,将成绩改为 98 分:
update student set score=98 where name='zhangsan';删除性别是w的数据:
delete from student where gender='w';删除表中所有数据,数据还能找回:
delete from student;清空表数据,效率高,但是数据找不回:
truncate studen;MySQL 基础查询和 where 子查询
准备数据(部门表和员工表):
# 创建部门表
drop table if exists dept;
create table dept (
deptno int(2) not null,
dname varchar(14) collate utf8_bin default null,
loc varchar(13) collate utf8_bin default null,
primary key (deptno)
) engine=innodb default charset = utf8 collate = utf8_bin;
# 创建员工表
drop table if exists emp;
create table emp (
eno integer not null,
ename varchar(20) not null,
sex varchar(20) not null,
birthday varchar(20) not null,
jdate varchar(20) not null,
salary integer not null,
bonus integer not null,
epost varchar(20) not null,
deptno int(2) not null,
primary key (eno)
);查询emp表中的所有员工,显示姓名、薪资、奖金:
select ename, salary, bonus from emp;查询emp表中的所有部门和职位:
select deptno, epost from emp;查询emp表中的所有部门和职位,并对数据去重:
select distinct deptno, epost from emp;查询emp表中薪资大于5000的所有员工,显示员工姓名、薪资:
select ename, salary from emp where salary > 5000;查询emp表中总薪资(薪资+奖金)大于6500的所有员工,显示员工姓名、总薪资:
select ename, salary + bonus from emp
where salary + bonus > 6500;得到:
| ename | salary + bonus |
|---|---|
| wanger | 8500 |
| lisi | 7000 |
| wangming | 9000 |
注意上面查询结果中的表头,将表头中的“salavy+bonus”修改为“total-salary”:
select ename, salary + bonus 'total-salary' from emp
where salary + bonus > 6500;得到:
| ename | total-salary |
|---|---|
| wanger | 8500 |
| lisi | 7000 |
| wangming | 9000 |
查询emp表中薪资在7000和10000之间的员工,显示员工姓名和薪资:
-- 普通写法
select ename, salary
from emp
where salary >= 7000 and salary <= 10000;
-- 使用 `between and` 的写法
select ename, salary
from emp
where salary between 7000 and 10000;查询emp表中薪资为5000、6000、8000的员工,显示员工姓名和薪资:
-- 普通写法
select ename, salary
from emp
where salary = 5000 or salary = 6000 or salary = 8000;
-- 使用 `in` 的写法
select ename, salary
from emp
where salary in (5000, 6000, 8000);查询emp表中薪资不为5000、6000、8000的员工,显示员工姓名和薪资:
-- 普通写法
select ename, salary
from emp
where not (
salary = 5000 or salary = 6000 or salary = 8000
);
-- 使用 `not in` 的写法
select ename, salary
from emp
where salary not in (5000, 6000, 8000);查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资:
select ename, salary
from emp
where salary > 4000 or salary < 2000;MySQL like 模糊查询
查询emp表中姓名中以“li”开头的员工,显示员工姓名、薪资:
select ename, salary sal
from emp where ename like 'li%';查询emp表中姓名中包含“li”的员工,显示员工姓名、薪资:
select ename, salary sal
from emp where ename like '%li%';查询emp表中姓名以“li”结尾的员工,显示员工姓名、薪资:
select ename, salary sal
from emp
where ename like '%li';MySQL 分组查询、聚合函数、排序查询
对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数:
select epost, count(*) from emp group by epost;按照部门分组,显示部门、最高薪资:
select deptno, max(salary)
from emp
group by deptno;查询每个部门的最高薪资,显示部门、员工姓名、最高薪资:
select emp.deptno, ename, t1.msal
from emp,
(
select deptno, max(salary) msal
from emp group by deptno
) t1
where emp.deptno = t1.deptno and emp.salary = t1.msal;统计emp表中薪资大于3000的员工个数:
select count(eno) from emp where salary > 3000;统计emp表中所有员工的薪资总和(不包含奖金):
select sum(salary) from emp;统计emp表中员工的平均薪资(不包含奖金):
-- 普通方式计算平均数
select sum(salary) / count(*) from emp;
-- 使用 `avg` 函数求平均数
select avg(salary) from emp;查询emp表中所有在1978年和1985年之间出生的员工,显示姓名、出生日期:
select ename, birthday
from emp
where year(birthday) between 1978 and 1985;查询要在本月过生日的所有员工:
SELECT *
FROM emp
WHERE MONTH(CURDATE()) = MONTH(birthday);对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资:
-- 默认就是升序排序,所以 `asc` 可以省略不写
select ename, salary from emp order by salary;对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金:
select ename, bonus
from emp
order by bonus desc;查询emp表中的所有记录,分页显示首页记录(前3条记录):
select * from emp limit 0,3;查询emp表中的所有记录,分页显示(每页显示3条记录),返回第2页:
select * from emp limit 3,3;MySQL 关联查询
查询部门和部门对应的员工信息:
select *
from dept, emp
where dept.deptno = emp.deptno;查询所有部门和部门下的员工,如果部门下没有员工,则员工显示为null(一定要列出所有部门):
select *
from dept
left join emp no dept.deptno = emp.deptno;上面这个 SQL 查询语句使用了 left join 关键字来连接 dept 和 emp 表,并以 deptno 字段为连接条件,查询并返回两张表中相关记录的字段值。具体地说,该查询会遍历 dept 表中的每一行记录,然后查找与之对应的 emp 表中的记录,如果两者中存在符合连接关系的记录,则会将它们的字段值合并为一条查询结果,并以列的形式呈现在最终的查询结果中。如果某个部门在 emp 表中没有关联记录,则该部门在查询结果中也会被保留,但其关联字段值会被填充为 null。
查询每个部门的员工的数量:
select dept.deptno, count(emp.deptno)
from dept
left join emp on dept.deptno = emp.deptno
group by dept.deptno;MySQL 子查询、多表查询
列出与lisi从事相同职位的所有员工,显示姓名、职位、部门编号:
select ename, epost, deptno
from emp
where epost = (
select epost from emp where ename = 'lisi'
);列出薪资比部门编号为30(销售部)的所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称:
-- 外连接查询:查询所有员工、员工薪资和员工对应的部门名称
select emp.ename, salary, dept.dname
from emp
left join dept on emp.deptno = dept.deptno;
-- 假设销售部门的最高薪资为 3000,列出薪资比 3000 高的员工信息
select emp.ename, salary, dept.dname
from emp
left join dept on emp.deptno = dept.deptno
where salary > 3000;
-- 求出销售部门的最高薪资
select max(salary) from emp where deptno = 30;
-- 合并两条查询 SQL
select emp.ename, salary, dept.dname
from emp
left join dept
on emp.deptno = dept.deptno
where salary > (
select max(salary) from emp where deptno = 30
);列出最低薪资大于6500的各种职位,显示职位和该职位的最低薪资:
select epost, min(salary)
from emp
group by epost
having min(salary) > 6500;having 子句
需要注意的是,在 group by 子句之后使用 having 子句可以对分组后的结果进行条件过滤,而在 where 子句中则不能使用聚合函数(如 min 函数)。
列出在每个部门就职的员工数量、平均薪资,显示部门编号、员工数量、平均薪资:
select deptno, count(*), AVG(salary)
from emp
group by deptno;列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资:
-- 查询 `emp` 表中所有员工的部门编号、姓名、薪资
select deptno, ename, salary from emp;
-- 查询 `emp` 表中每个部门的最高薪资,显示部门编号、最高薪资
select deptno, max(salary) from emp group by deptno;
-- 第二次查询的结果作为一张临时表和第一次查询进行关联查询
select emp.deptno, emp.ename, emp.salary
from emp,
(
select deptno, max(salary) maxsal
from emp
group by deptno
) t1
where t1.deptno = emp.deptno and emp.salary = t1.maxsal;MySQL 基础函数
MySQL 字符串函数
character_length(s):返回字符串长度concat(s1,s2,...,sn):字符串合并format(x,n):数字格式化(将数字x格式化为保留n位小数点)lpad(s1,len,s2):该函数用于在字符串s1的开始处填充字符串s2,使字符串长度达到len。field(s,s1,s2,…):该函数用于返回第一个字符串s在字符串列表(s1,s2,…)中的位置。insert(s1,x,len,s2):该函数用字符串s2替换字符串s1中从x位置开始长度为len的字符串。lcase(s):把字符串中的所有字母转换为小写字母。ucase(s):把字符串中的所有字母转换为大写字母。strcmp(s1,s2):比较字符串大小。该函数用于比较字符串s1和s2,如果s1与s2相等则返回0,如果s1>s2则返回1,如果s1<s2则返回‒1。replace(s,s1,s2):字符串替换。该函数用字符串s2替换字符串s中的字符串s1。position(s1 in s):获取子字符串s1在字符串s中出现的位置。md5(s):字符串加密。inet_aton(ip):把 IP 地址转换为数字。inet_ntoa (s):把数字转换为 IP 地址。
MySQL 数字函数
ceil(x):返回不小于x的最小整数。ceiling(x):返回不小于x的最小整数。同ceil(x)。floor(x):返回不大于x的最大整数。round(x):返回最接近x的整数。max(expression):求最大值。min(expression):求最小值。sum(expression):求总和。avg(expression):求平均值。count(expression):求总记录数。count(字段名):计算指定列下总的行数,计算时将忽略空值的行。count(*):计算数据表中总的行数,无论某列是否为空值都包含在内。
MySQL 日期函数
adddate(d,n):返回指定日期加上指定天数后的日期
/**
计算在2021-06-06的基础上加上60天后的日期
输出:2017-08-14
*/
select adddate("2017-06-15", 60);addtime(t,n):返回指定时间加上指定时间后的时间
/**
2021-06-06 23:23:10 加 8 秒
得到:2021-06-06 23:23:18
*/
select addtime("2021-06-06 23:23:10", 8);
/**
2021-06-06 23:23:10 加 1小时10分5秒
得到:2021-06-07 00:33:15
*/
select addtime("2021-06-06 23:23:10", "1:10:5");curdate():返回当前日期。格式为 YYYY-MM-DD
datediff(d1,d2):返回两个日期相隔的天数
dayofyear(d):返回指定日期是本年的第几天
extract(type from d):从日期 d 中返回 type 类型的值
type 的枚举值有:hour、minute、second、microsecond、year、month、day、week、quarter、year_month、day_hour、day_minute、day_second、hour_minute、hour_second、minute_second。
-- 得到 `11`
select extract (minute from "2021-06-06 23:11:11");now():返回当前日期和时间
-- 得到格式如:YYYY-MM-DD HH:mm:ss
select now();quarter(d):返回日期对应的季度数,范围是 1~4
second(t):返回指定时间中的秒数
timediff(time1, time2):计算时间差
-- 得到:`838:59:59`
select timediff("2021-06-06 16:42:45", "2020-06-06 16:42:45");date(t):从指定日期时间中提取日期值
-- 得到:`2021-06-16`
select date("2021-06-16 23:11:11");hour(t):返回指定时间中的小时数
time(expression):提取日期时间参数中的时间部分
-- 提取 `2021-06-06 16:42:45` 的时间部分
select time("2021-06-06 16:42:45");time_format(t,f):根据表达式显示时间
year(d):返回指定日期的年份
MySQL 高级查询函数
MySQL 高级函数
MySQL 窗口函数
MySQL 数据表分区
MySQL 目前仅支持使用 InnoDB 和 NDB 存储引擎对数据表进行分区,不支持其他存储引擎。
使用分区的优点有:
- 数据表被分区后,其中的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。
- 分区上的数据更容易维护。例如,想批量删除大量数据时,可以使用清楚整个分区的方式来处理。另外,还可以对一个独立分区进行优化、检查、修复等操作。
- 可以使用分区来避免某些特殊的瓶颈,例如 InnoDB 的单个索引的互斥访问。
- 在大数据集的应用场景下,可以备份和恢复独立的分区,这样能够更好地提高性能。
- 某些查询也可以被极大地优化,因为满足给定 where 子句的数据只能存储在一个或多个分区上,所以会自动搜索相关分区数据,而不是扫描所有的表数据。
- 由于在创建分区后可以更改分区,因此用户可以重新组织数据,提高查询效率。
MySQL 目前支持多种分区:
- 范围(range)分区:基于一个给定连续区间的列值,把区间列值对应的多行分配给分区。
- 列表(list)分区:类似范围分区,不同之处在于列表分区是根据列值域离散集合中的某个值的匹配来选择的。
- 列(column)分区:数据根据某个或多个列的值进行划分,是列表分区和范围分区的变体。
- 哈希(hash)分区:基于用户定义的表达式的返回值进行分区选择,该表达式使用将要插入表中的行的列值来进行计算。哈希函数可以包含在 MySQL 中有效且产生非负整数的表达式。
- 键(key)分区:类似哈希分区,区别在于键分区只支持计算一列或多列,并且 MySQL 服务器为此提供了自身的哈希函数。
- 子分区:又称复合分区,是对分区表中每个分区的进一步划分。
MySQL 范围分区
范围分区应该是连续且不重叠的,使用 value less than 运算符来定义。
创建表,并通过 partition by range 子句将表按 salary 列进行分区:
create table employees
(
empno varchar(20) not null,
empname varchar(20),
deptno int,
birthdate date,
salary int
)
partition by range(salary) (
partition p0 values less than (5000),
partition p1 values less than (10000),
partition p2 values less than (15000),
partition p3 values less than (20000),
partition p4 values less than maxvalue
);maxvalue表示是中大于最大可能得整数值。
当员工工资增长到 25000、30000 或更多时,可以使用 alter table 语句为 20000~25000 的工资范围添加新分区。
针对上面这个员工表,我们也可以根据员工的出生日期(birthdate)进行分区,把同一年出生的员工信息存储在同一个分区中,像下面这样(以 year(birthdate) 作为分区依据)。
create table employees
(
empno varchar(20) not null,
empname varchar(20),
deptno int,
birthdate date,
salary int
)
partition by range(year(birthdate) (
partition p2018 values less than (2018),
partition p2019 values less than (2019),
partition p2020 values less than (2020),
partition p2021 values less than (2021),
partition pmax values less than maxvalue
);查询每个分区中分配的数据量
select partition_name as "", table_rows as ""
from information_schema.partitions
where table_name="employees";得到结果格式如下:
| / | / |
|---|---|
| p0 | 0 |
| p1 | 1 |
| p2 | 1 |
| p3 | 1 |
| p4 | 0 |
MySQL 列表分区
create table employees_list
(
empno varchar(20) not null,
empname varchar(20),
deptno int,
birthdate date,
salary int
)
partition by list(deptno) (
partition p0 values in (10,20,30),
partition p1 values in (40,50,60),
partition p2 values in (70,80,90)
);在列表分区的方案中,如果插入的数据中分区字段的值不在分区列表中,则会报错:Table has no partition for value blabla。如果要在一条语句中批量添加多条数据,并忽略错误数据,可以使用 ignore 关键字:
insert ignore into employees_list (empno,empname,deptno,birthdate,salary)
values
(6, 'name1', 10, '2021-06-20', 12998),
(7, 'name2', 100, '2021-06-20', 12998);MySQL 列分区
列(column)分区是范围分区和列表分区的变体,分为范围列(range column)分区和列表列(list column)分区。
范围列分区
create table rtable(
a int,
b int,
c char(8),
d int
)
partition by range columns(a,d,c) (
partition p0 values less than (5,20,'aa'),
partition p1 values less than (10,30,'cc'),
partition p2 values less than (15,80,'dd'),
partition p3 values less than (maxvalue,maxvalue,maxvalue)
);列表列分区
create table customers (
name varchar(25),
street_1 varchar(30),
street_2 varchar(30),
city varchar(15),
renewal date
)
partition by list columns(city) (
partition pregion_1 values in('河南省', '湖北省', '湖南省'),
partition pregion_2 values in('广东省', '广西壮族自治区', '海南省'),
partition pregion_3 values in('上海市', '江苏省', '浙江省'),
partition pregion_4 values in('北京市', '天津市', '河北省')
);MySQL 哈希分区
常规哈希分区
要对表进行哈希分区,必须在 create table 语句后附加一个子句,这个子句可以是一个返回整数的表达式,也可以是 MySQL 整数类型列的名称。
根据表中 store_id 列进行哈希分区,并分为4个分区,示例 SQL 语句如下:
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int,
store_id int
)
partition by hash(store_id)
partitions 4;如果分区不包含 partition 子句,则分区数默认为1;如果分区语句包含 partition 子句,则必须在后面指定分区的数量,否则会提示语法错误。
哈希分区中,还可以使用为 SQL 返回整数的表达式,比如:
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int,
store_id int
)
partition by hash( year(hired) )
partitions 4;线性哈希分区
MySQL 还支持线性哈希,它与常规哈希的不同之处在于:线性哈希使用线性二次幂算法,二常规哈希使用哈希函数值的模数。在语法上,线性哈希分区唯一区别于常规哈希的地方是在 partition by 子句中添加了 linear 关键字。
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int,
store_id int
)
partition by linear hash( year(hired) )
partitions 4;MySQL 键分区
键分区将表中的数据按照特定的键值进行分区。在键分区中,每个分区都包含相同键值的数据,不同键值的数据则存储在不同的分区中。
键分区和哈希分区很像,但有区别:
- 键分区支持除 text 和 blob 类型之外的所有数据类型的列,而哈希分区只支持数字类型的列;
- 键分区不允许使用用户自定义的表达式进行分区,而是使用系统提供的哈希函数进行分区。
当表中存在主键或唯一键时,如果创建键分区时没有指定列,则系统默认会选择主键列作为分区列;如果不存在主键列,则会选择非空的唯一键列作为分区列。
提示
唯一列作为分区列时,唯一列不能为 null。
create table tb_key (
id int,
var char(32)
)
partition by key(var)
partitions 10;MySQL 子分区
子分区也称复合分区,是对分区表中的每个分区的进一步划分,分为:
- 范围-哈希复合分区。
- 范围-键复合分区。
- 列表-哈希复合分区。
- 列表-键复合分区。
范围-哈希(range-hash)复合分区
create table emp(
empno varchar(20) not null,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by range(salary)
subpartition by hash(year(birthdate))
subpartitions 3(
partition p1 values less than (2000),
partition p2 values less than maxvalue
);在上面这个例子中,先按 salary 列的薪资范围将表进行分区,并对 birthdate 列采用 year 进行哈希分区,子分区数为3。在此分区方案中,将数据分成了两个范围分区 p1 和 p2,每个范围分区又分为3个子分区,其中 p1 分区存储 salary 小于 2000 的数据,p2 分区存储所有大于或等于 2000 的数据。
范围-键(range-key)复合分区
create table emp(
empno varchar(20) not null,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by range(salary)
subpartition by key(birthdate)
subpartitions 3
(
partition p1 values less than (2000),
partition p2 values less than maxvalue
);列表-哈希(list-hash)复合分区
create table emp(
empno varchar(20) not null,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by list (deptno)
subpartition by hash(year(birthdate))
subpartitions 3
(
partition p1 values in (10),
partition p2 values in (20),
);列表-键(list-key)复合分区
create table emp(
empno varchar(20) not null,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by list (deptno)
subpartition by key(birthdate)
subpartitions 3
(
partition p1 values in (10),
partition p2 values in (20)
);MySQL 分区对 null 的处理
MySQL 中的分区不会禁止 null 作为分区表达式的值,无论列值还是用户提供的表达式的值,都允许 null 用作必须产生整数的表达式的值。MySQL 中的分区将 null 视为小于任何非 null 值。
范围分区中如何处理 null
要将一行数据插入分区中,如果用于确定范围分区的列值为 null,那么该行将插入最低分区中。
列表分区中如何处理 null
当且仅当定义的分区中存在分区其 values in 后跟的值列表中存在 null 值时,才允许 null 值插入该分区。
create table ts2 (
c1 int,
c2 varchar(20)
)
partition by list(c1) (
partition p0 values in (0, 3, 6),
partition p1 values in (1, 4, 7),
partition p2 values in (2, 5, 8),
partition p3 values in (null)
);哈希分区和健分区中如何处理 null
在哈希分区和键分区的表中,任何产生 null 值的分区表达式的返回值都为 0。
范围分区和列表分区的管理
删除分区
# 删除分区
alter table table_name drop partition partition_name;添加分区(范围分区)
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
hired DATE NOT NULL
)
PARTITION BY RANGE( YEAR(hired) ) (
PARTITION p1 VALUES LESS THAN (1991),
PARTITION p2 VALUES LESS THAN (1996),
PARTITION p3 VALUES LESS THAN (2001),
PARTITION p4 VALUES LESS THAN (2005)
);
# 如果要新增的分区的范围值大于之前已有的分区范围值,可以直接添加:
ALTER TABLE employees ADD PARTITION (
PARTITION p5 VALUES LESS THAN (2010),
PARTITION p6 VALUES LESS THAN MAXVALUE
);
# 否则需要像下面这样处理:
ALTER TABLE employees
REORGANIZE PARTITION p1 INTO (
PARTITION n0 VALUES LESS THAN (1970),
PARTITION n1 VALUES LESS THAN (1991)
);
# 如果要对上面的操作反向处理:
ALTER TABLE employees REORGANIZE PARTITION n0,n1 INTO (
PARTITION p1 VALUES LESS THAN (1991)
);添加分区(列表分区)
CREATE TABLE tt (
id INT,
data INT
)
PARTITION BY LIST(data) (
PARTITION p0 VALUES IN (5, 10, 15),
PARTITION p1 VALUES IN (6, 12, 18)
);
# 如果新增的分区的范围值大于之前已有分区的范围值,可以直接添加:
ALTER TABLE tt ADD PARTITION (
PARTITION p2 VALUES IN (7, 14, 21)
);拆分、合并分区
在保证数据不丢失的情况下,可以拆分、合并分区:
create table members (
id int(11) default null,
fname varchar(25) default null,
lname varchar(25) default null,
dob date default null
) engine=InnoDB default charset=latin1
partition by range (year(dob))
(
partition n0 values less than (1970) engine = InnoDB,
partition n1 values less than (1980) engine = InnoDB,
partition p1 values less than (1990) engine = InnoDB,
partition p2 values less than (2000) engine = InnoDB,
partition p3 values less than (2010) engine = InnoDB
);
# 把 n0 分区拆分成2个分区:s0、s1
alter table members reorganize partition n0 into (
partition s0 values less than (1960),
partition s1 values less than (1970)
);
# 把 s0、s1 分区合并成一个分区
alter table members reorganize s0, s1 into (
partition p0 values less than (1970)
);dob是出生日期(date of birth)的缩写。
哈希分区和键分区的管理
哈希分区
# 创建一张具有10个哈希分区的数据表
create table clients (
id int,
fname varchar(30),
lname varchar(30),
signed date
)
partition by hash( month(signed) )
partitions 10;
# 把分区数量从 10 个变成 6 个 (即,合并掉 4 个分区)
alter table clients coalesce partition 4;coalesce partition
需要注意,coalesce partition 后面的数字表示要删除的分区数。
键分区
# 创建一张具有 10 个键分区的表
create table clients (
id int,
fname varchar(30),
lname varchar(30),
signed date
)
partition by linear key(signed)
partitions 10;
# 把键分区数量从 10 个变成 6 个
alter table clients coalesce partition 4;分区管理和维护操作
删除分区(仅限于范围分区和列表分区,会丢失数据)
# 一次性删除一个分区
alter table emp drop partition p1;
# 一次性删除多个分区
alter table emp drop partition p1,p2;增加分区
# 增加范围分区
alter table emp add partition (partition p3 values less than (5000));
# 增加列表分区
alter table emp add partition (partition p3 values in (5000));分解分区(不会丢失数据)
reorganize partition 关键字可以对表的部分分区或全部分区进行修改,并且不会丢失数据。分解前后分区的整体范围应该一致。
alter table t
reorganize partition p1 into
(
partition p1 values less than (1000),
partition p3 values less than (2000)
);合并分区(不会丢失数据)
随着分区数量的增多,有时需要把多个分区合并成一个分区,可以使用 into 指令实现。
alter table t
reorganize partition p1,p3 into
(partition p1 values less than (10000));重新定义哈希分区(不会丢失数据)
想要对哈希分区进行扩容或缩容,可以对现有的哈希分区进行重新定义。
alter table t partition by hash(salary) partitions 8;重新定义范围分区(不会丢失数据)
想要对范围分区进行扩容或缩容,可以对现有范围分区进行重新定义。
alter table t partition by range(salary)
(
partition p1 values less than (20000),
partition p2 values less than (30000)
);删除表的所有分区(不会丢失数据)
如果要删除表的所有分区,但又不想删除数据,可以执行如下语句:
# 注意是 `partitioning`,不是 `partition`
alter table emp remove partitioning;重建分区
这和先删除保存在分区中的所有记录,然后重新插入它们具有同样的效果,可用于整理分区碎片。
alter table emp rebuild partition p1,p2;优化分区
如果从分区中删除了大量的行,或者对一个带有可变长度的行做了许多修改,那么可以使用 alter table ... optimize partition 来收回没有使用的空间,并整理分区数据文件的碎片。
alter table t optimize partition p1,p2;分析分区
想要对现有的分区进行分析,可以执行如下语句:
-- 读取并保存分区的键分布
alter table t analyze partition p1,p2;修补分区
-- 修补被破坏的分区
alter table t repairpartition p1,p2;检查分区
想要查看现有的分区是否被破坏,可以执行如下语句:
-- 检查表指定的分区
alter table t check partition p1,p2;这条语句可以告诉我们表 t 的分区 p1、p2 中的数据或索引个是否已经被破坏了。如果分区被破坏了,那么可以使用 alter table ... repairpartition 来修补该分区。
分区的限制
在业务中可以对分区进行一些限制:
- 分区键必须包含在表的主键、唯一键中。
- MySQL 只能在使用分区函数的列进行比较时才能筛选分区,而不能根据表达式的值去筛选分区,即使这个表达式就是分区函数也不行。
- 不使用NDB存储引擎的数据表的最大分区数为8192。
- InnoDB存储引擎的分区不支持外键。
- 服务器 SQL 模式(可以通过 SQL-MODE 参数进行配置)影响分区表的同步复制。主节点和从节点上不同的SQL模式可能会导致相同的数据存储在主从节点的不同分区中,甚至可能导致数据插入主节点成功,而插入从节点失败。为了获得最佳效果,应该始终在主机和从机上使用相同的服务器SQL模式,强烈建议不要在创建分区后更改服务器SQL模式。
- 分区不支持全文索引,即使是使用 InnoDB 或 MyISAM 存储引擎的分区也不例外。
- 分区无法使用外键约束。
- 临时表不能进行分区。
分区键和主键、唯一键的关系
控制分区键与主键、唯一键关系的规则是:分区表达式中使用的所有列必须是该数据表可能具有的每个唯一键的一部分。换句话说,分区键必须包含在表的主键、唯一键中。
错误示例
唯一键是 col1 和 col2 的组合,分区键是 col3
create table t1 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
unique key (col1, col2)
)
partition by hash(col3)
partitions 4;
-- 报错如下:
# ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's
# partitioning function (prefixed columns are not considered).两个唯一键分别是 col1 和 col3,分区键是 col1 + col3
create table t2 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
unique key (col1),
unique key (col3)
)
partition by hash(col1 + col3)
partitions 4;
-- 报错如下:
# ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's
# partitioning function (prefixed columns are not considered).两个唯一键分别是 (col1, col2) 和 col3,分区键是 col1 + col3
create table t3 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
unique key (col1, col2),
unique key (col3)
)
partition by hash(col1 + col3)
partitions 4;
-- 报错如下:
# ERROR 1491 (HY000): A PRIMARY KEY must include all columns in the table's
# partitioning function.主键是 col1 和 col2,分区键是 col3
create table t4 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
primary key(col1, col2)
)
partition by hash(col3)
partitions 4;
-- 报错如下:
# ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's
# partitioning function (prefixed columns are not considered).主键是 col1 和 col3,唯一键为 col2,分区键为 year(col2)
create table t5 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
primary key(col1, col3),
unique key(col2)
)
partition by hash( year(col2) )
partitions 4;
-- 报错如下:
# ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's
# partitioning function (prefixed columns are not considered).正确示例
create table t1 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
unique key (col1, col2, col3)
)
partition by hash(col3)
partitions 4;create table t2 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
unique key (col1, col3)
)
partition by hash(col1 + col3)
partitions 4;create table t3 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
unique key (col1, col2, col3),
unique key (col3)
)
partition by hash(col3)
partitions 4;以下两种情况,主键都不包括分区表达式中引用的所有列,但语句都是有效的
create table t4 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
primary key(col1, col2)
)
partition by hash(col1 + year(col2))
partitions 4;create table t5 (
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
primary key (col1, col2, col4),
unique key (col2, col1)
)
partition by hash(col1 + year(col2))
partitions 4;MySQL 视图、存储过程
MySQL 数据查询优化
MySQL 索引
InnoDB 存储引擎实物模型和锁的使用
InnoDB 是一种兼顾高可靠性和高性能的通用存储引擎。在 MySQL 8.0 中,InnoDB 是默认的 MySQL 存储引擎。InnoDB 存储引擎主要有以下优势:
- DML 操作遵循 ACID(事务)模型,事务具有提交、回滚和崩溃恢复功能,以保护用户数据。
- 行级锁定和 Oracle 风格一致的读取方式提高了多用户并发性和性能。
- InnoDB 表根据主键优化查询。每张 InnoDB 表都有一个称为聚簇索引的主键索引,该索引用于最小化 I/O 查询。
- 为了维护数据的完整性,InnoDB 支持外键约束。使用外键检查插入、更新和删除操作,以确保这些操作不会导致相关表数据之间的不一致。
InnoDB 的优点有:
- 如果服务器由于硬件或软件问题而意外退出,那么无论当时数据库中发生了什么,我们在重新启动数据库后都不需要执行任何特殊操作。InnoDB具备崩溃恢复功能,它会自动完成在崩溃之前提交的所有更改,并撤销正在进行但未提交的更改,使得在重新启动后可以从上次中断的地方继续进行后续操作。
- InnoDB存储引擎维护自己的缓冲池,把经常使用的数据存放在内存中,用于主内存缓存表和索引数据的查询。在专用数据库的服务器上,多达80%的物理内存通常分配给缓冲池。
- InnoDB存储引擎的表支持外键。
- InnoDB存储引擎的校验机制可以检测到磁盘或内存中的数据损坏。
- 当为数据库的表设置主键列时,系统会自动优化主键列,在where子句、order by子句、group by子句和连接操作中提高主键的使用效率。
- InnoDB存储引擎不仅允许对同一张表进行并发读写访问,它还缓存更改的数据以减少对磁盘的I/O操作。
- 当从表中重复访问相同的行数据时,自适应哈希索引会接管这些数据,以提高查询效率。
- 可以压缩表和索引数据,以及加密表数据。
- 支持在线DDL操作。
- 支持通过查询
information_schema表来监控存储引擎的内部工作。 - 支持通过查询
performance_schema表来监控存储引擎性能的详细信息。 - 将
InnoDB表与来自其他MySQL存储引擎的表混合使用。 - InnoDB存储引擎提高了处理大量数据时的CPU效率。
- InnoDB存储引擎即使在文件大小限制为2GB的操作系统上也可以操作大数据量的表。
InnoDB 存储引擎实践
使用InnoDB存储引擎时的推荐做法:
- 在查询时最好根据主键查询,如果没有主键,可以指定一个自增值作为主键。
- 在使用连接查询时,最好在连接列上定义外键,而且表中的连接列使用相同的数据类型声明,这样可以提高查询性能。外键还会将删除和更新操作传播到所有受影响的表中,并在父表中不存在相应id时阻止在子表中插入数据,从而保证数据的完整性。
- 关闭自动提交。每秒提交数百次会限制服务性能,可以执行“set autocommit=0;”进行关闭。
- 通过用start transaction和commit语句将相关的DML操作集分组到事务中。
- 不要使用lock tables语句。InnoDB存储引擎允许多个会话同时对同一张表进行读取和写入,而不会影响可靠性和高性能。如果需要获得对一行数据的独占写访问权限,可以使用select … for update语法锁定待更新的行。
- 启用innodb_file_per_table变量或使用通用表空间将表内的数据和索引放入单独的文件中。innodb_file_per_table默认情况下为启用状态。
- 可以在InnoDB存储引擎不牺牲读写能力的情况下压缩表。
- 为了防止启用用户不想使用的存储引擎来创建表,可以使用
sql_mode=no_engine_substitution选项来运行服务器。
如果想要知道当前服务器的默认存储引擎,则可以使用下面的SQL语句来查看:
show engines;InnoDB和ACID模型
ACID(事务)模型是一组数据库设计原则,是业务数据和关键任务应用的可靠性保证。在MySQL中,InnoDB存储引擎是严格遵守ACID模型的存储引擎,因此数据不会损坏,执行数据的结果不会因软件崩溃或硬件故障等异常情况而失真。当数据本身符合ACID的特性时,应用程序不需要重新发明一致性检查和崩溃恢复机制的轮子。如果有额外的软件保护措施、超可靠的硬件或可以容忍少量数据丢失的应用程序,则可以调整MySQL设置以获得更高的性能或吞吐量。下面我们将介绍InnoDB存储引擎的ACID模型。
MySQL事务主要用于处理操作量大、复杂度高的数据。比如,在人员管理系统中删除一个人员,既要删除人员的基本资料,又要删除和该人员相关的信息,如信箱、文章等,如果其中有一项没有删除成功,则其他内容也不能被删除。这样,这些数据库操作语句就构成了一个事务。
一般来说,事务必须满足4个条件(ACID):原子性(Atomicity,或称为不可分割性)、一致性(Consistency)、隔离性(Isolation,又称为独立性)、持久性(Durability)。
原子性:一个事务中的所有操作可以全部完成或全部失败,但不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。如图14-2所示,用户A给用户B转账1000,A账户减去1000,B账户加上1000,这个操作是一个原子操作,是不可分割的。如果同时成功,则数据库中A账户减去1000,B账户加上1000;如果同时失败,则操作回滚,数据库中的数据不变。
一致性:在事务开始之前和事务结束以后,数据库的完整性不会被破坏。这表示写入的数据必须完全符合所有的预设规则,包含数据的精确度、串联性,以及后续数据库可以自发性地完成预定的工作。
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据不一致。事务隔离分为不同级别,包括未提交读(read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(serializable)。
持久性:事务处理结束后,对数据的修改就是永久的,即使系统故障也不会丢失。
手动提交
在MySQL命令行的默认设置下,事务都是自动提交的,即执行SQL语句后就会马上执行commit操作。因此,要显式地开启一个事务需要使用命令 begin 或 start transaction,或者执行命令 set autocommit=0 来禁用当前会话的自动提交。
用 begin rollback commit 实现
- begin:开始一个事务。
- rollback:事务回滚。
- commit:事务确认。
直接用 set 来改变 MySQL 的自动提交模式
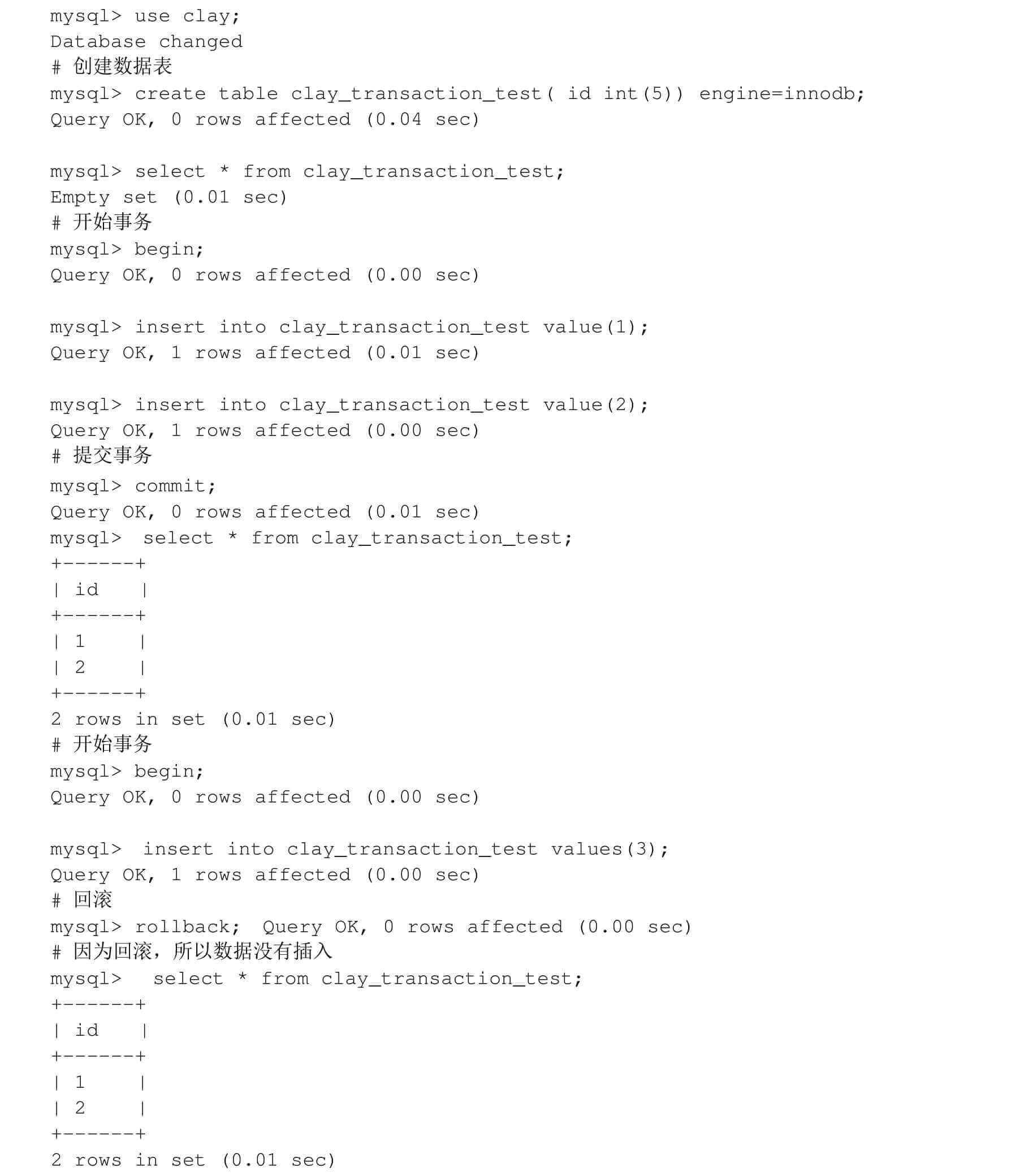
锁机制
数据是一种供许多用户共享访问的资源,如何保证数据库并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁的冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对于数据库而言就显得尤为重要。MySQL中的锁可以按照不同的维度进行分类,以下是常见的几种锁:
按照粒度分类:
- 表级锁:锁住整张表,其他会话不能对特定行进行修改。
- 行级锁:在某些情况下,MySQL会将锁的粒度进行缩小,锁住某几行。行级锁比表级锁更细粒度,其他会话仍然可以修改表中其他行。
按照类型分类:
- 共享锁(S锁或者读锁):多个会话可以同时对同一份数据对象进行共享锁定,读取数据对象的操作都是可行的,但写入数据对象的操作则会被阻塞。
- 排他锁(X锁或者写锁):只有一个会话可以对一个数据对象进行排他锁定,其他会话不能进行读取或者写入数据对象的操作,只能等待排他锁被释放。
- 意向锁:用于在同一个事务的行级锁和表级锁之间进行转换和协调,降低锁定的粒度并提高并发性能。
- 乐观锁:假定并发操作之间没有冲突,不会阻塞数据读写操作,只在提交数据时进行数据版本的校验和冲突检测,如果存在冲突则回滚操作。
- 悲观锁:默认并发操作之间存在冲突,通过锁机制保护数据对象的完整性,会降低并发性能。
- 间隙锁:锁住一个数据对象前后的间隔区域以避免幻读问题。
- 记录锁:锁住某个或某些行,但是不包含间隙。
- 临建锁:锁住临时表,例如MySQL的 temporary table。
- 死锁:两个或多个事务互相需要对方占有的资源而陷入的循环等待状态。
幻读和不可重复读
事务A 按照一定条件进行数据读取, 期间事务B 插入了相同搜索条件的新数据,事务A再次按照原先条件进行读取时,发现了事务B 新插入的数据 称为幻读。
如果事务A 按一定条件搜索, 期间事务B 删除了符合条件的某一条数据,导致事务A 再次读取时数据少了一条。这种情况归为 不可重复读。
MySQL 数据运维和读写分离架构
基准测试
基准测试可以理解为针对系统的一种压力测试。基准测试不关心业务逻辑,更加简单、直接,易于测试,数据可以由工具生成,不要求真实;而压力测试一般考虑业务逻辑,要求真实的数据。
对于大多数Web应用来说,整个系统的瓶颈在于数据库,原因很简单:Web应用中的其他因素(例如网络带宽、负载均衡节点、应用服务器(包括CPU、内存、硬盘灯、连接数等)、缓存)都很容易通过增加机器水平的扩展来实现性能的提高。而对于MySQL,由于数据一致性的要求,无法通过增加机器来分散向数据库写数据带来的压力,虽然可以通过读写分离、分库、分表来减轻压力,但是与系统其他组件的水平扩展相比,数据库仍然受到了太多的限制。
对数据库进行基准测试的作用是分析在当前配置(硬件配置、操作系统配置、数据库配置等)下,其数据库的性能表现,从而找出MySQL的性能阈值,并根据实际系统的要求调整配置。基准测试的指标有如下几个:
- 每秒查询数(Query Per Second,QPS):是对一个特定的查询服务器在规定时间内处理查询数量的衡量标准,对应fetches/sec,即每秒的响应请求数。
- 每秒处理的事务数(Transaction Per Second,TPS):是指系统在单位时间内处理事务的数量。对于非并发的应用系统而言,TPS与响应时间呈反比关系,实际上此时TPS就是响应时间的倒数。前面已经讲过,对于单用户的系统,响应时间(或者系统响应时间和应用延迟时间)可以很好地度量系统的性能,但对于并发系统而言,通常需要用TPS作为性能指标。
- 响应时间:包括平均响应时间、最小响应时间、最大响应时间、时间百分比等,其中时间百分比参考意义较大,如前90%的请求的最大响应时间。
- 并发量:同时处理的查询请求的数量,即可以同时承载的正常业务功能的请求数量。
在对MySQL进行基准测试时,一般使用专门的工具,例如MySQLslap、Sysbench等。其中,Sysbench比MySQLslap更通用、更强大。
Sysbench是一个开源的、模块化的、跨平台的多线程性能测试工具,可以用来进行CPU、内存、磁盘I/O、线程、数据库的性能测试。目前支持的数据库有MySQL、Oracle和PostgreSQL。它主要包括以下几种测试:
- CPU性能。
- 磁盘I/O性能。
- 调度程序性能。
- 内存分配及传输速度。
- 数据库性能基准测试。
读写分离
随着应用业务数据的不断增多,程序应用的响应速度会不断下降,在检测过程中不难发现大多数的请求都是查询操作。此时,我们可以将数据库扩展成主从复制模式,将读操作和写操作分离开来,多台数据库分摊请求,从而减少单库的访问压力,进而使应用得到优化。
读写分离的基本原理是让主数据库处理对数据的增、改、删操作,进而让从数据库处理查询操作。数据库复制用来把事务性操作导致的变更同步到集群的从数据库中。由于数据库的操作比较耗时,因此让主服务器处理写操作以及实时性要求比较高的读操作,而让从服务器处理读操作。读写分离能提高性能的原因在于主、从服务器负责各自的读和写,极大地缓解了锁的争用,其架构图如下图所示。
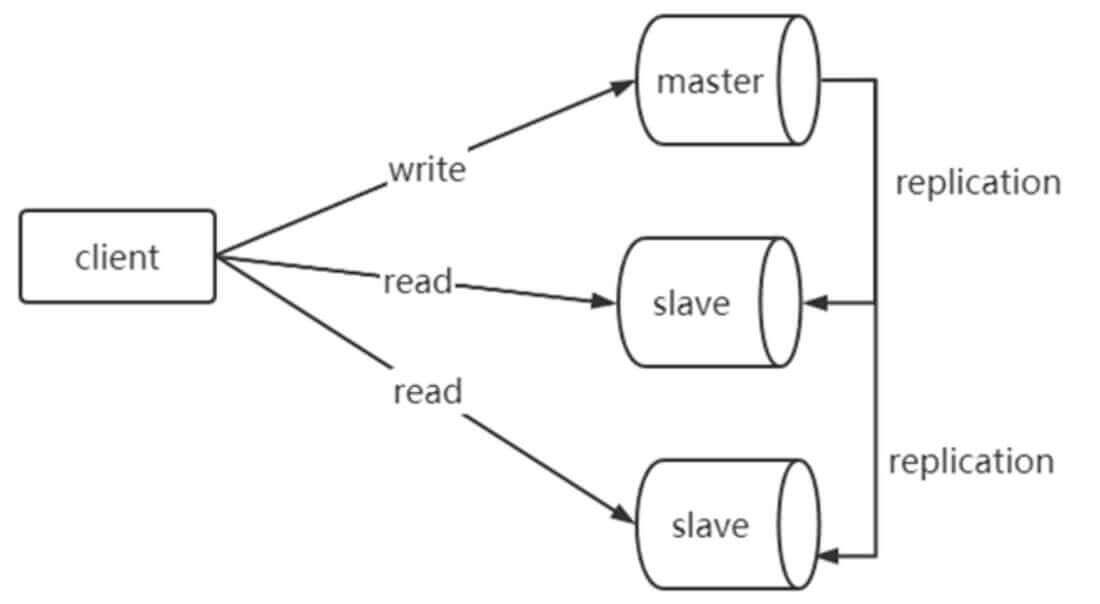
上图所示架构有一个主库与两个从库:主库负责写数据,从库复制读数据。随着业务发展,如果还想增加从节点来提升读性能,那么可以随时进行扩展。
数据库备份
mysqldump是MySQL用于转存数据库的实用程序。它主要产生一个SQL脚本,其中包含从头重新创建数据库所必需的命令 create table insert 等。
要使用mysqldump导出数据,需要使用 --tab 选项来指定导出文件存储的目录,该目录必须有写操作权限。
备份 demo 数据库下的 userinfo 数据表
# 到 /tmp 目录下查看,该目录下会多出一个 userinfo.sql 文件
mysqldump -uroot -p123456 --no-create-info --tab=/tmp demo userinfo备份数据库
语法:
mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql单库备份:
mysqldump -uroot -p123456 db1 > db1.sql
mysqldump -uroot -p123456 db1 table1 table2 > db1-table1-table2.sql多库备份:
mysqldump -uroot -p123456 --databases db1 db2 mysql db3 > db1_db2_mysql_db3.sql备份所有库:
mysqldump -uroot -p123456 --all-databases > all.sql数据库还原
利用 source 命令导入数据库
需要先登录数据库终端。
-- 创建数据库
create database demo;
-- 使用已创建的数据库
use demo;
-- 设置编码
set names utf8;
-- 导入备份数据库
source /home/data/userinfo.sql;使用 load data infile 导入数据
MySQL提供了load data infile语句来插入数据。
LOAD DATA LOCAL INFILE 'dump.txt' INTO TABLE mytbl;使用 mysqlimport 导入数据
mysqlimport -u root -p --local mytbl dump.txtMySQL 主从复制
如果需要使用MySQL服务器提供读写分离支持,则需要MySQL的一主多从架构。在一主多从的数据库体系中,多个从服务器采用异步的方式更新主数据库的变化,业务服务器执行写操作或者相关修改数据库的操作直接在主服务器上执行,读操作在各从服务器上执行。MySQL主从复制实现原理如下图所示。
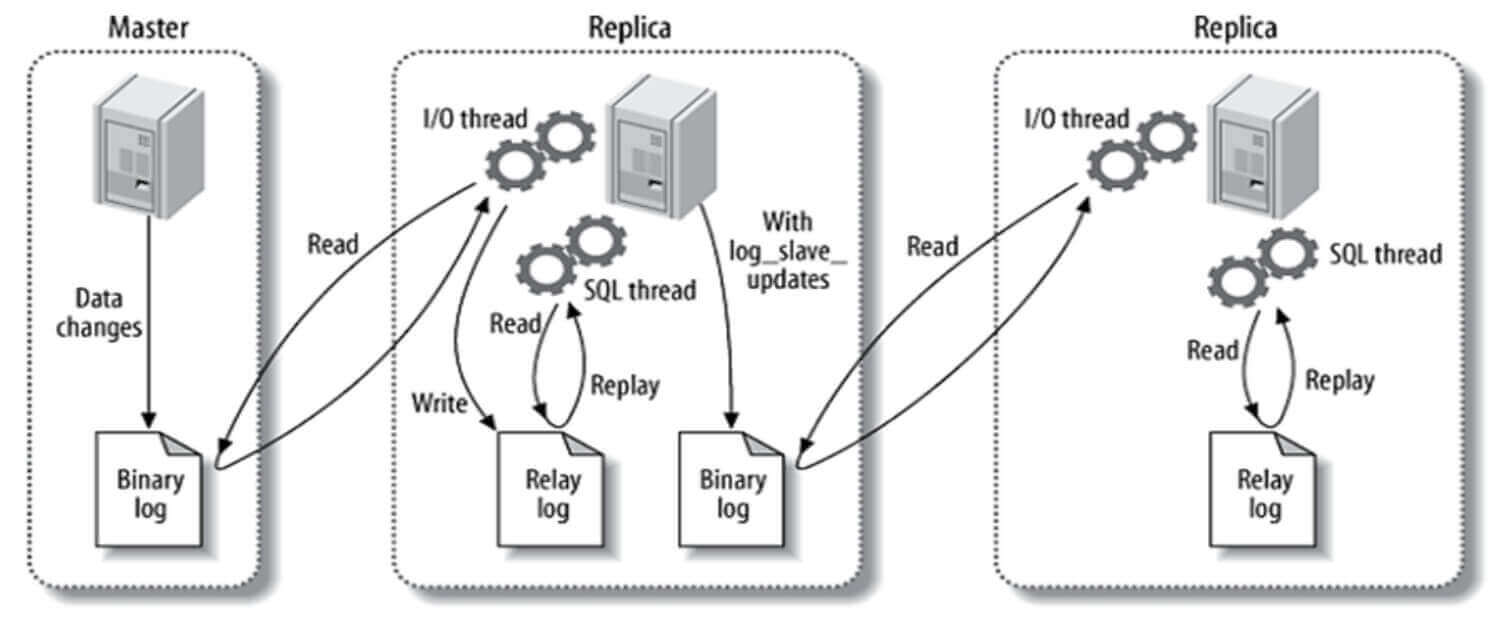
上图所示是典型的MySQL一主二从的架构图,其中主要涉及3个线程:binlog线程、I/O线程和SQL线程。每个线程说明如下:
- binlog线程:负责将主服务器上的数据更改写入二进制日志中。
- I/O线程:负责从主服务器上读取二进制日志,并写入从服务器的中继日志中。- SQL线程:负责读取中继日志并重放其中的SQL语句。
MySQL服务之间数据复制的基础是二进制日志文件。一个MySQL数据库一旦启用二进制日志后,其作为主服务器,它的数据库中所有操作都会以“事件”的方式记录在二进制日志中,其他数据库作为从服务器,通过一个I/O线程与主服务器保持通信,并监控主服务器的二进制日志文件的变化。如果发现主服务器的二进制日志文件发生变化,则会把变化复制到自己的中继日志中,然后从服务器的一个SQL线程把相关的“事件”触发操作在自己的数据库中执行,以此实现从数据库和主数据库的一致性,也就实现了主从复制。
Python
变量
在程序中可随时修改变量的值,而Python将始终记录变量的最新值。
message = "Hello Python world!"
print(message)
message = "Hello Python Crash Course world!""
print(message)以上代码将输出:
Hello Python world!
Hello Python Crash Course world!变量的命令
- 变量名只能包含字母、数字和下划线。变量名能以字母或下划线打头,但不能以数字打头。
- 变量名不能包含空格,但能使用下划线来分隔其中的单词。
- 不要将Python关键字和函数名用作变量名,即不要使用Python保留用于特殊用途的单词,如print。
- 变量名应既简短又具有描述性。
- 变量名应既简短又具有描述性。
- 要创建良好的变量名,需要经过一定的实践,在程序复杂而有趣时尤其如此。
字符串
字符串就是一系列字符。在Python中,用引号括起的都是字符串,其中的引号可以是单引号,也可以是双引号,如下所示:
"This is a string."
'This is also a string.'方法title()以首字母大写的方式显示每个单词,即将每个单词的首字母都改为大写。
name = "Ada Lovelace"
print(name.upper())
print(name.lower())可以用下面的放假将字符串全部转大写或小写:
name = "Ada Lovelace"
print(name.upper())
print(name.lower())
# 输出内容如下
# ADA LOVELACE
# ada lovelace在字符串中使用变量。
first_name = "ada"
last_name = "lovelace"
full_name = f"{first_name} {last_name}"
print(full_name)format() 方法
f字符串是Python 3.6引入的。如果你使用的是Python 3.5或更早的版本,需要使用format()方法,而非这种f语法。要使用方法format(),可在圆括号内列出要在字符串中使用的变量。对于每个变量,都通过一对花括号来引用。这样将按顺序将这些花括号替换为圆括号内列出的变量的值,如下所示:
要在字符串中添加制表符,可使用字符组合 \t。
>>>print("Python")
Python
>>>print("\tPython")
Python要在字符串中添加换行符,可使用字符组合\n:
>>>print("Languages:\nPython\nC\nJavaScript")
Languages:
Python
C
JavaScript删除字符串右边的空白可以用 rstrip,删除左边的空白可以用 lstrip(),同时删除两边的空白可以用 strip():
favorite_language = 'python '
favorite_language.rstrip()数
整数
可对整数执行加(+)、减(-)、乘(*)、除(/)运算。
使用两个乘号表示乘方运算:
# 3^2 => 9
3 ** 2
# 10^6 = 1000000
10 ** 6浮点数
Python 将所有带小数点的数称为浮点数。但需要注意的是,结果包含的小数位数可能是不确定的:
# 得到 0.30000000000000004
0.2 + 0.1所有语言都存在这种问题,没有什么可担心的。
整数和浮点数
将任意两个数相除时,结果总是浮点数,即便这两个数都是整数且能整除:
# 得到 2.0
4 / 2在其他任何运算中,如果一个操作数是整数,另一个操作数是浮点数,结果也总是浮点数。
无论是哪种运算,只要有操作数是浮点数,Python默认得到的总是浮点数,即便结果原本为整数也是如此。
数中的下划线
书写很大的数时,可使用下划线将其中的数字分组,使其更清晰易读(Python 3.6开始支持):
universe_age = 14_000_000_000当你打印这种使用下划线定义的数时,Python不会打印其中的下划线:
print(universe_age)
# 得到 14000000000同时给多个变量赋值
可在一行代码中给多个变量赋值,这有助于缩短程序并提高其可读性。这种做法最常用于将一系列数赋给一组变量。
常量
常量类似于变量,但其值在程序的整个生命周期内保持不变。Python没有内置的常量类型,但Python程序员会使用全大写来指出应将某个变量视为常量,其值应始终不变。
注释
在Python中,注释用井号(#)标识。井号后面的内容都会被Python解释器忽略。
Python之禅
在控制台执行 import this,可以看到全文:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!列表
在Python中,用方括号([])表示列表,并用逗号分隔其中的元素。如果让Python将列表打印出来,Python将打印列表的内部表示,包括方括号:[插图]
bicycles = ['trek','cannondale','redline','specialized']
# 输出:['trek','cannondale','redline','specialized']
print(bicycles)Python为访问最后一个列表元素提供了一种特殊语法。通过将索引指定为-1,可让Python返回最后一个列表元素:
bicycles = ['trek','cannondale','redline','specialized']
print(bicycles[-1])这种约定也适用于其他负数索引。例如,索引-2返回倒数第二个列表元素,索引-3返回倒数第三个列表元素,依此类推。
bicycles = ['trek','cannondale','redline','specialized']
message = f"My first bicycle was a {bicycles[0].title()}."
# 输出内容为:My first bicycle was a Trek.
print(message)要修改列表元素,可指定列表名和要修改的元素的索引,再指定该元素的新值。
motorcycles = ['honda','yamaha','suzuki']
motorcycles[0] = 'ducati'
print(motorcycles)在列表中添加新元素时,最简单的方式是将元素附加(append)到列表。给列表附加元素时,它将添加到列表末尾。
motorcycles = ['honda','yamaha','suzuki']
print(motorcycles)
motorcycles.append('ducati')使用方法 insert() 可在列表的任何位置添加新元素。为此,你需要指定新元素的索引和值。
motorcycles = ['honda','yamaha','suzuki']
motorcycles.insert(0,'ducati')
# ['ducati','honda','yamaha','suzuki']
print(motorcycles)如果知道要删除的元素在列表中的位置,可使用del语句。
motorcycles = ['honda','yamaha','suzuki']
print(motorcycles)
del motorcycles[0]
print(motorcycles)方法pop()删除列表末尾的元素,并让你能够接着使用它。术语弹出(pop)源自这样的类比:列表就像一个栈,而删除列表末尾的元素相当于弹出栈顶元素。
motorcycles = ['honda','yamaha','suzuki']
popped_motorcycle = motorcycles.pop()
# ['honda','yamaha']
print(motorcycles)
# suzuki
print(popped_motorcycle)实际上,可以使用pop()来删除列表中任意位置的元素,只需在圆括号中指定要删除元素的索引即可。
motorcycles = ['honda','yamaha','suzuki']
first_owned = motorcycles.pop(0)
# The first motorcycle I owned was a Honda.
print(f"The first motorcycle I owned was a {first_owned.title()}.")如果你不确定该使用del语句还是pop()方法,下面是一个简单的判断标准:如果你要从列表中删除一个元素,且不再以任何方式使用它,就使用del语句;如果你要在删除元素后还能继续使用它,就使用方法pop()。
有时候,你不知道要从列表中删除的值所处的位置。如果只知道要删除的元素的值,可使用方法remove()。
motorcycles = ['honda','yamaha','suzuki','ducati']
motorcycles.remove('ducati')Python方法sort()让你能够较为轻松地对列表进行排序(按字母顺序升序排列)。方法sort()永久性地修改列表元素的排列顺序。
cars = ['bmw','audi','toyota','subaru']
cars.sort()
# ['audi','bmw','subaru','toyota']
print(cars)还可以按与字母顺序相反的顺序排列列表元素,只需向sort()方法传递参数reverse=True即可。
cars = ['bmw','audi','toyota','subaru']
cars.sort(reverse=True)
# ['toyota','subaru','bmw','audi']
print(cars)要保留列表元素原来的排列顺序,同时以特定的顺序呈现它们,可使用函数sorted()。函数sorted()让你能够按特定顺序显示列表元素,同时不影响它们在列表中的原始排列顺序。
注意,调用函数sorted()后,原始列表元素的排列顺序并没有变。如果要按与字母顺序相反的顺序显示列表,也可向函数sorted()传递参数reverse=True。
要反转列表元素的排列顺序,可使用方法reverse()。注意,reverse()不是按与字母顺序相反的顺序排列列表元素,而只是反转列表元素的排列顺序。方法reverse()永久性地修改列表元素的排列顺序,但可随时恢复到原来的排列顺序,只需对列表再次调用reverse()即可。
使用函数len()可快速获悉列表的长度。
cars = ['bmw','audi','toyota','subaru']
# 4
len(cars)索引错误的话会导致报错,比如下面这段代码:
motorcycles = ['honda','yamaha','suzuki']
print(motorcycles[3])会导致报错:
Traceback (most recent call last):
File "motorcycles.py",line 2,in <module>
print(motorcycles[3])
IndexError:list index out of range遍历列表,可以使用 for 语句。for语句末尾的冒号告诉Python,下一行是循环的第一行。如果不小心遗漏了冒号,将导致语法错误,因为Python不知道你意欲何为。
magicians = ['alice','david','carolina']
for magician in magicians:
print(magician)Python函数range()让你能够轻松地生成一系列数。例如,可以像下面这样使用函数range()来打印一系列数:
for value in range(1,5):
print(value)上述代码会输出1~4,不会输出5:
1
2
3
4调用函数range()时,也可只指定一个参数,这样它将从0开始。例如,range(6)返回数0~5。
要创建数字列表,可使用函数list()将range()的结果直接转换为列表。如果将range()作为list()的参数,输出将是一个数字列表。
numbers = list(range(1,6))
# [1,2,3,4,5]
print(numbers)使用函数range()时,还可指定步长。为此,可给这个函数指定第三个参数,Python将根据这个步长来生成数。
even_numbers = list(range(2,11,2))
# [2,4,6,8,10]
print(even_numbers)使用函数range()几乎能够创建任何需要的数集。例如,如何创建一个列表,其中包含前10个整数(1~10)的平方呢?在Python中,用两个星号(**)表示乘方运算。下面的代码演示了如何将前10个整数的平方加入一个列表中:
squares = []
for value in range(1,11):
squares.append(value ** 2)
# [1,4,9,16,25,36,49,64,81,100]
print(squares)有几个专门用于处理数字列表的Python函数。例如,你可以轻松地找出数字列表的最大值、最小值和总和:
digits = [1,2,3,4,5,6,7,8,9,0]
# 0
min(digits)
# 9
max(digits)
# 45
sum(digits)前面介绍的生成列表squares的方式包含三四行代码,而列表解析让你只需编写一行代码就能生成这样的列表。列表解析将for循环和创建新元素的代码合并成一行,并自动附加新元素。
# 请注意,这里的for语句末尾没有冒号。
squares = [value**2 for value in range(1,11)]
# [1,4,9,16,25,36,49,64,81,100]
print(squares)除了处理整个列表,你还可以处理列表的部分元素,Python称之为切片。
要创建切片,可指定要使用的第一个元素和最后一个元素的索引。与函数range()一样,Python在到达第二个索引之前的元素后停止。
players = ['charles','martina','michael','florence','eli']
# ['charles','martina','michael']
print(players[0:3])如果没有指定第一个索引,Python将自动从列表开头开始:
players = ['charles','martina','michael','florence','eli']
# ['charles','martina','michael','florence']
print(players[:4])要让切片终止于列表末尾,也可使用类似的语法。例如,如果要提取从第三个元素到列表末尾的所有元素,可将起始索引指定为2,并省略终止索引:
players = ['charles','martina','michael','florence','eli']
# ['michael','florence','eli']
print(players[2:])前面说过,负数索引返回离列表末尾相应距离的元素,因此你可以输出列表末尾的任意切片。例如,如果要输出名单上的最后三名队员,可使用切片players[-3:]:
players = ['charles','martina','michael','florence','eli']
print(players[-3:])注意
注意:可在表示切片的方括号内指定第三个值。这个值告诉Python在指定范围内每隔多少元素提取一个。
遍历切片:
players = ['charles','martina','michael','florence','eli']
print("Here are the first three players on my team:")
for player in players[:3]:
print(player.title())打印内容如下:
Here are the first three players on my team:
Charles
Martina
Michael要复制列表,可创建一个包含整个列表的切片,方法是同时省略起始索引和终止索引([:])。
元组
Python将不能修改的值称为不可变的,而不可变的列表被称为元组。元组看起来很像列表,但使用圆括号而非中括号来标识。定义元组后,就可使用索引来访问其元素,就像访问列表元素一样。
注意:严格地说,元组是由逗号标识的,圆括号只是让元组看起来更整洁、更清晰。如果你要定义只包含一个元素的元组,必须在这个元素后面加上逗号:
my_t = (3,)遍历元组中的所有值:
dimensions = (200,50)
for dimension in dimensions:
print(dimension)相比于列表,元组是更简单的数据结构。如果需要存储的一组值在程序的整个生命周期内都不变,就可以使用元组。
if
cars = ['audi','bmw','subaru','toyota']
for car in cars:
if car == 'bmw':
print(car.upper())
else:
print(car.title())要检查是否两个条件都为True,可使用关键字and将两个条件测试合而为一。
关键字or也能够让你检查多个条件,但只要至少一个条件满足,就能通过整个测试。仅当两个测试都没有通过时,使用or的表达式才为False。
要判断特定的值是否已包含在列表中,可使用关键字in。
requested_toppings = ['mushrooms','onions','pineapple']
# True
'mushrooms'in requested_toppings
# False
'pepperoni'in requested_toppings还有些时候,确定特定的值未包含在列表中很重要。在这种情况下,可使用关键字not in。
banned_users = ['andrew','carolina','david']
user = 'marie'
if user not in banned_users:
print(f"{user.title()},you can post a response if you wish.")布尔表达式:
game_active = True
can_edit = False最简单的if语句只有一个测试和一个操作:
if conditional_test:
do somethingif-else语句:
age = 17
if age >= 18:
print("You are old enough to vote!")
print("Have you registered to vote yet?")
else:
print("Sorry,you are too young to vote.")
print("Please register to vote as soon as you turn 18!")requested_toppings = ['mushrooms','green peppers','extra cheese']
for requested_topping in requested_toppings:
if requested_topping == 'green peppers':
print("Sorry,we are out of green peppers right now.")
else:
print(f"Adding {requested_topping}.")
print("\nFinished making your pizza!")if-elif-else结构:
age = 12
if age <4:
print("Your admission cost is $0.")
elif age <18:
print("Your admission cost is $25.")
else:
print("Your admission cost is $40.")age = 12
if age <4:
price = 0
elif age <18:
price = 25
elif age <65:
price = 40
else:
price = 20
print(f"Your admission cost is ${price}.")else 代码块是可以省略的:
age = 12
if age <4:
price = 0
elif age <18:
price = 25
elif age <65:
price = 40
elif age >= 65:
price = 20
print(f"Your admission cost is ${price}.")在if语句中将列表名用作条件表达式时,Python将在列表至少包含一个元素时返回True,并在列表为空时返回False(这点和JavaScript中的空数组的布尔值判断逻辑不一样)。
遍历键值对:
user = {
'username': 'efermi',
}
for key,value in user.items():
print(f"\nkey: {key}")
print(f"Value: {value}")遍历键:
# .keys() 是可以省略的,默认就是遍历所有键
for name in fvorite_languages.keys():
print(name.title())遍历值:
for language in favorite_languages.values():
print(language.title())
# 对值进行去重后再遍历
for language in set(favorate_languages.values):
print(language.title())字典
在Python中,字典是一系列键值对。每个键都与一个值相关联,你可使用键来访问相关联的值。与键相关联的值可以是数、字符串、列表乃至字典。事实上,可将任何Python对象用作字典中的值。
在Python 3.7中,字典中元素的排列顺序与定义时相同。如果将字典打印出来或遍历其元素,将发现元素的排列顺序与添加顺序相同。
alien_0 = {'color':'green','points':5}对于字典中不再需要的信息,可使用del语句将相应的键值对彻底删除。使用del语句时,必须指定字典名和要删除的键。
alien_0 = {'color':'green','points':5}
print(alien_0)
del alien_0['points']
print(alien_0)使用放在方括号内的键从字典中获取感兴趣的值时,可能会引发问题:如果指定的键不存在就会出错。就字典而言,可使用方法get()在指定的键不存在时返回一个默认值,从而避免这样的错误。方法get()的第一个参数用于指定键,是必不可少的;第二个参数为指定的键不存在时要返回的值,是可选的。
alien_0 = {'color':'green','speed':'slow'}
point_value = alien_0.get('points','No point value assigned.')
print(point_value)遍历所有键值对:
user_0 = {
'username':'efermi',
'first':'enrico',
'last':'fermi',
}
for key,value in user_0.items():
print(f"\nKey:{key}")
print(f"Value:{value}")遍历字典中的所有键:
favorite_languages = {
'jen':'python',
'sarah':'c',
'edward':'ruby',
'phil':'python',
}
for name in favorite_languages.keys():
print(name.title())遍历字典时,会默认遍历所有的键。即 for name in favorite_languages: 等价于 for name in favorite_languages.keys():。显式地使用方法keys()可让代码更容易理解,你可以选择这样做,但是也可以省略它。
要以特定顺序返回元素,一种办法是在for循环中对返回的键进行排序。为此,可使用函数sorted()来获得按特定顺序排列的键列表的副本:
favorite_languages = {
'jen':'python',
'sarah':'c',
'edward':'ruby',
'phil':'python',
}
for name in sorted(favorite_languages.keys()):
print(f"{name.title()},thank you for taking the poll.")遍历字典中的所有值:
favorite_languages = {
'jen':'python',
'sarah':'c',
'edward':'ruby',
'phil':'python',
}
print("The following languages have been mentioned:")
for language in favorite_languages.values():
print(language.title())通过对包含重复元素的列表调用set(),可让Python找出列表中独一无二的元素,并使用这些元素来创建一个集合。
favorite_languages = {
--snip--
}
print("The following languages have been mentioned:")
for language in set(favorite_languages.values()):
print(language.title())可使用一对花括号直接创建集合,并在其中用逗号分隔元素:
languages = {'python','ruby','python','c'}
# {'ruby','python','c'}
languages用户输入和while循环
函数input()让程序暂停运行,等待用户输入一些文本。获取用户输入后,Python将其赋给一个变量,以方便你使用。
message = input("Tell me something,and I will repeat it back to you:")
print(message)函数input()接受一个参数——要向用户显示的提示(prompt)或说明,让用户知道该如何做。在本例中,Python运行第一行代码时,用户将看到提示Tell me something,and I will repeat it back to you:。程序等待用户输入,并在用户按回车键后继续运行。输入被赋给变量message,接下来的print(message)将输入呈现给用户。
函数int()将数的字符串表示转换为数值表示,如下所示:
age = input("How old are you?")
# How old are you?21
age = int(age)
# True
age >= 18prompt = "\nTell me something,and I will repeat it back to you:"
prompt += "\nEnter 'quit'to end the program."
message = ""
while message != 'quit':
message = input(prompt)
print(message)删除为特定值的所有列表元素:
pets = ['dog','cat','dog','goldfish','cat','rabbit','cat']
print(pets)
while 'cat'in pets:
pets.remove('cat')
print(pets)函数
有时候,预先不知道函数需要接受多少个实参,好在Python允许函数从调用语句中收集任意数量的实参。例如,来看一个制作比萨的函数,它需要接受很多配料,但无法预先确定顾客要多少种配料。下面的函数只有一个形参*toppings,但不管调用语句提供了多少实参,这个形参会将它们统统收入囊中:
def make_pizza(*toppings):
"""打印顾客点的所有配料。"""
print(toppings)
make_pizza('pepperoni')
make_pizza('mushrooms','green peppers','extra cheese')形参名*toppings中的星号让Python创建一个名为toppings的空元组,并将收到的所有值都封装到这个元组中。函数体内的函数调用print()通过生成输出,证明Python能够处理使用一个值来调用函数的情形,也能处理使用三个值来调用函数的情形。它以类似的方式处理不同的调用。注意,Python将实参封装到一个元组中,即便函数只收到一个值:
('pepperoni',)
('mushrooms','green peppers','extra cheese')如果要遍历其中的具体元素:
def make_pizza(*toppings):
"""概述要制作的比萨。"""
print("\nMaking a pizza with the following toppings:")
for topping in toppings:
print(f"- {topping}")
make_pizza('pepperoni')
make_pizza('mushrooms','green peppers','extra cheese')结合使用位置实参和任意数量实参:
def make_pizza(size,*toppings):
"""概述要制作的比萨。"""
print(f"\nMaking a {size}-inch pizza with the following toppings:")
for topping in toppings:
print(f"- {topping}")
make_pizza(16,'pepperoni')
make_pizza(12,'mushrooms','green peppers','extra cheese')*args
你经常会看到通用形参名*args,它也收集任意数量的位置实参。
使用任意数量的关键字实参:
def build_profile(first,last,**user_info):
"""创建一个字典,其中包含我们知道的有关用户的一切。"""
user_info['first_name'] = first
user_info['last_name'] = last
return user_info
user_profile = build_profile('albert','einstein',
location='princeton',
field='physics')
print(user_profile)上例得到内容如下:
{'location':'princeton','field':'physics',
'first_name':'albert','last_name':'einstein'}**kwargs
注意 你经常会看到形参名**kwargs,它用于收集任意数量的关键字实参。
import语句允许在当前运行的程序文件中使用模块中的代码。
假定现在有文件 pizza.py:
def make_pizza(size,*toppings):
"""概述要制作的比萨。"""
print(f"\nMaking a {size}-inch pizza with the following toppings:")
for topping in toppings:
print(f"- {topping}")导入整个模块(只需编写一条import语句并在其中指定模块名,就可在程序中使用该模块中的所有函数):
import pizza
pizza.make_pizza(16,'pepperoni')
pizza.make_pizza(12,'mushrooms','green peppers','extra cheese')还可以导入模块中的特定函数,这种导入方法的语法如下:
from module_name import function_name通过用逗号分隔函数名,可根据需要从模块中导入任意数量的函数:
from module_name import function_0,function_1,function_2使用 as 给函数指定别名:
from pizza import make_pizza as mp
mp(16,'pepperoni')
mp(12,'mushrooms','green peppers','extra cheese')使用as给模块指定别名:
import pizza as p
p.make_pizza(16,'pepperoni')
p.make_pizza(12,'mushrooms','green peppers','extra cheese')使用星号(*)运算符可让Python导入模块中的所有函数:
from pizza import *
make_pizza(16,'pepperoni')
make_pizza(12,'mushrooms','green peppers','extra cheese')给形参指定默认值时,等号两边不要有空格:
def function_name(parameter_0,parameter_1='default value')对于函数调用中的关键字实参,也应遵循这种约定:
function_name(value_0,parameter_1='value')简历与工作
本章主要讲一些求职技巧、心态辅导、对公司的选择。以及入职后在工作中的一些指导意见、职业路线规划等。
不好的简历
先看一些不好的简历。
投机简历
曾经看到过一份7年工作经验的高级前端工程师简历,在其自我评价中写道:
项目经验丰富,有XX、XX大型系统产品的前端负责人架构经验,也有谷歌、XX、XX、XX、XX多行业千万级订单项目的负责人管理经验,对于开发项目系统性流程能有效保障,从项目启动到开发完成到检验验收到项目收尾能清晰规范,并完成项目汇报工作。
读完后是什么感觉?是不是感觉这个简历内容很有投机的感觉,让人觉得不踏实。这里列举了一大堆知名公司,好像很厉害,但其实结合这份简历中的其他内容,明眼人一看就知道这段话实际的含义是:做了大量外包项目,而且每个项目的时间都不长。
这种简历,一般都是投机性质的。简历作者会往各个小公司投简历,碰到那种看不破的公司,就容易被忽悠。会被忽悠的公司,一般也没有足够的技术能力去面试其技术水平,就可能被其忽悠出一个较高的薪资。
该简历中类似的文案还有:
使用前端智能化工具gulp进行模块化开发。
内容虚构的简历
来看一位拥有4年工作经历的“百分比先生”的简历:
每次游戏活动能够准时上线,上线后用户体验良好,吸引了30%老玩家回归。
可视化配置的客服系统能够便捷按时开发完成,提高了50%的页面开发效率。
通过开发聚合SDK,将权限与路由统一处理,提高了前端50%的开发效率。
权限平台的开发,让运营人员将权限的操作进行了可视化,提高了70%的工作效率。
数字化平台的推广与接入各个事业部,提高了事业部20%的工作效率。
通过使用课件编辑器,让老师备课到选题进行在线编辑预览,提高了50%的备课效率。
课件编辑器的幻灯片在线播放,提高老师端与学生端20%的工作效率。
接入了试题库以及题目SDK的使用,提高了老师30%的工作效率。
官网上线后的体验极佳,吸引了20%的老玩家回归。
这是一份充斥着各种百分比数据的简历。 正常情况下,数字会让简历显得更有说服力,但这份简历成功地起到了反效果——看着太假了。 老玩家回归和官网上线按理关系并不大。而且所有百分比数字都是10的整数倍。 显然这些数字是简历作者自己凭感觉定的。
频繁换公司的简历
这是一个工作经验2年的简历中的内容节选:
工作经历:
- 上海XXXX科技有限公司(2021.08 - 2022.07)
- 杭州XXXX网络技术有限公司(2021.01 - 2021.06)
- 杭州XXXX开发有限公司(2020.09 - 2020.12)
这个简历中,每份工作经历都很短,最长的才一年左右。短短2年时间内换了3次工作。 这样的简历,就算内容让人觉得技术能力过关,也很难让人有意向去招聘这个人。 因为很可能这个人不适合团队协作,或者抗压能力低,总之就是招这个人风险很高。
什么是好的简历?
这是一份在线简历,简历地址:https://www.orzzone.com/cv。
为什么说这份简历好?因为是我自己的简历(误)。
首先从简历的使用上来说。这份简历完全是按A4纸格式撰写的,右上方也有打印功能,这一点就非常方便投简历的投递使用。另外,打印内容与页面在浏览器里显示的内容一致,这一点使得我们不需要额外调试打印出来的样式,可以直接根据页面在浏览器中呈现出来的样子决定是否需要对某些内容进行调整。
其次,从简历的可读性上来看。这份简历重点突出,重点关键词用了加黑效果,部分还加大字号显示。另外,这份简历用了不少图片,能有效提高看了一天简历的面试官的兴趣。
再次,从摆事实的角度来看看。很多简历里都只有干巴巴的描述文案,我们这份简历里使用了不少数据。而且一看就是计算出来的数据。但是现在简历造假的人太多了,如果有人怀疑简历中数据的真实性质,可以直接让他们去背调即可。
最后,简历的内容才是核心。排版样式和技巧都是辅助的,简历最核心的还是求职者自身的能力展现,如果自身能力不行,再多的技巧也于事无补。所以大家在平时工作中要注意自我提升,编码时多带着些思考。争取一些有意义的或者偏技术性质的kpi来做是很好的一种途径,既提高了在现任公司中的影响力,也对简历的内容撰写有了不少的帮助。
面试准备
备战面试,应该从4个方向进行准备:
- 日常知识体系的搭建:包括各种渠道获取到的知识,比如书籍、视频、文章。
- 日常项目经验的积累:包括公司项目和个人项目。
- 网上面试题的积累。
- 针对自己的简历有重点的去准备对应知识。
知识的总结可以通过画思维导图或者记笔记(比如写这本书)的方式进行,方便日后回顾。
但是日常知识体系的搭建和项目经验的积累是靠平日里一点一滴积累起来的,有很多经验性的东西, 靠看面试题之类的是很难积累起来的,比如代码重构相关的经验、对工程化项目代码的理解等。
新人或者一直做小项目或者一直在做大项目里某个子模块的开发可能会觉得所有能封装的东西都封装起来比较好,这样修改相关需求时往往可以事半功倍。
但是经常在大项目里跨模块开发的人可能就会觉得除非非常通用的东西,很多是不用封装的, 一来经常跨模块开发意味着对很多模块的熟悉度都有限,容易出现改一个地方多个页面出错的问题, 测试的时候因为不是需求相关页面所以根本没测,就变成产线问题了,而当一个组件被很多业务里用到时,如果没有人精心维护这种组件, 这个组件内部的代码很容易变得非常丑陋,到最后没法轻易地知道要传什么属性给这个组件。
你说这两种想法有孰优孰劣吗,我觉得是没有的,这个事情就是要看项目体量,体量小时容错率高(比如不容易漏测试,更大概率用户量小), 项目的学习/熟悉成本也低,业务复杂度低,这种情况下我觉得就是要尽量封装。 但是体量大了我就不建议尽量封装了,体量大了容错率低,而且对工程项目来说,可维护性才是最重要的。
当然凡事不绝对,比如虽然是个大项目,但是有很多开发参与,每个人又主要各自维护其中个别几个模块,那其实就是多个小项目的情况了,也就适合封装了(小模块内封装模块自己用的,非常通用的封装到外面)。
写在最后
这本书其实也帮不了你什么,主要是辅助梳理下知识体系。学习,终归是要靠自己的。自助者,天助之。
这是我很喜欢的一篇网络译文,放在最后,与君共勉。
《我的心曾悲伤七次》——卡里·纪伯伦
第一次,当它本可进取时,却故作谦卑;
第二次,当它在空虚时,用爱欲来填充;
第三次,在困难和容易之间,它选择了容易;
第四次,它犯了错,却借由别人也会犯错来宽慰自己;
第五次,它自由软弱,却把它认为是生命的坚韧;
第六次,当它鄙夷一张丑恶的嘴脸时,却不知那正是自己面具中的一副;
第七次,它侧身于生活的污泥中,虽不甘心,却又畏首畏尾。
附录1:参考文档
参考的书籍:
- 张文亮《MySQL 8.0从入门到实战》,或者说是参考了MySQL 8.0 Reference Manual,比如26.2.7 How MySQL Partitioning Handles NULL
- 《Python编程:从入门到实践(第2版)》:袁国忠译,作者[美]埃里克·马瑟斯,ISBN:9787115546081。
参考的文章:
- AST反混淆之路——babel基本知识及常用转换操作
- 面试官的步步紧逼:Vue2 和 Vue3 的响应式原理比对
- 有效的括号
- Algorithms for Interview 2: Monotonic Stack
- 单调栈
- 由浅入深,单调栈思路去除重复字符
- 二叉树的非递归遍历
- 详解Vue双向数据绑定原理解析
- JavaScript设计模式之观察者模式
- 设计模式简介
- JavaScript 单例模式
- Babel是如何编译let和const?
- 简书 - 创作你的创作
- Web Performance | MDN
- Performance.timing
- Using the Resource Timing API
- Navigation Timing API
- 数字数组奇排序问题
- 二维数组旋转的方法
- 手写Promise - 实现一个基础的Promise
- 前端打包如何在减少请求数与利用并行下载之间找到最优解?
- Promise和setTimeout执行顺序
- js执行机制(promise,setTimeout执行顺序)
- JS为什么要区分微任务和宏任务?
- JavaScript为什么要区分微任务和宏任务
- JS闭包与内存泄漏
- Object.create()
- TCP的特性
- 前端面试整理 -- HTTP篇
- HTTP状态码及缓存控制
- 304 Not Modified
- Safe
- Mixed content
- 9. REST Design Guidelines
- Event.stopImmediatePropagation
- Example 5: Event Propagation
- stopPropagation vs. stopImmediatePropagation
- Event.srcElement
- Event.currentTarget
- Event.target
- vue通信方法EventBus的实现
- JavaScript设计模式之观察者模式
- react基本原理及性能优化
- 深入浅出Redux原理
- useState 的原理及模拟实现 —— React Hooks 系列(一)
- 一文读懂js中的new关键字
附录2:致谢
感谢以下通过参与到本书的编写工作中来。